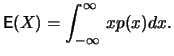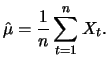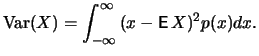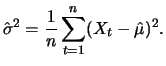The mathematical expectation or the mean
![$ \mathop{\text{\rm\sf E}}[X]$](sfehtmlimg47.gif) of a
real random variable
of a
real random variable 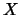 is a measure for the location of the
distribution of . Adding to a real constant
is a measure for the location of the
distribution of . Adding to a real constant 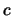 , it holds
for the expectation:
, it holds
for the expectation:
![$ \mathop{\text{\rm\sf E}}[X+c] = \mathop{\text{\rm\sf E}}[X] + c$](sfehtmlimg403.gif) , i.e. the location
of the distribution is translated. If has a density
, i.e. the location
of the distribution is translated. If has a density 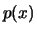 ,
its expectation is defined as:
If the integral does not exist, neither does the expectation. In
practice, this is rather rarely the case.
,
its expectation is defined as:
If the integral does not exist, neither does the expectation. In
practice, this is rather rarely the case.
Let
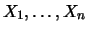 be a sample of identically independently
distributed (i.i.d.) random variables (see Section 3.4)
having the same distribution as , then
can be estimated
by means of the sample mean:
be a sample of identically independently
distributed (i.i.d.) random variables (see Section 3.4)
having the same distribution as , then
can be estimated
by means of the sample mean:
A measure for the dispersion of a random variable around its
mean is given by the variance
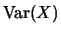 :
:
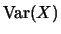 |
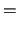 |
![$\displaystyle \mathop{\text{\rm\sf E}}[(X - \mathop{\text{\rm\sf E}}X)^2]$](sfehtmlimg410.gif) |
|
| Variance |
|
mean squarred deviation of a random variable |
|
| |
 |
around its expectation. |
|
If has a density , its variance can be computed as
follows:
The integral can be infinite. There are empirical studies giving
rise to doubt that some random variables appearing in financial
and actuarial mathematics and which model losses in highly risky
businesses dispose of a finite variance.
As a quadratic quantity the variance's unity is different from
that of itself. It is better to use the standard deviation of
which is measured in the same unity as :
Given a sample of i.i.d. variables
which have the
same distribution as , the sample variance can be estimated
by:
A
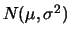 distributed random variable has mean
distributed random variable has mean
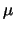 and variance
and variance 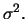 The
The 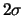 area around
contains with probability of a little more than 95% observations
of :
A lognormally distributed random variable with parameters
and
area around
contains with probability of a little more than 95% observations
of :
A lognormally distributed random variable with parameters
and 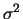 has mean and variance
A
has mean and variance
A 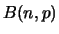 distributed variable has mean
distributed variable has mean 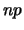 and variance
and variance
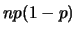 . The approximation (3.1) is chosen such that the
binomial and normal distribution have identical mean and variance.
. The approximation (3.1) is chosen such that the
binomial and normal distribution have identical mean and variance.