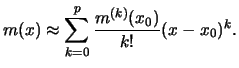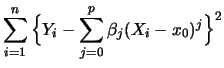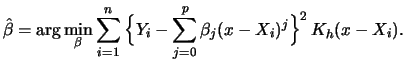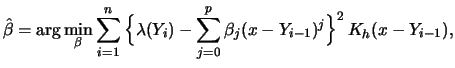In this section we introduce several basic terms and ideas from the theory of nonparametric regressions and explain in particular the method of local polynomial regression. To conclude we explain how this can be applied to (financial) time series. A detailed representation can be found in Härdle et al. (2004).
In nonparametric regression one is interested in the (functional)
relationship between an explanatory variable ![]() and a dependent
variable
and a dependent
variable ![]() , i.e., one is interested in obtaining an estimation
for the unknown function
, i.e., one is interested in obtaining an estimation
for the unknown function
![]() . In doing
this, in contrast to parametric statistics, no special assumptions
on the form of the function
. In doing
this, in contrast to parametric statistics, no special assumptions
on the form of the function ![]() is made. Only certain regularity
and smoothing assumptions are made about
is made. Only certain regularity
and smoothing assumptions are made about ![]() .
.
One way to estimate ![]() is to use the method of local polynomial
regression (LP Method). The idea is based on the fact that the
function
is to use the method of local polynomial
regression (LP Method). The idea is based on the fact that the
function ![]() can be locally approximated with a Taylor polynomial,
i.e., in a neighborhood around a given point
can be locally approximated with a Taylor polynomial,
i.e., in a neighborhood around a given point ![]() it holds that
it holds that
One of the classical methods for localization is based on
weighting the data with the help of a kernel. A kernel is a
function
![]() with
with
![]() . The most useful kernels are also symmetric and disappear
outside of a suitable interval around the zero point.
. The most useful kernels are also symmetric and disappear
outside of a suitable interval around the zero point.
If ![]() is a kernel and
is a kernel and ![]() , then the kernel
, then the kernel ![]()
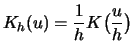
With the representation
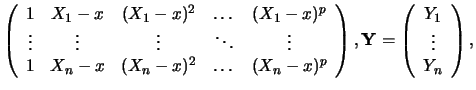 |
|||
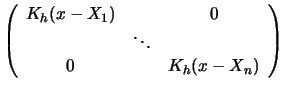 |
| (14.5) |
The estimation
![]() for
for ![]() can be obtained
only by calculating the approximating polynomial at
can be obtained
only by calculating the approximating polynomial at ![]() :
:
| (14.6) |
The remaining components of
![]() , due to equations
(13.2) and (13.3) deliver estimators for the
derivatives of
, due to equations
(13.2) and (13.3) deliver estimators for the
derivatives of ![]() :
:
![]() , which will not be discussed in further detail here.
In the special case where
, which will not be discussed in further detail here.
In the special case where ![]() ,
,
![]() is a typical kernel
estimator of Nadaraya-Watson type, see Härdle (1990).
is a typical kernel
estimator of Nadaraya-Watson type, see Härdle (1990).
The similarly derived method of local polynomial approximation, or
LP method for short, will now be applied to a
time series ![]() . As mentioned before, one is most interested
in creating forecasts.
. As mentioned before, one is most interested
in creating forecasts.
For the simplest case a one-step-ahead forecast means that the
functional relationship between ![]() and a function
and a function
![]() of
of ![]() will be analyzed, i.e., we want to obtain
an estimate for the unknown function
will be analyzed, i.e., we want to obtain
an estimate for the unknown function