The practical usefulness of any estimation technique is determined, besides other factors, by its invariance and robustness properties, because they are essential for coherent interpretation of regression results. Although some of these properties are often perceived as granted (probably because of their validity in the case of the least squares regression), it does not have to be the case for more evolved regression procedures. Fortunately, quantile regression preserves many of these invariance properties, and even adds to them several other distinctive qualities, which we are going to discuss now.
In many situations it is preferable to adjust the scale of original variables
or reparametrize a model so that its result has a more natural
interpretation. Such changes should not affect our qualitative and
quantitative conclusions based on the regression output.
Invariance to a set of some elementary transformations
of the model is called equivariance in this context.
Koenker and Bassett (1978) formulated four equivariance properties of
quantile regression.
Once we denote the quantile regression estimate for a given
![]() and observations
and observations ![]() by
by
![]() ,
then for any
,
then for any
![]() nonsingular matrix
nonsingular matrix
![]() , and
, and ![]() holds
holds
Quantiles exhibit besides ``usual'' equivariance properties also equivariance to
monotone transformations. Let ![]() be a nondecreasing function
on
be a nondecreasing function
on
![]() --then it immediately follows from the definition of
the quantile function that for any random variable
--then it immediately follows from the definition of
the quantile function that for any random variable ![]()
We can illustrate the strength of equivariance with respect to monotone transformation on the so-called censoring models. We assume that there exists, for example, a simple linear regression model with i.i.d. errors
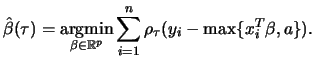
Sensitivity of an estimator to departures from its distributional
assumptions is another important issue. The
long discussion concerning relative qualities of the mean and median is
an example of how significant this kind of robustness (or sensitivity)
can be. The sample mean, being a superior estimate of the expectation
under the normality of the error distribution, can be adversely affected
even by a single observation if it is sufficiently far from the rest
of data points. On the other hand, the effect of such a distant observation
on the sample median is bounded no matter how far the outlying
observation is. This robustness of the median is, of course,
outweighed by lower efficiency in some cases. Other quantiles
enjoy similar properties--the effect of outlying observations on
the ![]() -th sample quantile is bounded, given that the
number of outliers is lower than
-th sample quantile is bounded, given that the
number of outliers is lower than
![]() .
.
Quantile regression inherits these robustness properties since the minimized
objective functions in the case of sample quantiles (1.5) and in the
case of quantile regression (1.7) are the same. The only difference
is that regression residuals
![]() are used instead of
deviations from mean
are used instead of
deviations from mean ![]() . Therefore, quantile regression estimates are
reliable in presence of outlying observations that have large residuals.
To illustrate this property, let us use a set of ten simulated pseudo-random
data points to which one outlying observations is added
(the complete code of this example is stored in
. Therefore, quantile regression estimates are
reliable in presence of outlying observations that have large residuals.
To illustrate this property, let us use a set of ten simulated pseudo-random
data points to which one outlying observations is added
(the complete code of this example is stored in
![]() XAGqr04.xpl
).
XAGqr04.xpl
).
outlier = #(0.9,4.5) ; outlying observation ; ; data initialization ; randomize(17654321) ; sets random seed n = 10 ; number of observations beta = #(1, 2) ; intercept and slope x = matrix(n)~uniform(n) ; randomly generated data x = sort(x) x = x | (1~outlier[1]) ; add outlier ; ; generate regression line and noisy response variable ; regline = x * beta y = regline[1:n] + 0.05 * normal(n) y = y | outlier[2] ; add outlier
z = rqfit(x,y,0.5) ; estimation betahat = z.coefs ; ; create graphical display, draw data points and regressions line ; d = createdisplay(1,1) data = x[,2]~y ; data points outl = outlier[1]~outlier[2] ; outlier setmaskp(outl,1,12,15) ; is blue big star ; line = x[,2]~regline ; true regression line setmaskp(line, 0, 0, 0) setmaskl(line, (1:rows(line))', 1, 1, 1) ; yhat = x * betahat qrline = x[,2]~yhat ; estimated regression line setmaskp(qrline, 0, 0, 0) setmaskl(qrline, (1:rows(qrline))', 4, 1, 3) ; ; display all objects ; show(d, 1, 1, data[1:n], outl, line, qrline) setgopt(d, 1, 1, "title", "Quantile regression with outlier")
As a result, you should see a graph like one on Figure 1.2, in which observations are denoted by black circles and the outlier is represented by the big blue star in the right upper corner of the graph. Further, the blue line depicts the true regression line, while the thick red line shows the estimated regression line.
As you may have noticed, we mentioned the robustness of quantile regression with respect to observations that are far in the direction of the dependent variable, i.e., that have large residuals. Unfortunately, this cannot be said about the effect of observations that are distant in the space of explanatory variables--a single point dragged far enough toward infinity can cause that all quantile regression hyperplanes go through it. As an example, let us consider the previous data set with a different outlier:
outlier = #(3,2)Running example
![\includegraphics[scale=0.6]{qr04}](xaghtmlimg151.gif)
![\includegraphics[scale=0.6]{qr05}](xaghtmlimg152.gif)