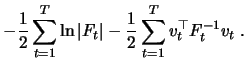Given the above SSF and all unknown parameters
![]() , we can use Kalman filter
techniques to estimate the unknown coefficients
, we can use Kalman filter
techniques to estimate the unknown coefficients ![]() and the process of
and the process of ![]() .
The Kalman filter technique is an algorithm for estimating the unobservable state vectors
by calculating its expectation conditional on information up to
.
The Kalman filter technique is an algorithm for estimating the unobservable state vectors
by calculating its expectation conditional on information up to
![]() . In the
ongoing, we use the following general notation:
. In the
ongoing, we use the following general notation:
denotes the covariance matrix of the estimation error and
![]() is a shorthand for the information available at time
is a shorthand for the information available at time ![]() .
.
Generally, the estimators delivered by Kalman filtering techniques have minimum
mean-squared error among all linear estimators (Shumway and Stoffer; 2000, Chapter 4.2). If
the initial state vector, the noise
![]() and
and
![]() are multivariate
Gaussian, then the Kalman filter delivers the optimal estimator among all estimators,
linear and nonlinear (Hamilton; 1994, Chapter 13).
are multivariate
Gaussian, then the Kalman filter delivers the optimal estimator among all estimators,
linear and nonlinear (Hamilton; 1994, Chapter 13).
The Kalman filter techniques can handle missing observations in the measurement equation
(13.3b). For periods with less than ![]() observations, one has to adjust
the measurement equations. One can do this by just deleting all elements of the
measurement matrices
observations, one has to adjust
the measurement equations. One can do this by just deleting all elements of the
measurement matrices ![]() ,
, ![]() ,
, ![]() for which the corresponding entry in
for which the corresponding entry in ![]() is a
missing value. The quantlets in
XploRe
use this procedure. Another way to take missing
values into account is proposed by Shumway and Stoffer
(2000,1982): replace all missing values with zeros and
adjust the other measurement matrices accordingly. We show in Appendix
13.6.1 that both methods deliver the same results. For periods with no
observations the Kalman filter techniques recursively calculate an estimate given recent
information (Durbin and Koopman; 2001).
is a
missing value. The quantlets in
XploRe
use this procedure. Another way to take missing
values into account is proposed by Shumway and Stoffer
(2000,1982): replace all missing values with zeros and
adjust the other measurement matrices accordingly. We show in Appendix
13.6.1 that both methods deliver the same results. For periods with no
observations the Kalman filter techniques recursively calculate an estimate given recent
information (Durbin and Koopman; 2001).
The Kalman filter is an algorithm for sequently updating our knowledge of the
system given a new observation ![]() . It calculates one step predictions conditional on
. It calculates one step predictions conditional on
![]() . Using our general expressions, we have
. Using our general expressions, we have
![$\displaystyle \begin{equation*}a_t= \textrm{E}[\alpha_t\vert\mathcal{F}_t] \end...
...rm{E}[(\alpha_t-a_t) (\alpha_t-a_t)^\top \vert\mathcal{F}_t]\;. \end{equation*}$](xfghtmlimg2303.gif) |
Here we use the standard simplified notation ![]() and
and ![]() for
for ![]() and
and ![]() .
As a by-product of the filter, the recursions calculate also
.
As a by-product of the filter, the recursions calculate also
![$\displaystyle \begin{equation*}a_{t\vert t-1}= \textrm{E}[\alpha_t\vert\mathcal...
...t-1}) (\alpha_t-a_{t\vert t-1})^\top \vert\mathcal{F}_{t-1}]\;. \end{equation*}$](xfghtmlimg2307.gif) |
We give the filter recursions in detail in Subsection 13.5.3.
The Kalman smoother is an algorithm to predict the state vector ![]() given
the whole information up to
given
the whole information up to ![]() . Thus we have with our general notation
. Thus we have with our general notation ![]() and
and
![$\displaystyle \begin{equation*}a_{t\vert T}=\textrm{E}[\alpha_t\vert\mathcal{F}...
...{t\vert T}) (\alpha_t-a_{t\vert T})^\top \vert\mathcal{F}_T]\;. \end{equation*}$](xfghtmlimg2309.gif) |
We see that the filter makes one step predictions given the information up to
![]() whereas the smoother is backward looking. We give the smoother
recursions in detail in Subsection 13.5.5.
whereas the smoother is backward looking. We give the smoother
recursions in detail in Subsection 13.5.5.
Given the system matrices ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , Kalman filtering
techniques are the right tool to estimate the elements of the state vector. However, in
our model some of these system matrices contain unknown parameters
, Kalman filtering
techniques are the right tool to estimate the elements of the state vector. However, in
our model some of these system matrices contain unknown parameters ![]() . These
parameters have to be estimated by maximum likelihood.
. These
parameters have to be estimated by maximum likelihood.
Given a multivariate Gaussian error distribution, the value of the log likelihood
function ![]() for a general SSF is up to an additive constant equal to:
for a general SSF is up to an additive constant equal to:
Here,
are the innovations of the filtering procedure and ![]() is the conditional
expectation of
is the conditional
expectation of ![]() given information up to
given information up to ![]() . As we have already mentioned,
these expressions are a by-product of the filter recursions. The matrix
. As we have already mentioned,
these expressions are a by-product of the filter recursions. The matrix ![]() is the
covariance matrix of the innovations at time
is the
covariance matrix of the innovations at time ![]() and also a by-product of the Kalman
filter. The above log likelihood is known as the prediction error decomposition
form (Harvey; 1989). Periods with no observations do not contribute to the log
likelihood function.
and also a by-product of the Kalman
filter. The above log likelihood is known as the prediction error decomposition
form (Harvey; 1989). Periods with no observations do not contribute to the log
likelihood function.
Starting with some initial value, one can use numerical maximization methods to obtain an
estimate of the parameter vector ![]() . Under certain regularity conditions, the maximum
likelihood estimator
. Under certain regularity conditions, the maximum
likelihood estimator
![]() is consistent and asymptotically normal. One can use
the information matrix to calculate standard errors of
is consistent and asymptotically normal. One can use
the information matrix to calculate standard errors of
![]() (Hamilton; 1994).
(Hamilton; 1994).
After fitting a SSF, one should check the appropriateness of the results by looking at the standardized residuals
If all parameters of the SSF were known, ![]() would follow a multivariate
standardized normal distribution (Harvey; 1989, see also (13.9)). We
know that
would follow a multivariate
standardized normal distribution (Harvey; 1989, see also (13.9)). We
know that ![]() is a symmetric matrix and that it should be positive definite (recall
that it is just the covariance matrix of the innovations
is a symmetric matrix and that it should be positive definite (recall
that it is just the covariance matrix of the innovations ![]() ). So
). So
where the diagonal matrix ![]() contains all eigenvalues of
contains all eigenvalues of ![]() and
and ![]() is the
matrix of corresponding normalized eigenvectors (Greene; 2000, p.43). The standardized
residuals should be distributed normally with constant variance, and should show no
serial correlation. It is a signal for a misspecified model when the residuals do not
possess these properties. To check the properties, one can use standard test procedures.
For example, a Q-Q plot indicates if the quantiles of the residuals deviate from the
corresponding theoretical quantiles of a normal distribution. This plot can be used to
detect non-normality. The Jarque-Bera test for normality can also be used for testing
non-normality of the residuals (Bera and Jarque; 1982). This test is implemented in
XploRe
as
is the
matrix of corresponding normalized eigenvectors (Greene; 2000, p.43). The standardized
residuals should be distributed normally with constant variance, and should show no
serial correlation. It is a signal for a misspecified model when the residuals do not
possess these properties. To check the properties, one can use standard test procedures.
For example, a Q-Q plot indicates if the quantiles of the residuals deviate from the
corresponding theoretical quantiles of a normal distribution. This plot can be used to
detect non-normality. The Jarque-Bera test for normality can also be used for testing
non-normality of the residuals (Bera and Jarque; 1982). This test is implemented in
XploRe
as
 jarber
.
jarber
.
In the empirical part, we combine Kalman filter techniques and maximum likelihood to estimate the unknown parameters and coefficients of the SSF for the house prices in a district of Berlin.
![$\displaystyle \begin{equation}a_{t\vert s}\stackrel{\mathrm{def}}{=}\textrm{E}[...
...t-a_{t\vert s}) (\alpha_t-a_{t\vert s})^\top \vert\mathcal{F}_s] \end{equation}$](xfghtmlimg2298.gif)