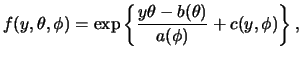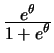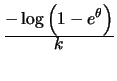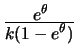It is known that the least squares estimator
![]() in the classical linear model coincides with the maximum-likelihood
estimator under the imposed normal distribution.
By using appropriate distributional assumptions for
in the classical linear model coincides with the maximum-likelihood
estimator under the imposed normal distribution.
By using appropriate distributional assumptions for ![]() in
GLM, one may stay in the framework of maximum-likelihood in this case.
in
GLM, one may stay in the framework of maximum-likelihood in this case.
For maximum-likelihood estimation, one assumes that the
distribution of ![]() belongs to
an exponential family. Exponential families cover a broad
range of distributions, for example discrete
as the Binomial and Poisson distribution or continuous as
the Gaussian (normal) and Gamma distribution.
belongs to
an exponential family. Exponential families cover a broad
range of distributions, for example discrete
as the Binomial and Poisson distribution or continuous as
the Gaussian (normal) and Gamma distribution.
A distribution is said to belong to an exponential family
if its probability function (if ![]() discrete) or its density
function (if
discrete) or its density
function (if ![]() continuous) has the structure
continuous) has the structure
Generally speaking, we are interested in estimating
![]() , the canonical parameter.
, the canonical parameter.
![]() is a nuisance parameter
(as the variance
is a nuisance parameter
(as the variance ![]() in linear regression for example).
Apart from the distribution of
in linear regression for example).
Apart from the distribution of ![]() , the link function is another
essential part of the generalized linear model. Recall the notations
, the link function is another
essential part of the generalized linear model. Recall the notations
All models in the glm library are estimated by maximum-likelihood. The default numerical algorithm is the Newton-Raphson iteration (except for ordinary regression where no iteration is necessary). Optionally, a Fisher Scoring can be chosen, which uses the expectation of the Hessian matrix instead of the Hessian itself. In the case of a canonical link function, the Newton-Raphson algorithm and the Fisher scoring algorithm coincide.