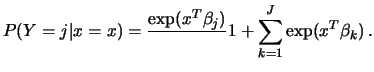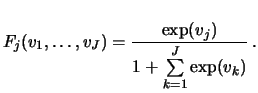The single index model of the previous sections has been extended to
multiple index models in various ways. For instance, popular
parametric models for data with multicategorical response variables
(representing the choice of individuals among more than two
alternatives) are of the multi-index form.
In the Multinomial Logit model, the probability that an
individual will choose alternative ![]() depends on characteristics
depends on characteristics ![]() of the individual through the indices
of the individual through the indices
![]()
|
A semiparametric multiple index model is the
(SIR) model considered in Li (1991).
Given a response variable ![]() and a (random) vector
and a (random) vector
![]() of
explanatory variables, SIR is based on the model:
of
explanatory variables, SIR is based on the model:
Model (12.14) describes the situation where the response
variable ![]() depends on the
depends on the ![]() -dimensional variable
-dimensional variable ![]() only through
the indices
only through
the indices
![]() . The smaller
. The smaller ![]() is
relative to
is
relative to ![]() , the better able is SIR to represent the
, the better able is SIR to represent the ![]() -dimensional
regression of
-dimensional
regression of ![]() on
on ![]() by a parsimonious
by a parsimonious ![]() -dimensional
subspace. The unknown
-dimensional
subspace. The unknown
![]() which span this space,
are called effective dimension reduction
directions
(EDR directions). The span is referred to as the effective dimension
reduction space
(EDR space).
which span this space,
are called effective dimension reduction
directions
(EDR directions). The span is referred to as the effective dimension
reduction space
(EDR space).
SIR tries to find this ![]() -dimensional subspace of
-dimensional subspace of
![]() by considering the inverse regression (IR)
curve, i.e.
by considering the inverse regression (IR)
curve, i.e. ![]() Under some weak assumptions on the joint distribution of the elements
of
Under some weak assumptions on the joint distribution of the elements
of ![]() , it can be shown that
the centered inverse regression
, it can be shown that
the centered inverse regression
![]() lies in the subspace
formed by the
lies in the subspace
formed by the ![]() s. The
s. The ![]() s are found by an eigenvalue/eigenvector
decomposition of the estimated covariance matrix of the vector
s are found by an eigenvalue/eigenvector
decomposition of the estimated covariance matrix of the vector
![]() where
where ![]() is a standardized version of
is a standardized version of ![]() In
XploRe
, this is achieved by using the
In
XploRe
, this is achieved by using the
 sir
quantlet:
sir
quantlet:
{edr, eigen} = sir(x, y, h)
It takes as inputs the data (x and y) and the parameter
![]()
![]() is related to the ``slicing'' part of sliced inverse
regression. The algorithm actually works on nonoverlapping intervals (slices)
of the data. There are different ways to divide the data into slices
and the value of
is related to the ``slicing'' part of sliced inverse
regression. The algorithm actually works on nonoverlapping intervals (slices)
of the data. There are different ways to divide the data into slices
and the value of ![]() has to be set accordingly. Three cases are
distinguished:
has to be set accordingly. Three cases are
distinguished:
The outputs of
sir
are edr, the matrix containing estimates of
the effective dimension reduction directions (i.e. the
![]() s)
and the eigenvalues of the estimated covariance matrix of the vector
s)
and the eigenvalues of the estimated covariance matrix of the vector
![]()
![]()
sir2
provides an alternative to
sir
. Usage of
sir2
is very similar to
sir
but the details of the algorithm as
well as the underlying theory are different.
For further details on SIR II, see Li (1991).
Parametric multiple index models like the multinomial logit model (12.13) are based on rather strong functional form assumptions. If these assumptions are not valid, then maximum-likelihood estimators of the parameters of these models are inconsistent.
XploRe provides a procedure to test the functional form assumptions of parametric multiple index models:
|
The function
hhmult
is a generalization of the HH-test from
Subsection 12.1.7. See Werwatz (1997) for details.
hhmult
can only be applied for models with a multicategorical
dependent variable. The
null hypothesis corresponds to a parametric model such as the multinomial
logit model (12.13). You first have to estimate this model (in the case
of the multinomial logit model you can use
glmmultlo
) and save the
estimated indices in the matrix vhat and the predicted probabilities in
the matrix yhat. Along with vhat and yhat, you provide the
observations on the dependent variable and a vector of bandwidths h.
hhmult
expects that you convert the observations on the multicategorical
dependent variable into a set of dummy variables, one dummy variable per
category of ![]() The bandwidths are used for the nonparametric regressions of
the dummy dependent variables on the estimated indices vhat. These
nonparametric regressions provide an estimate of the parametric link functions,
which take the following form in the multinomial logit model:
The bandwidths are used for the nonparametric regressions of
the dummy dependent variables on the estimated indices vhat. These
nonparametric regressions provide an estimate of the parametric link functions,
which take the following form in the multinomial logit model:
All these differences are summarized into one test statistic which,
asymptotically, follows a ![]() distribution.
hhmult
returns the
value of the test statistic as well as the associated
distribution.
hhmult
returns the
value of the test statistic as well as the associated ![]() -value.
-value.