More precisely, let
![]() be arbitrary measurable
mean zero functions of the corresponding random variables.
The fraction of variance not explained by a regression of
be arbitrary measurable
mean zero functions of the corresponding random variables.
The fraction of variance not explained by a regression of
![]() on
on
![]() is
is
For the bivariate case (![]() ) the optimal transformations
) the optimal transformations ![]() and
and ![]() satisfy
satisfy
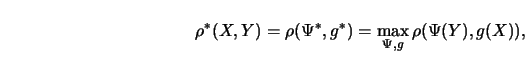
Suppose that the data are generated by the regression model

To illustrate the ACE algorithm consider first the bivariate case:
SET
![]()
REPEAT
![]()
Replace ![]() with
with ![]()
![]()
Replace ![]() with
with ![]()
UNTIL ![]() fails to decrease.
fails to decrease.
The more general case of multiple predictors can be treated
in direct analogy with the basic ACE algorithm.
For a given set of functions
![]() minimization
of 10.3.5, with respect to
minimization
of 10.3.5, with respect to ![]() , holding
, holding
![]() , yields
, yields
![\begin{displaymath}\Psi_1(Y) = E\left[ \sum_{j=1}^d g_j(X_j) \vert Y\right]
\big...
...t\Vert E\left[ \sum_{j=1}^d g_j(X_j)\vert Y\right] \right\Vert.\end{displaymath}](anrhtmlimg2702.gif)
SET
![]() and
and
![]()
REPEAT
REPEAT
FOR ![]() TO
TO ![]() DO BEGIN
DO BEGIN
![]()
![]()
END;
UNTIL
![]() fails to
decrease;
fails to
decrease;
![]()
![]()
UNTIL
![]() fails to decrease.
fails to decrease.
In practice, one has to use smoothers to estimate the involved
conditional expectations. Use of a fully
automatic smoothing procedure, such as the supersmoother, is
recommended. Figure
10.9 shows a three-dimensional data set ![]() with
with
![]() independent standard normals and
independent standard normals and

The estimated transformation is remarkably close to the transformation
![]() . Figure 10.11 displays the estimated transformation
. Figure 10.11 displays the estimated transformation
![]() , which represents the function
, which represents the function
![]() extremely well.
extremely well.
Breiman and Friedman (1985) applied the ACE methodology also to the Boston
housing data set (Harrison and Rubinfeld 1978; and Section
10.1).
The resulting final model
involved four predictors and has an ![]() of
of ![]() . (An application of ACE
to the full 13 variables resulted only in an increase for
. (An application of ACE
to the full 13 variables resulted only in an increase for ![]() of
of ![]() .)
Figure 10.12a shows a plot from their paper of the solution response surface
transformation
.)
Figure 10.12a shows a plot from their paper of the solution response surface
transformation ![]() . This function is seen to have a positive curvature
for central values of
. This function is seen to have a positive curvature
for central values of ![]() , connecting two straight line segments of different
slope on either side. This suggests that the log-transformation used by
Harrison and Rubinfeld (1978) may be too severe. Figure 10.12b shows the
response transformation for the original untransformed census measurements.
The remaining plot in Figure 10.12 display the other transformation
, connecting two straight line segments of different
slope on either side. This suggests that the log-transformation used by
Harrison and Rubinfeld (1978) may be too severe. Figure 10.12b shows the
response transformation for the original untransformed census measurements.
The remaining plot in Figure 10.12 display the other transformation ![]() ;
for details see Breiman and Friedman (1985).
;
for details see Breiman and Friedman (1985).
![\includegraphics[scale=0.2]{ANR10,12a.ps}](anrhtmlimg2737.gif) ![\includegraphics[scale=0.2]{ANR10,12b.ps}](anrhtmlimg2738.gif)
![\includegraphics[scale=0.2]{ANR10,12c.ps}](anrhtmlimg2739.gif) ![\includegraphics[scale=0.2]{ANR10,12d.ps}](anrhtmlimg2740.gif)
|
Exercises
10.3.1Prove that in the bivariate case the function given in 10.3.7 is indeed the optimal
transformation ![]() .
.
10.3.2Prove that in the bivariate case the function given in 10.3.8 is indeed the optimal
transformation ![]() .
.
10.3.3Try the ACE algorithm with some real data. Which smoother would you use as an elementary building block?
10.3.4In the discussion to the Breiman and Friedman article D. Pregibon and Y.
Vardi generated data from

10.3.5Try the ACE algorithm with the data set from Exercise 10.3.2. What transformations do you get? Do they coincide with the transformations you computed in 10.3.2?
[Hint: See the discussion of Breiman and Friedman (1985).]
![\begin{displaymath}
e^2(\Psi, g_1, \ldots, g_d)={E\{[ \Psi(Y) -
\sum_{j=1}^d g_j (X_j)]^2\} \over E\Psi^2(Y)}\cdotp
\end{displaymath}](anrhtmlimg2676.gif)
![\begin{displaymath}
e^2(\Psi, g) = E[ \Psi(Y) - g(X)]^2\ .
\end{displaymath}](anrhtmlimg2687.gif)
![\begin{displaymath}
\Psi_1(Y)=E[ g(X)\vert Y]\ /\Vert E[ g(X)\vert Y]
\Vert,
\end{displaymath}](anrhtmlimg2690.gif)
![\begin{displaymath}
g_1(X) = E[ \Psi(Y) \vert X].
\end{displaymath}](anrhtmlimg2693.gif)
![\includegraphics[scale=0.3]{ANR10,9.ps}](anrhtmlimg2719.gif)
![\includegraphics[scale=0.15]{ANR10,10.ps}](anrhtmlimg2721.gif)
![\includegraphics[scale=0.15]{ANR10,11.ps}](anrhtmlimg2724.gif)