Network packets are streaming data. Standard statistical and data
mining methods deal with a fixed data set. There is a concept of the
size of the data set (usually denoted ![]() ) and algorithms are chosen
based in part on their performance as a function of
) and algorithms are chosen
based in part on their performance as a function of ![]() . In streaming
data there is no
. In streaming
data there is no ![]() : the data are continually captured and must be
processed as they arrive. While one may collect a set of data to use
to develop algorithms, the nonstationarity of the data requires
methods that can handle the streaming data directly, and update their
models on the fly.
: the data are continually captured and must be
processed as they arrive. While one may collect a set of data to use
to develop algorithms, the nonstationarity of the data requires
methods that can handle the streaming data directly, and update their
models on the fly.
Consider the problem of estimating the average amount of data transfered in a session for a web server. This is not stationary: there are diurnal effects; there may be seasonal effects (for example at a university); there may be changes in the content at the server. We'd like a number calculated on a window of time that allows us to track (and account for) the normal trends and detect changes from this normal activity.
This requires some type of windowing or recursive technique. The recursive version of the sample mean is well known:
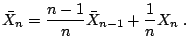 |
In fact, the kernel density estimator has a simple recursive version, that allows the recursive estimate of the kernel density estimator at a fixed grid of points. ([39], [34]) give two versions of this:
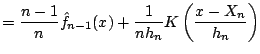 |
||
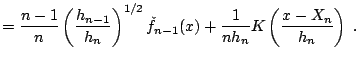 |
Similar approaches can be implemented for other density estimation techniques. In particular, the adaptive mixtures approach of ([27]) has a simple recursive formulation that can be adapted to streaming data.
There are several applications of density estimation to intrusion detection that one might consider. It is obvious that unusually large downloads (or uploads) may be suspicious in some environments. While it is not clear that density estimation is needed for this application, there might be some value in detecting changes in upload/download behavior. This can be detected through the tracking of the number of bytes transfered per session.
Perhaps a more compelling application is the detection of trojan programs. A trojan is a program that appears to be a legitimate program (such as a telnet server) but acts maliciously, for example to allow access to the computer by unauthorized users. Obviously the detection of trojans is an important aspect of computer security.
Most applications (web, email, ftp, et cetera) have assigned ports on which they operate. Other applications may choose to use fixed ports, or may choose any available port. Detecting new activity on a given port is a simple way to detect a trojan program. More sophisticated trojans will replace a legitimate application, such as a web server. It is thus desirable to determine when a legitimate application is acting in a manner that is unusual.
Consider Fig. 5.2. We have collected data for two
applications (web and secure shell) over a period of
![]() hour, and estimated the densities of the packet length
and inter arrival times.
As can be seen, the two applications have very different patterns for
these two measures. This is because they have different purposes:
secure shell is a terminal service which essentially sends a packet
for every character typed (there is also a data transfer mode to
secure shell, but this mode was not present in these data); web has
a data transfer component with a terminal-like user interaction.
hour, and estimated the densities of the packet length
and inter arrival times.
As can be seen, the two applications have very different patterns for
these two measures. This is because they have different purposes:
secure shell is a terminal service which essentially sends a packet
for every character typed (there is also a data transfer mode to
secure shell, but this mode was not present in these data); web has
a data transfer component with a terminal-like user interaction.
By monitoring these and other parameters, it is possible to distinguish between many of the common applications. This can then be used to detect when an application is acting in an unusual manner, such as when a web server is being used to provide telnet services. See ([7]) for a more extensive discussion of this.
Note that web traffic has two main peaks at either end of the extremes in packet size. These are the requests, which are typically small, and the responses, which are pages or images and are broken up into the largest packets possible. The mass between the peaks mostly represent the last packets of transfers which are not a multiple of the maximum packet size, and small transfers that fit within a single packet.
The inter packet arrival times for secure shell also have two peaks. The short times correspond to responses (such as the response to a directory list command) and to characters typed quickly. The later bump probably corresponds to the pauses between commands, as the user processes the response. These arrival times are very heavy tailed because of the nature of secure shell. Sessions can be left open indefinitely, and if no activity occurs for a sufficiently long time, ''keep alive'' packets are sent to ensure that the session is still valid.
In ([7]) it is shown, in fact, that differences in the
counts for the TCP flags can be used to differentiate
applications. These, combined with mean inter packet arrival times
and packet lengths (all computed on a window of ![]() packets for
various values of
packets for
various values of ![]() ), do a very creditable job of distinguishing
applications. This is clearly an area in which recursive methods like
those mentioned above would be of value. It also is reasonable to
hypothesize that estimating densities, rather then only computing the
mean, would improve the performance.
), do a very creditable job of distinguishing
applications. This is clearly an area in which recursive methods like
those mentioned above would be of value. It also is reasonable to
hypothesize that estimating densities, rather then only computing the
mean, would improve the performance.
By detecting changes in the densities of applications it may be possible to detect when they have been compromised (or replaced) by a trojan program. It may also be possible to detect programs that are not performing as advertised (web servers acting like telnet servers, for example).
![\includegraphics[width=11.7cm]{text/4-5/abb/length.time.eps}](img8268.gif)