We will now briefly consider host based intrusion detection. While the data considered is not network data, the statistical techniques used are applicable to network problems, as will be discussed.
One of the important problems of computer security is user authentication. This is usually performed by requiring the user to type a password at the initial login. Once a user is logged in, there are generally no checks to ensure that the person using the terminal is still the authorized person. User profiling seeks to address this by extracting ''person specific'' information as the user interacts with the computer. By comparing the user's activity with a profile of the user, it is hoped that masqueraders can be detected and locked out before they are able to do any damage.
We will discuss the usual host-based user profiling problem first, and then discuss a network based profiling application that has a similar flavor. The mathematics and statistics used for the two problems are very similar, only the data are different.
Several attempts have been made on this problem. Early work focused on utilizing keystroke timings. It was hoped that people had characteristic patterns of typing that could be discovered through measurement of the time between keystrokes for words or phrases. See for example ([5], [26], [16], [29]).
This type of approach has been applied at the network level to crack passwords. ([31]) describes using simple statistical techniques applied to packet arrival timings to determine the length of passwords in secure shell, and even to allow for the cracking of passwords. Secure shell is an application that allows remote login via an encrypted pathway. It sends a packet for each character typed, to minimize the delay for the user. Thus, by timing the packets, one can get an idea of what key combinations are being sent (it takes longer to type two characters with the same finger than it does if the characters are typed by fingers on different hands, for example). By utilizing statistics such as these, the authors were able to show that they could dramatically reduce the search space needed to crack the passwords.
Other work focuses on tracking user commands. The idea is that the command streams that users type (ignoring the arguments to the commands) could be used to authenticate the user in much the same way that keystroke timings could. A good discussion of this for statisticians can be found in ([30]). See also ([22], [23]) for some critiques of this work and extensions. The former paper considers arguments to the commands as well.
For Microsoft Windows operating systems, user command sequences are generally not applicable. Instead, window titles may be used. These correspond roughly to the same information that is contained in the Unix command lines. They typically contain the application name and the arguments to the applications such as the file open, the email subject, the web page visited, et cetera.
To illustrate this, we consider a set of data taken from six users on seven Windows NT machines over a period of several months. All window titles generated from the login to the logout were retained for each user/host pair (only one of the users was observed on a second host). Each time a window became active it was recorded. These data are a subset of a larger set. More information on these data, with some analysis of the data and performance of various classifiers can be found in ([6]).
| User | Session | Login Length | 1st App | Last App | #Apps | #Wins | #Titles |
| user1-host19 | |
msoffice | msoffice | |
|||
| user1-host19 | |
msoffice | msoffice | |
|||
| user1-host19 | |
msoffice | msoffice | ||||
| user1-host5 | |
explorer | explorer | |
|
|
|
| user1-host5 | |
explorer | explorer | |
|
|
|
| user1-host5 |
|
explorer | explorer | |
|||
| user19-host10 | |
|
msoffice | msoffice | |
|
|
| user19-host10 | |
|
msoffice | msoffice | |
|
|
| user19-host10 | msoffice | acrord32 | |
|
|
||
| user25-host4 | |
|
explorer | explorer | |
||
| user25-host4 | |
|
explorer | explorer | |
||
| user25-host4 | explorer | explorer | |
||||
| user4-host17 |
|
wscript | explorer | |
|||
| user4-host17 | explorer | explorer | |
|
|
||
| user4-host17 |
|
explorer | winword | |
|||
| user7-host20 |
|
outlook | outlook | |
|
|
|
| user7-host20 |
|
wscript | mapisp32 | |
|
|
|
| user7-host20 |
|
wscript | outlook | |
|
||
| user8-host6 | |
|
wscript | explorer | |
||
| user8-host6 | |
outlook | explorer | |
|
|
|
| user8-host6 | cmd | explorer | |
|
|
| # | #Sessions | Window Title |
| Inbox - Microsoft Outlook | ||
| Program Manager | ||
| Microsoft Word | ||
| |
Netscape | |
| |
||
| |
Microsoft Outlook | |
| |
|
|
| |
|
|
| |
|
|
| |
Microsoft(
|
|
| |
|
|
| |
|
|
| |
- Microsoft Outlook | |
| |
|
Microsoft PowerPoint |
| |
|
|
Table 5.1 shows some statistics on these data. Three sessions are shown for each user/host pair. The length of the login session (in seconds), the name of the first and last applications used within the session, and the number of distinct applications, windows and window titles are shown. The task is to extract statistics from a completed login session that allow one to determine whether the user was the authorized user indicated by the userid. This is an easier problem than masquerader detection, in which one tries to detect the masquerader (or authenticate the user) as the session progresses, and it is not assumed that the entire session corresponds to a single user (or masquerader).
The table indicates that there is some variability among the sessions of individual users, and this is born out by further analysis. Table 5.2 shows the most common window titles. The number of times the title occurs in the data set, the number of login sessions in which the title occurs, and the title itself are shown. Some words in the titles have been obfuscated by replacement with numbers in double brackets, to protect the privacy of the users. All common application and operating system words were left alone. The obfuscation is consistent across all sessions: there is a bijection between numbers and words that holds throughout the data.
Figure 5.10 shows part of a single login session. The rows and columns correspond to the list of words (as they appear in the titles) and a dot is placed where the word appears in both the row and column. The blocks of diagonal lines are characteristic of a single window in session. The ''plus'' in the lower left corner shows a case of the user switching windows, then switching back. This type of behavior is seen throughout the data.
![\includegraphics[width=9cm]{text/4-5/abb/crossplot.eps}](img8360.gif)
|
Many features were extracted from the data, and several feature selection and dimensionality reduction techniques were tried. The results for these approaches were not impressive. See ([6]) for more discussion.
The classifiers that worked best with these data were simple
intersection classifiers.
For each session, the total set of window titles used (without regard
to order) was collected. Then to classify a new session, the
intersection of its title set with those from user sessions was
computed, and the user with the largest intersection was deemed to be
the user of the session. Various variations on this theme were tried,
all of which performed in the mid to high
![]() percent range
for correct classification.
percent range
for correct classification.
Much more needs to be done to produce a usable system. Most importantly, the approach must move from the session level to within-session calculations. Further, it is not important to classify the user as one of a list of users, but to simply state whether the user's activity matches that of the userid. It may be straight forward to modify the intersection classifier (for example, set a threshold and if the intersection is below the threshold, raise an alarm) but it is not clear how well this will work.
We can state a few generalities about user profiling systems. Users are quite variable, and such systems tend to have an unacceptably high false alarm rate. Keystroke timings tend to be much more useful when used with a password or pass phrase than in free typing. No single technique exists which can be used reliably to authenticate users as they work.
The intersection classifier
leads to interesting statistics. We can construct graphs using these
intersections, each node of the graph corresponding to a session, with
an edge between two nodes if their sets intersect nontrivially (or
have an intersection of size at least ![]() ).
).
In another context (profiling the web server usage of users) ([20]) discusses various analyses that can be done on these graphs. This uses network data, extracting the source and destination IP addresses from the sessions. In these data there is a one-to-one correspondence between source IP address and user, since all the machines considered were single user machines.
In this case the nodes correspond to users and the sets consist of the
web servers visited by the user within a period of a week. A random
graph model, first described in ([13]) is used as the
null hypothesis corresponding to random selection of servers. The
model assumes a set
![]() of servers from which the users
draw. To define the set of servers for a given user, each server is
drawn with probability
of servers from which the users
draw. To define the set of servers for a given user, each server is
drawn with probability ![]() . Thus, given the observations of the
sets
. Thus, given the observations of the
sets ![]() drawn by the users, we must estimate the two parameters of
the model:
drawn by the users, we must estimate the two parameters of
the model:
![]() and
and ![]() . These can be estimated using
maximum likelihood (see also ([21]) for discussion of
this and other types of intersection graphs).
With the notation
. These can be estimated using
maximum likelihood (see also ([21]) for discussion of
this and other types of intersection graphs).
With the notation
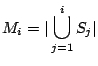 |
|
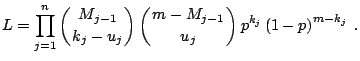 |
Using data collected for several months, ([20]) computed the probability of any given edge, under the null hypothesis, and retained those that had a significantly large intersection (after correcting for the multiple hypotheses tested). The most common of these were retained, and the resulting graph is shown in Fig. 5.6.
![\includegraphics[width=53mm]{text/4-5/abb/fig1-11.eps}](img8368.gif)
|
There are two triangles in Fig. 5.6, and it turns out that the users in these correspond to physicists working on fluid dynamics problems. Users A, D and E are system administrators. Thus, there is some reason to believe that the relationships we have discovered are interesting.
The model is simplistic, perhaps overly so. It is reasonable to assume
that users have different values of ![]() , and some preliminary
investigation (described in [20]) bears this
out. This is an easy modification to make. Further, intuition tells
us that perhaps all web servers should not have the same probabilities
either. This is more problematic, since we cannot have a separate
probability for each server and hope to be able to estimate them
all. A reasonable compromise might be to group servers into
common/rare groups or something similar.
, and some preliminary
investigation (described in [20]) bears this
out. This is an easy modification to make. Further, intuition tells
us that perhaps all web servers should not have the same probabilities
either. This is more problematic, since we cannot have a separate
probability for each server and hope to be able to estimate them
all. A reasonable compromise might be to group servers into
common/rare groups or something similar.
The above discussion illustrates one of the methodologies used for anomaly detection. For determining when a service, server, or user is acting in an unusual manner, one first groups the entities using some model, then raises an alert when an entity appears to leave the group. Alternatively, one can have a single entity, for example ''the network'' or a given server, and build a model of the behavior of that entity under normal conditions. When the behavior deviates from these conditions by a significant amount, an alert is raised.
Other researchers have investigated the profiling of program execution, for the purpose of detecting attacks such as buffer overflows which can cause the program to act in an unusual way. See for example ([11], [10], [9], [33]). Programs execute sequences of system calls, and the patterns of system calls that occur under normal conditions are used to detect abnormal execution.