Let us now consider a typical linear regression
problem.
We assume that anyone of you has been exposed
to the linear regression model where the mean of
a dependent variable ![]() is related to a set of explanatory
variables
is related to a set of explanatory
variables
![]() in the following way:
in the following way:
| (1.1) |
| (1.2) |
| (1.3) |
The model of equation (1.4) has played an
important role in empirical labor economics and is often called
human capital earnings equation (or Mincer earnings
equation to honor Jacob Mincer, a pioneer of this line of
research).
From the perspective of this course, an important characteristic of equation
(1.4) is its parametric form: the shape of
the regression function is governed by the unknown parameters
![]()
![]() . That is, all we have to do in order to
determine the linear regression function (1.4) is to
estimate the unknown parameters
. That is, all we have to do in order to
determine the linear regression function (1.4) is to
estimate the unknown parameters ![]() .
On the other hand, the parametric regression function of equation
(1.4) a priori rules out many
conceivable nonlinear relationships between
.
On the other hand, the parametric regression function of equation
(1.4) a priori rules out many
conceivable nonlinear relationships between ![]() and
and
![]() .
.
Let
![]() be the true, unknown regression
function of log wages on schooling and experience.
That is,
be the true, unknown regression
function of log wages on schooling and experience.
That is,
| (1.5) |
It turns out that there are indeed ways of estimating
![]() that
merely assume that
that
merely assume that
![]() is a smooth function. These methods
are called nonparametric regression estimators and part of this
course will be devoted to studying nonparametric regression.
is a smooth function. These methods
are called nonparametric regression estimators and part of this
course will be devoted to studying nonparametric regression.
Nonparametric regression estimators are very flexible but their statistical precision decreases greatly if we include several explanatory variables in the model. The latter caveat has been appropriately termed the curse of dimensionality. Consequently, researchers have tried to develop models and estimators which offer more flexibility than standard parametric regression but overcome the curse of dimensionality by employing some form of dimension reduction. Such methods usually combine features of parametric and nonparametric techniques. As a consequence, they are usually referred to as semiparametric methods. Further advantages of semiparametric methods are the possible inclusion of categorical variables (which can often only be included in a parametric way), an easy (economic) interpretation of the results, and the possibility of a part specification of a model.
In the following three sections we use the earnings equation and other examples to illustrate the distinctions between parametric, nonparametric and semiparametric regression and we certainly hope that this will whet your appetite for the material covered in this course.
Versions of the human capital earnings equation of (1.4) have probably been estimated by more researchers than any other model of empirical economics. For a detailed nontechnical and well-written discussion see Berndt (1991, Chapter 5). Here, we want to point out that:
| Dependent Variable: Log Wages | |||
| Variable | Coefficients | S.E. | |
|
|
0.0898 | 0.0083 | 10.788 |
|
|
0.0349 | 0.0056 | 6.185 |
|
|
-0.0005 | 0.0001 | -4.307 |
| constant | 0.5202 | 0.1236 | 4.209 |
We have estimated the coefficients of (1.4) using ordinary least squares (OLS), using a subsample of the 1985 Current Population Survey (CPS) provided by Berndt (1991). The results are given in Table 1.1.
The estimated rate of return to schooling is roughly ![]() .
Note that the estimated coefficients of
.
Note that the estimated coefficients of
![]() and
and
![]() have the signs predicted by human capital theory. The shape of the
wage-schooling (a plot of SCHOOL vs.
have the signs predicted by human capital theory. The shape of the
wage-schooling (a plot of SCHOOL vs.
![]() )
and wage-experience (a plot of EXP vs.
)
and wage-experience (a plot of EXP vs.
![]() ) profiles
are given in the left and right graphs of Figure 1.2,
respectively.
) profiles
are given in the left and right graphs of Figure 1.2,
respectively.
The estimated wage-schooling relation is linear ``by default''
since we did not
include
![]() say, to allow for some kind of
curvature within the parametric framework.
By looking at Figure 1.2 it is clear that the estimated
coefficients of
say, to allow for some kind of
curvature within the parametric framework.
By looking at Figure 1.2 it is clear that the estimated
coefficients of
![]() and
and
![]() imply the kind of
concave wage-earnings profile predicted by human capital theory.
imply the kind of
concave wage-earnings profile predicted by human capital theory.
We have also plotted a graph (Figure 1.3)
of the estimated regression surface,
i.e. a plot that has the values of the estimated regression function
(obtained by evaluating
![]() at the
observed combinations of schooling and experience) on the vertical
axis and schooling and experience on the horizontal axes.
at the
observed combinations of schooling and experience) on the vertical
axis and schooling and experience on the horizontal axes.
All of the element curves of the surface appear similar to Figure 1.2 (right) in the direction of experience and like Figure 1.2 (left) in the direction of schooling. To gain a better understanding of the three-dimensional picture we have plotted a single wage-experience profile in three dimensions, fixing schooling at 12 years. Hence, Figure 1.3 highlights the wage-earnings profile for high school graduates.
Suppose that we want to estimate
| Observation | log(WAGES) | SCHOOL | EXP |
| 1 | 7.31 | 8 | 8 |
| 2 | 7.6 | 16 | 1 |
| 3 | 7.4 | 8 | 6 |
| 4 | 7.8 | 12 | 2 |
In nonparametric regression ![]() is estimated by averaging over
the observed values of the dependent variable log wage. But not all
values will be given the same weight. In our example, observation 1 will
get the most weight since it has values of schooling and experience
that are very close to the point where we want to estimate. This
makes a lot of sense: if we want to estimate mean log wages for
individuals with 8 years of schooling and 7 years of experience then
the observed log wage of a person with 8 years of schooling and 8
years of experience seems to be much more informative than the
observed log wage of a person with 12 years of schooling and 2 years
of experience.
is estimated by averaging over
the observed values of the dependent variable log wage. But not all
values will be given the same weight. In our example, observation 1 will
get the most weight since it has values of schooling and experience
that are very close to the point where we want to estimate. This
makes a lot of sense: if we want to estimate mean log wages for
individuals with 8 years of schooling and 7 years of experience then
the observed log wage of a person with 8 years of schooling and 8
years of experience seems to be much more informative than the
observed log wage of a person with 12 years of schooling and 2 years
of experience.
Consequently, any reasonable weighting scheme will
give more weight to 7.31 than to 7.8 when we average over observed
log wages. The exact method of weighting is determined by a weight
function that makes precise the idea of weighting nearby observations
more heavily. In fact, the weight function might be such that
observations that are too far away get zero weight. In our
example, observation 2 has values of experience and schooling that
are so far away from 8 years of schooling and 7 years of experience
that a weight function might assign zero value to the corresponding
value of log wages (7.6). It is in this sense that the averaging is
local. In Figure 1.4, the surface
of nonparametrically estimated values of
![]() are shown.
Here, a so-called kernel estimator has been used.
are shown.
Here, a so-called kernel estimator has been used.
As long as we are dealing with only one regressor, the results of estimating a regression function nonparametrically can easily be displayed in a graph. The following example illustrates this. It relates net-income data, as we considered in Example 1.1, to a second variable that measures household expenditure.
... je ärmer eine Familie ist, einen desto größeren Antheil von der Gesammtausgabe muß zur Beschaffung der Nahrung aufgewendet werden ... (The poorer a family, the bigger the share of total expenditure that has to be used for food.)
To illustrate semiparametric regression let us return to the human capital earnings function of Example 1.2. Suppose the regression function of log wages on schooling and experience has the following shape:
![\includegraphics[width=1.4\defpicwidth]{SPMcps85addA.ps}](spmhtmlimg352.gif)
|
In Figure 1.6 the parametrically estimated
wage-schooling and wage-experience profiles are shown as thin lines
whereas the estimates of
![]() and
and
![]() are
displayed as thick lines with bullets.
The parametrically estimated wage-school and wage-experience
profiles show a good deal of similarity with the
estimate of
are
displayed as thick lines with bullets.
The parametrically estimated wage-school and wage-experience
profiles show a good deal of similarity with the
estimate of
![]() and
and
![]() , except for the
shape of the curve at extremal values.
The good agreement
between parametric estimates and additive model fit is also visible
from the plot of the estimated regression surface, which is shown
in Figure 1.7.
, except for the
shape of the curve at extremal values.
The good agreement
between parametric estimates and additive model fit is also visible
from the plot of the estimated regression surface, which is shown
in Figure 1.7.
Hence, we may conclude that in this specific example the parametric model is supported by the more flexible nonparametric and semiparametric methods. This potential usefulness of nonparametric and semiparametric techniques for checking the adequacy of parametric models will be illustrated in several other instances in the latter part of this course.
Take a closer look at (1.6) and (1.7). Observe
that in (1.6) we have to estimate one unknown function of
two variables whereas in (1.7) we have to estimate two
unknown functions, each a function of one variable.
It is in this sense that we have
reduced the dimensionality of the estimation problem. Whereas all
researchers might agree that additive models like the one in (1.7)
are achieving a dimension reduction over completely nonparametric
regression, they may not agree to call (1.7) a
semiparametric model, as there are no parameters to estimate (except
for the intercept parameter ![]() ). In the following example we
confront a standard parametric model with a more flexible model that,
as you will see, truly deserves to be called semiparametric.
). In the following example we
confront a standard parametric model with a more flexible model that,
as you will see, truly deserves to be called semiparametric.
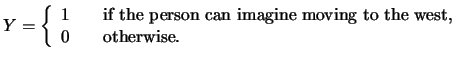
In Example 1.2 we tried to estimate the effect of
a person's education and work experience on the log wage earned. Now,
say we want to find out how these two variables affect
the decision of an East German resident to move west, i.e. we want to
know
![]() where
where
![]() is a
is a
![]() vector containing all
vector containing all
![]() variables considered to be influential to the migration decision.
Since
variables considered to be influential to the migration decision.
Since ![]() is a binary variable (i.e. a Bernoulli distributed variable),
we have that
is a binary variable (i.e. a Bernoulli distributed variable),
we have that
| (1.8) |
In the context of this lecture, the crucial question is precisely
what parametric form these two functions take or, more
generally, whether they
will take any parametric form at all. For now we want to compare two models: one that assumes that
![]() is of a known parametric form and one that allows
is of a known parametric form and one that allows
![]() to be an unknown smooth function.
to be an unknown smooth function.
One of the most widely used fully parametric models applied to the
case of binary dependent variables is the logit model.
The logit model assumes that
![]() is the (standard) logistic cumulative
distribution function (cdf) for all
is the (standard) logistic cumulative
distribution function (cdf) for all
![]() .
Hence, in this case
.
Hence, in this case
Figure 1.8 gives a graphical presentation of the results.
Each observation is represented by a "+". As mentioned above, the
characteristics of each person are transformed into an index (to be
read off the horizontal axis) while the dependent variable takes on
one of two values, ![]() or
or ![]() (to be read off the vertical
axis). The curve plots estimates of
(to be read off the vertical
axis). The curve plots estimates of
![]() the probability of
the probability of
![]() as a function of
as a function of
![]() . Note that the estimates of
. Note that the estimates of
![]() by assumption, are simply points on the cdf
of a standard logistic distribution.
by assumption, are simply points on the cdf
of a standard logistic distribution.
We shall continue with Example 1.4 below, but let us pause for a moment to consider the following substantial problem: the logit model, like other parametric models, is based on rather strong functional form (linear index) and distributional assumptions, neither of which are usually justified by economic theory.
The first question to ask before developing alternatives to standard models like the logit model is: what are the consequences of estimating a logit model if one or several of these assumptions are violated? Note that this is a crucial question: if our parametric estimates are largely unaffected by model violations, then there is no need to develop and apply semiparametric models and estimators. Why would anyone put time and effort into a project that promises little return?
One can employ the tools of asymptotic statistical theory to show that violating the assumptions of the logit model leads parameter estimates to being inconsistent. That is, if the sample size goes to infinity, the logit maximum-likelihood estimator (logit-MLE) does not converge to the true parameter value in probability. While it doesn't converge to the true parameter value it does, however, converge to some other value. If this "false" value is close enough to the true parameter value then we may not care very much about this inconsistency.
Consistency is an asymptotic criterion for the performance of an estimator. That is, it looks at the properties of the estimator if the sample size grows without limits. Yet, in practice, we are dealing with finite samples. Unfortunately, the finite-sample properties of the logit maximum-likelihood estimator can not be derived analytically. Hence, we have to rely on simulations to collect evidence of its small-sample performance in the presence of misspecification. We conducted a small simulation in the context of Example 1.4 to which we now return.
![\includegraphics[width=1.2\defpicwidth]{SPMtruelogit.ps}](spmhtmlimg378.gif)
|
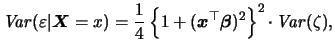
To add a sense of realism to the simulation, we set the coefficients of
these variables equal to the estimates reported in
(1.11). Note that the standard logit model introduced above
does not allow for heteroscedasticity. Hence, if we apply the
standard logit maximum-likelihood estimator to the simulated data, we
are estimating under misspecification. We performed 250 replications
of this estimation experiment, using the full data set with 402 observations
each time.
As the estimated coefficients are only identified up to scale, we
compared the ratio of the true coefficients,
![]() , to the ratio of
their estimated logit-MLE counterparts,
, to the ratio of
their estimated logit-MLE counterparts,
![]() .
Figure 1.10 shows the
sampling distribution of the logit-MLE coefficients, along with
the true value (vertical line).
.
Figure 1.10 shows the
sampling distribution of the logit-MLE coefficients, along with
the true value (vertical line).
As we have subtracted the true value
from each estimated ratio and divided this difference by
the true ratio's absolute value, the true ratio is standardized to
zero and differences on the horizontal axis can be
interpreted as percentage deviations from the truth. In
Figure 1.10, the sampling distribution
of the estimated ratios is centered around
![]() which is the percentage deviation from the truth of 11%.
Hence, the logit-MLE
underestimates the true value.
which is the percentage deviation from the truth of 11%.
Hence, the logit-MLE
underestimates the true value.
![\includegraphics[width=1.2\defpicwidth]{SPMsimulogit.ps}](spmhtmlimg386.gif)
|
Now that we have seen how serious the consequences of model
misspecification can be, we might want to learn about semiparametric estimators that have desirable properties under more general assumptions
than their parametric counterparts. One way to generalize the logit
model is the so-called single index model (SIM) which keeps the
linear form of the index
![]() but
allows the function
but
allows the function
![]() in (1.9) to be an arbitrary smooth
function
in (1.9) to be an arbitrary smooth
function
![]() (not necessarily a distribution function) that has to
be estimated from the data:
(not necessarily a distribution function) that has to
be estimated from the data:
One additional remark should be made here: As you will soon
learn, the shape of the estimated link function (the curve)
varies with the so-called bandwidth, a parameter
central in nonparametric function estimation. Thus, there is
no unique estimate of the link function, and it is a crucial (and
difficult) problem of nonparametric regression to find the ``best"
bandwidth and thus the optimal estimate.
Fortunately, there are methods to select an appropriate bandwidth.
Here, we have
chosen ![]() ``index units" for the bandwidth.
For comparison the shapes of both the single index (solid line)
and the logit (dashed line) link functions
are shown ins in Figure 1.8. Even though not
identical they look rather similar.
``index units" for the bandwidth.
For comparison the shapes of both the single index (solid line)
and the logit (dashed line) link functions
are shown ins in Figure 1.8. Even though not
identical they look rather similar.
![\includegraphics[width=1.4\defpicwidth]{SPMcps85linA.ps}](spmhtmlimg332.gif)
![\includegraphics[width=1.3\defpicwidth]{SPMcps85linB.ps}](spmhtmlimg337.gif)
![\includegraphics[width=1.3\defpicwidth]{SPMcps85reg.ps}](spmhtmlimg346.gif)
![\includegraphics[width=1.2\defpicwidth]{SPMengelcurve2.ps}](spmhtmlimg347.gif)
![\includegraphics[width=1.3\defpicwidth]{SPMcps85addB.ps}](spmhtmlimg353.gif)
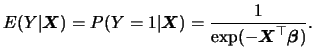
![\includegraphics[width=1.2\defpicwidth]{SPMlogit.ps}](spmhtmlimg377.gif)
![\includegraphics[width=1.2\defpicwidth]{SPMsim.ps}](spmhtmlimg391.gif)