Discriminant analysis is
a set of methods and tools used to distinguish between groups of
populations ![]() and to determine
how to allocate new observations into groups.
In one of our running examples we are interested in discriminating between
counterfeit and true bank notes on the basis of measurements of
these bank notes, see Table B.2.
In this case we have two groups (counterfeit and genuine bank notes) and we
would like to establish an algorithm (rule) that can allocate a new
observation (a new bank note) into one of the groups.
and to determine
how to allocate new observations into groups.
In one of our running examples we are interested in discriminating between
counterfeit and true bank notes on the basis of measurements of
these bank notes, see Table B.2.
In this case we have two groups (counterfeit and genuine bank notes) and we
would like to establish an algorithm (rule) that can allocate a new
observation (a new bank note) into one of the groups.
Another example is the detection of ``fast'' and ``slow'' consumers of a newly introduced product. Using a consumer's characteristics like education, income, family size, amount of previous brand switching, we want to classify each consumer into the two groups just identified.
In poetry and literary studies the frequencies of spoken or written words and lengths of sentences indicate profiles of different artists and writers. It can be of interest to attribute unknown literary or artistic works to certain writers with a specific profile. Anthropological measures on ancient sculls help in discriminating between male and female bodies. Good and poor credit risk ratings constitute a discrimination problem that might be tackled using observations on income, age, number of credit cards, family size etc.
In general we have populations
![]() and we have to
allocate an observation
and we have to
allocate an observation ![]() to one of these groups. A
discriminant rule is a separation of
the sample space (in general
to one of these groups. A
discriminant rule is a separation of
the sample space (in general ![]() ) into sets
) into sets ![]() such that if
such that if ![]() ,
it is identified as a member of population
,
it is identified as a member of population ![]() .
.
The main task of discriminant analysis is to find ``good'' regions ![]() such that the error of misclassification is small.
In the following we describe such rules when the population
distributions are known.
such that the error of misclassification is small.
In the following we describe such rules when the population
distributions are known.
Denote the densities of each population ![]() by
by ![]() .
The maximum likelihood discriminant rule (ML rule)
is given by allocating
.
The maximum likelihood discriminant rule (ML rule)
is given by allocating ![]() to
to ![]() maximizing
the likelihood
maximizing
the likelihood
![]() .
.
If several ![]() give the same maximum then any of them may be selected.
Mathematically, the sets
give the same maximum then any of them may be selected.
Mathematically, the sets ![]() given by the ML discriminant rule are
defined as
given by the ML discriminant rule are
defined as
| (12.1) |
By classifying the observation into certain group we may encounter
a misclassification error.
For ![]() groups the probability of
putting
groups the probability of
putting ![]() into group
into group ![]() although it is from population
although it is from population ![]() can be calculated as
can be calculated as
| Classified population | |||
| 0 | |||
| True population | |||
| 0 | |||
Let ![]() be the prior probability of population
be the prior probability of population ![]() , where
``prior'' means the a priori probability that an individual selected
at random belongs to
, where
``prior'' means the a priori probability that an individual selected
at random belongs to ![]() (i.e., before looking to the value
(i.e., before looking to the value ![]() ).
Prior probabilities should be considered if it is clear ahead of time
that an observation is more likely to stem from a certain population
).
Prior probabilities should be considered if it is clear ahead of time
that an observation is more likely to stem from a certain population ![]() An example is the classification of musical tunes.
If it is known that during a certain period
of time a majority of tunes were written by a certain
composer, then there is a higher probability that a certain tune was
composed by this composer. Therefore, he should receive
a higher prior probability when tunes are assigned to a specific group.
An example is the classification of musical tunes.
If it is known that during a certain period
of time a majority of tunes were written by a certain
composer, then there is a higher probability that a certain tune was
composed by this composer. Therefore, he should receive
a higher prior probability when tunes are assigned to a specific group.
The expected cost of misclassification
![]() is given by
is given by
The ML discriminant rule is thus a special case of the ECM rule for equal misclassification costs and equal prior probabilities. For simplicity the unity cost case,
Theorem 12.1 will be proven by an example from credit scoring.
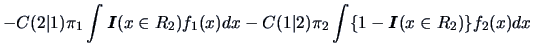 |
|||
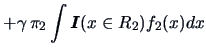 |
|||
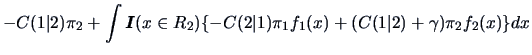 |
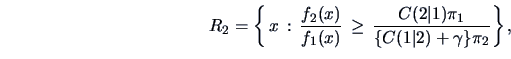
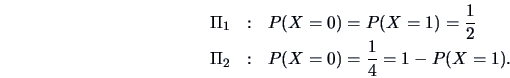

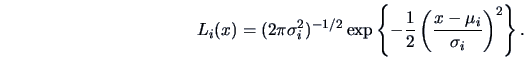
![\begin{displaymath}\frac{\sigma _2 }{\sigma _1 }\exp \left \{-\frac{1 }{2 }\left...
... (\frac{x-\mu _2}{\sigma _2 }\right )^2\right ]\right \}\geq 1
\end{displaymath}](mvahtmlimg3392.gif)
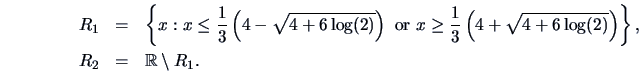
The situation simplifies in the case of equal variances
![]() . The discriminant rule (12.5) is then ( for
. The discriminant rule (12.5) is then ( for
![]() )
)
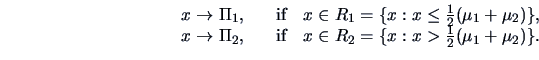 |
(12.6) |
Theorem 12.2 shows that the ML discriminant rule for multinormal observations is intimately connected with the Mahalanobis distance. The discriminant rule is based on linear combinations and belongs to the family of Linear Discriminant Analysis (LDA) methods.
PROOF:
Part (a) of the Theorem follows directly from comparison of the likelihoods.
For ![]() , part (a) says that
, part (a) says that ![]() is allocated to
is allocated to ![]() if
if
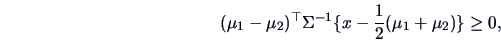
We have seen an example where prior knowledge
on the probability of classification into ![]() was assumed.
Denote the prior probabilities by
was assumed.
Denote the prior probabilities by ![]() and note that
and note that
![]() .
The Bayes rule of discrimination
allocates
.
The Bayes rule of discrimination
allocates ![]() to the
to the ![]() that gives the largest
value of
that gives the largest
value of ![]() ,
,
![]() .
Hence, the discriminant rule is defined by
.
Hence, the discriminant rule is defined by
![]() .
Obviously the Bayes rule is identical to the ML discriminant
rule for
.
Obviously the Bayes rule is identical to the ML discriminant
rule for ![]() .
.
A further modification is to allocate ![]() to
to ![]() with a
certain probability
with a
certain probability ![]() , such that
, such that
![]() for all
for all ![]() .
This is called a randomized discriminant rule.
A randomized discriminant rule is a generalization of
deterministic discriminant rules since
.
This is called a randomized discriminant rule.
A randomized discriminant rule is a generalization of
deterministic discriminant rules since
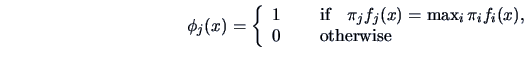
Which discriminant rules are good?
We need a measure of comparison. Denote
Suppose that
![]() .
In the case of two groups, it is not difficult to derive the probabilities of
misclassification for the ML discriminant rule. Consider for instance
.
In the case of two groups, it is not difficult to derive the probabilities of
misclassification for the ML discriminant rule. Consider for instance
![]() . By part (b) in Theorem 12.2
we have
. By part (b) in Theorem 12.2
we have

The minimum ![]() depends on the ratio of the densities
depends on the ratio of the densities
![]() or equivalently on the difference
or equivalently on the difference
![]() .
When the covariance for both density functions differ,
the allocation rule becomes more complicated:
.
When the covariance for both density functions differ,
the allocation rule becomes more complicated:
![\begin{eqnarray*}
R_1 & = & \left\{ x: -\frac{1}{2}x^{T} (\Sigma^{-1}_1-\Sigma^{...
...)} \right)
\left( \frac{\pi_2}{\pi_1} \right) \right] \right\},
\end{eqnarray*}](mvahtmlimg3437.gif)
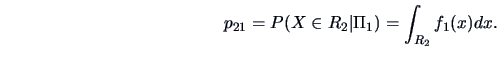
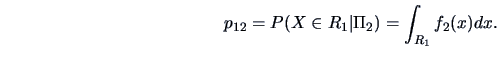
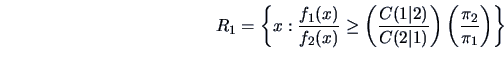
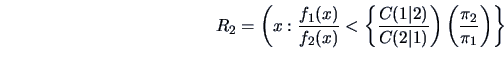
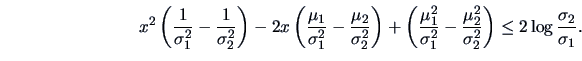
![\includegraphics[width=1\defpicwidth]{disnormr.ps}](mvahtmlimg3398.gif)
