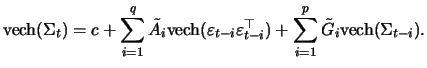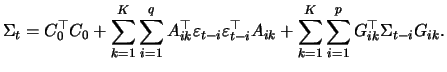Volatility clustering, i.e. positive correlation of price variations observed on speculative markets, motivated the introduction of autoregressive conditionally heteroskedastic (ARCH) processes by Engle (1982) and its popular generalizations by Bollerslev (1986) (Generalized ARCH, GARCH) and Nelson (1991) (exponential GARCH, EGARCH). Being univariate in nature, however, such models neglect a further stylized fact of empirical price variations, namely contemporaneous cross correlation e.g. over a set of assets, stock market indices, or exchange rates.
Cross section relationships are often implied by economic theory. Interest rate parities, for instance, provide a close relation between domestic and foreign bond rates. Assuming absence of arbitrage, the so-called triangular equation formalizes the equality of an exchange rate between two currencies on the one hand and an implied rate constructed via exchange rates measured towards a third currency. Furthermore, stock prices of firms acting on the same market often show similar patterns in the sequel of news that are important for the entire market (Hafner and Herwartz; 1998). Similarly, analyzing global volatility transmission Engle, Ito and Lin (1990) and Hamao, Masulis and Ng (1990) found evidence in favor of volatility spillovers between the world's major trading areas occurring in the sequel of floor trading hours. From this point of view, when modeling time varying volatilities, a multivariate model appears to be a natural framework to take cross sectional information into account. Moreover, the covariance between financial assets is of essential importance in finance. Effectively, many problems in financial practice like portfolio optimization, hedging strategies, or Value-at-Risk evaluation require multivariate volatility measures (Cecchetti, Cumby and Figlewski; 1988; Bollerslev et al.; 1988).
Let
![]() denote an
denote an ![]() -dimensional error
process, which is either directly observed or estimated from a multivariate regression
model. The process
-dimensional error
process, which is either directly observed or estimated from a multivariate regression
model. The process
![]() follows a multivariate GARCH process if it has the
representation
follows a multivariate GARCH process if it has the
representation
The conditional covariance matrix,
![]() ,
has typical elements
,
has typical elements
![]() with
with
![]() denoting conditional
variances and off-diagonal elements
denoting conditional
variances and off-diagonal elements
![]() , denoting
conditional covariances. To make the specification in (10.1) feasible a
parametric description relating
, denoting
conditional covariances. To make the specification in (10.1) feasible a
parametric description relating ![]() to
to
![]() is necessary. In a
multivariate setting, however, dependencies of the second order moments in
is necessary. In a
multivariate setting, however, dependencies of the second order moments in ![]() on
on
![]() become easily computationally intractable for practical purposes.
become easily computationally intractable for practical purposes.
Let vech(![]() ) denote the half-vectorization operator stacking the elements of a quadratic
(
) denote the half-vectorization operator stacking the elements of a quadratic
(
![]() -matrix
-matrix ![]() from the main diagonal downwards in a
from the main diagonal downwards in a
![]() dimensional column vector. Within the so-called vec-representation of the GARCH(
dimensional column vector. Within the so-called vec-representation of the GARCH(![]() )
model
)
model ![]() is specified as follows:
is specified as follows:
On the one hand the vec-model in (10.2) allows for a very general dynamic
structure of the multivariate volatility process. On the other hand this specification
suffers from high dimensionality of the relevant parameter space, which makes it almost
intractable for empirical work. In addition, it might be cumbersome in applied work to
restrict the admissible parameter space such that the implied matrices
![]() , are positive definite. These issues motivated a considerable variety of
competing multivariate GARCH specifications.
, are positive definite. These issues motivated a considerable variety of
competing multivariate GARCH specifications.
Prominent proposals reducing the dimensionality of
(10.2) are the constant correlation model (Bollerslev; 1990)
and the diagonal model (Bollerslev et al.; 1988). Specifying diagonal elements
of ![]() both of these approaches assume the absence of cross
equation dynamics, i.e. the only dynamics are
both of these approaches assume the absence of cross
equation dynamics, i.e. the only dynamics are
For the bivariate case (![]() ) with
) with ![]() the constant correlation model contains only
7 parameters compared to 21 parameters encountered in the full model (10.2). The
diagonal model is specified with 9 parameters. The price that both models pay for
parsimonity is in ruling out cross equation dynamics as allowed in the general vec-model.
Positive definiteness of
the constant correlation model contains only
7 parameters compared to 21 parameters encountered in the full model (10.2). The
diagonal model is specified with 9 parameters. The price that both models pay for
parsimonity is in ruling out cross equation dynamics as allowed in the general vec-model.
Positive definiteness of ![]() is easily guaranteed for the constant correlation
model (
is easily guaranteed for the constant correlation
model (
![]() ), whereas the diagonal model requires more complicated
restrictions to provide positive definite covariance matrices.
), whereas the diagonal model requires more complicated
restrictions to provide positive definite covariance matrices.
The so-called BEKK-model (named after Baba, Engle, Kraft and Kroner, 1990)
provides a richer dynamic structure compared to both restricted
processes mentioned before.
Defining
![]() matrices
matrices
![]() and
and ![]() and an upper triangular matrix
and an upper triangular matrix ![]() the
BEKK-model reads in a general version as follows:
the
BEKK-model reads in a general version as follows:
As in the univariate case the parameters of a multivariate GARCH model are estimated by maximum likelihood (ML) optimizing numerically the Gaussian log-likelihood function.
With ![]() denoting the multivariate normal density, the contribution of a single
observation,
denoting the multivariate normal density, the contribution of a single
observation, ![]() to the log-likelihood of a sample is given as:
to the log-likelihood of a sample is given as:
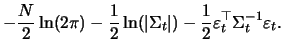 |
If the actual error distribution differs from the multivariate normal, maximizing the
Gaussian log-likelihood has become popular as Quasi ML (QML) estimation. In the
multivariate framework, results for the asymptotic properties of the (Q)ML-estimator have
been derived recently. Jeantheau (1998) proves the QML-estimator to be consistent under
the main assumption that the considered multivariate process is strictly stationary and
ergodic. Further assuming finiteness of moments of
![]() up to order eight,
Comte and Lieberman (2000) derive asymptotic normality of the QML-estimator. The asymptotic
distribution of the rescaled QML-estimator is analogous to the univariate case and
discussed in Bollerslev and Wooldridge (1992).
up to order eight,
Comte and Lieberman (2000) derive asymptotic normality of the QML-estimator. The asymptotic
distribution of the rescaled QML-estimator is analogous to the univariate case and
discussed in Bollerslev and Wooldridge (1992).