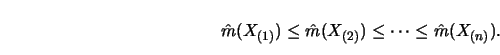
Such a solution exists and can be obtained from the pool adjacent violators algorithm, (Barlow et al. 1972, p. 13; Hanson, Pledger and Wright 1973). The pool-adjacent-violators algorithm (from the left) can be formalized as follows.
Start with ![]() move to the right and stop if the pair
move to the right and stop if the pair
![]() violates the monotonicity constraint, that is,
violates the monotonicity constraint, that is,
![]() Pool
Pool ![]() and the
adjacent
and the
adjacent ![]() by replacing them
by replacing them
both by their average,
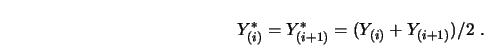
Next check that
![]() . If not, pool
. If not, pool
![]() into
into
one average. Continue to the left
until the monotonicity
requirement is satisfied. Then proceed to the
right. The final
solutions are
![]()
There are four remarkable facts about this solution. First, if the
data are already monotone, then the PAV algorithm will reproduce the data.
Second, since each
![]() is an average of the
observations
near
is an average of the
observations
near ![]() the solution is a step function as in Figure
8.1.
Third, if there are outliers or aberrant observations the
PAV algorithm will produce long, flat levels. Fourth, suppose
the algorithm is
started from the right with the aim of pooling to obtain a decreasing fit
(looking from the right). The fits starting from left and right are different
(Exercise 8.1.1).
Especially the third fact about outlier dependence could be treated by first
smoothing (with a robust technique) and then isotonizing the smooth.
On the other hand, one could also first
apply the PAV algorithm and then smooth the solution.
Hildenbrand and Hildenbrand (1986) applied the first strategy in
nonparametric estimation of Engel curves.
Figure 8.1 shows a spline smooth and a PAV smooth obtained from estimating
the Engel curve of food as a function of income.
the solution is a step function as in Figure
8.1.
Third, if there are outliers or aberrant observations the
PAV algorithm will produce long, flat levels. Fourth, suppose
the algorithm is
started from the right with the aim of pooling to obtain a decreasing fit
(looking from the right). The fits starting from left and right are different
(Exercise 8.1.1).
Especially the third fact about outlier dependence could be treated by first
smoothing (with a robust technique) and then isotonizing the smooth.
On the other hand, one could also first
apply the PAV algorithm and then smooth the solution.
Hildenbrand and Hildenbrand (1986) applied the first strategy in
nonparametric estimation of Engel curves.
Figure 8.1 shows a spline smooth and a PAV smooth obtained from estimating
the Engel curve of food as a function of income.
On the contrary,
Friedman and Tibshirani (1984) proposed smoothing the data first and then
searching for a monotone approximation of the smooth.
This second algorithm can be summarized as follows. First, smooth
![]() on
on ![]() , that is, produce an estimate
, that is, produce an estimate
![]() with a
cross-validated smoothing parameter. Second, find the
monotone function
with a
cross-validated smoothing parameter. Second, find the
monotone function
![]() closest to
closest to
![]() by
means of the PAV algorithm.
Friedman and Tibshirani (1984) gave an example of this
algorithm to find an optimal transformation for a nonparametric version
of the Box-Cox procedure (1964).
by
means of the PAV algorithm.
Friedman and Tibshirani (1984) gave an example of this
algorithm to find an optimal transformation for a nonparametric version
of the Box-Cox procedure (1964).
![\includegraphics[scale=0.2]{ANR8,1.ps}](anrhtmlimg2213.gif)
|
Kelly and Rice (1988) used monotone smoothing in a similar model for
assessment of synergisms. The goal of the nonparametric Box-Cox procedure
is to identify the smooth monotone link function ![]() and the
parameter
and the
parameter ![]() in the model
in the model


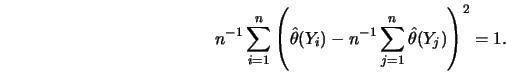
The Box-Cox procedure and a method proposed by Kruskal (1965) are
variants of this procedure. The Box-Cox procedure consists of using
the parametric transformation family
![\includegraphics[scale=0.15]{ANR8,2.ps}](anrhtmlimg2221.gif)
|
Figure 8.3 shows the result of Kruskal's algorithm together with the log-transformation. The transformation suggested by the Kruskal method by construction lacks smoothness, whereas the monotone smooth gives evidence for a log-transformation; see Figure 8.3.
It is, of course, interesting to ask which method is to be preferred in which situation. Should we smooth first and then isotonize the smooth via the PAV algorithm or should we apply the PAV algorithm first and then smooth? Mammen (1987) investigated this question in the fixed design model. His theoretical comparison is given in more detail in the Complements to this section. It is remarkable from Mammen's results that neither method outperforms the other. More precisely, isotonizing the observations first leads to a smaller variance and a larger bias. The Friedman-Tibshirani method can have a smaller MSE but conditions when this will happen are rather complicated and depend on the unknown regression function.
![\includegraphics[scale=0.15]{ANR8,3.ps}](anrhtmlimg2222.gif)
|
Variants of the above methods are monotone median and percentile regression. They have been investigated by Cryer et al. (1972) and Casady and Cryer (1976). Two-dimensional isotonic smoothing is given as algorithm AS 206 in Bril et al. (1984).
The problem
of unimodal smoothing can be related to monotone
smoothing. Suppose that ![]() has a mode at
has a mode at ![]() . This means that
. This means that
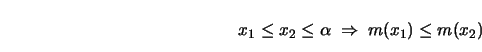
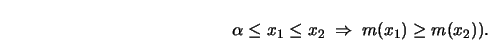
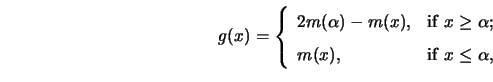
(The problem of ``U-shaped regression" can be defined analogously
by smoothing ![]() .) A possible way of finding an unimodal
smooth is to mirror the observations at possible mode
points and then to find a monotone smooth of the partially mirrored
data.
.) A possible way of finding an unimodal
smooth is to mirror the observations at possible mode
points and then to find a monotone smooth of the partially mirrored
data.
More formally, the unimodal regression problem is to find
a smooth which
minimizes
![]() subject to the restrictions:
subject to the restrictions:
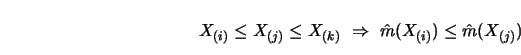
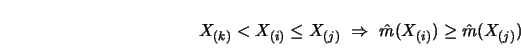
Frisén and Goteborg (1980) proposed treating the index ![]() as a parameter, and then, solving for each
as a parameter, and then, solving for each ![]() , a monotone increasing
smoothing problem for the data
, a monotone increasing
smoothing problem for the data
![]() and a
monotone decreasing smoothing problem for the data
and a
monotone decreasing smoothing problem for the data
![]() . Then one chooses the empirical mode
. Then one chooses the empirical mode
![]() that leads to the lowest residual sum of squares.
that leads to the lowest residual sum of squares.
Hildenbrand
and Hildenbrand (1986) report that the above algorithm tends to produce
a spike at ![]() . For this reason it makes sense to first estimate
the mode by
. For this reason it makes sense to first estimate
the mode by
![]() in a ``presmoothing step."
In a second step,
one then considers unimodal regression with pre-estimated mode
in a ``presmoothing step."
In a second step,
one then considers unimodal regression with pre-estimated mode ![]() by mirroring the right half of the data at the empirical mode
by mirroring the right half of the data at the empirical mode ![]() This algorithm has been applied to the potato versus net income
example; see Figure 8.4.
This algorithm has been applied to the potato versus net income
example; see Figure 8.4.
![\includegraphics[scale=0.2]{ANR8,4.ps}](anrhtmlimg2236.gif)
|
Exercises
Consider the following algorithm for PAV smoothing. The input is contained in
Y[1![]() N], the isotonic output in R[1
N], the isotonic output in R[1![]() N].
Explain the role of the vector NEXT(I)!
N].
Explain the role of the vector NEXT(I)!
DO I![]() N TO 1 by -1;
N TO 1 by -1;
R(I) ![]() Y(I); NEXT(I)
Y(I); NEXT(I) ![]() I+1;
I+1;
DO WHILE (NEXT(I) ![]() N)
IF R(I)*(NEXT(NEXT(I))-NEXT(I))
N)
IF R(I)*(NEXT(NEXT(I))-NEXT(I))
![]() R(NEXT(I))*(NEXT(I)
R(NEXT(I))*(NEXT(I)![]() ) THEN LEAVE; (this loop)
) THEN LEAVE; (this loop)
R(I) ![]() R(I) + R(NEXT(I));
R(I) + R(NEXT(I));
NEXT(I) ![]() NEXT(NEXT(I));
NEXT(NEXT(I));
END;
END;
DO I ![]() 1 REPEAT NEXT(I) UNTIL (NEXT(I)
1 REPEAT NEXT(I) UNTIL (NEXT(I) ![]() N );
N );
IF NEXT(I)-I ![]() 1 THEN DO;
1 THEN DO;
R(I) ![]() R(I)/(NEXT(I)-I);
R(I)/(NEXT(I)-I);
DO I1 ![]() I + 1 TO NEXT(I)
I + 1 TO NEXT(I)![]() ; R(I1)
; R(I1) ![]() R(I); END;
R(I); END;
END;
END;
8.1.2Explain qualitatively when you would like to prefer to smooth first and then to isotonize.
8.1.3Calculate the asymptotic MSE from Theorem 8.1.1 in the Complements to this section.
8.1.4Use an asymptotic MSE optimal bandwidth ![]() in 8.1.5.
How does the condition then look?
in 8.1.5.
How does the condition then look?
8.1.5Rewrite the PAV algorithm so that it starts from the right and does pooling while descending. Why is the answer, in general, different from the fit starting from the left?
Let me compare the two proposed methods
30pt to 30ptSISmooth first then Isotonize ,
30pt to 30ptISIsotonize first then Smooth .
Consider the fixed design case. Let ![]() denote the Priestley-Chao
kernel estimator and
denote the Priestley-Chao
kernel estimator and
![]() the variants of it
according to the above two methods. Mammen (1987) showed the following theorem.
the variants of it
according to the above two methods. Mammen (1987) showed the following theorem.
30pt
to 30pt(A1)
![]() ,
,
30pt
to 30pt(A2)
![]() for
for ![]() small enough,
small enough,
30pt
to 30pt(A3)
![]() ,
, ![]() ,
,
![]() ,
, ![]() .
.
Then
![\begin{eqnarray*}
\beta_n &=& (1/2) m''(0) d_K n^{-2/5},\cr
\delta_n &=& c_3 \si...
...c_K^{(1)} c_K^{-1} n^{-4/15},\cr
c_K^{(1)} &= &\int [K'(u)]^2 du.\end{eqnarray*}](anrhtmlimg2256.gif)
The theorem can be used to calculate the asymptotic MSE, see Exercise
8.1.1.
Mammen reports that simulations show that ![]() . Therefore, the
method IS leads to a variance reduction and a larger bias. Furthermore, it
can be computed from 8.1.38.1.4 that
. Therefore, the
method IS leads to a variance reduction and a larger bias. Furthermore, it
can be computed from 8.1.38.1.4 that
![]() has a smaller MSE
than
has a smaller MSE
than
![]() if and only if
if and only if
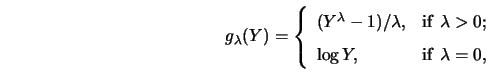
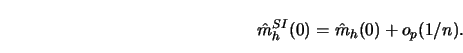
![\begin{displaymath}
{ h^5 d_K [m''(0)]^2 \over \sigma^2 c_K^{(1)} }
< { 2c_2 - c_1 \over 2c_3 }\cdotp
\end{displaymath}](anrhtmlimg2264.gif)