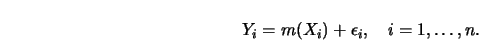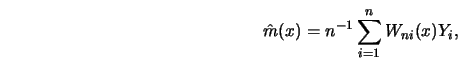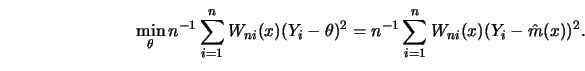If ![]() is believed to be smooth, then the observations at
is believed to be smooth, then the observations at ![]() near
near
![]() should contain information about the value of
should contain information about the value of ![]() at
at ![]() . Thus it should
be possible to use something like a local average of the data near
. Thus it should
be possible to use something like a local average of the data near ![]() to
construct an estimator of
to
construct an estimator of ![]() .
.
R. Eubank (1988, p. 7)
Smoothing of a dataset
![]() involves the
approximation of the mean response curve
involves the
approximation of the mean response curve ![]() in the regression relationship
in the regression relationship
The functional of interest could be the regression curve itself, certain
derivatives of it or functions of derivatives such as extrema or inflection
points. The data collection could have been performed in several ways. If
there are repeated observations at a fixed point ![]() estimation of
estimation of ![]() can be done by using just the average of the corresponding
can be done by using just the average of the corresponding ![]() -values. In the
majority of cases though repeated responses at a given
-values. In the
majority of cases though repeated responses at a given ![]() cannot be obtained.
In most studies of a regression relationship (2.0.1), there is just a single
response variable
cannot be obtained.
In most studies of a regression relationship (2.0.1), there is just a single
response variable ![]() and a single predictor variable
and a single predictor variable ![]() which may be a
vector in
which may be a
vector in ![]() . An example from biometry is the height growth experiment
described in 1. In a frequently occurring economic example the
variable
. An example from biometry is the height growth experiment
described in 1. In a frequently occurring economic example the
variable ![]() is a discrete variable (indicating some choice) and the vector
is a discrete variable (indicating some choice) and the vector
![]() denotes an influential variable; see Manski (1989).
denotes an influential variable; see Manski (1989).
There are other restrictions on the possibility of multiple data recording. An
experimental setup may not be repeatable since the object under consideration
gets demolished. This is often the case in biomechanical experiments.
Kallieris and Mattern (1984) describe a side impact study where acceleration
curves from postmortal test objects have been recorded in simulated crashes.
Also, budget restrictions and ethical considerations may force the
experimenter to adopt a single experimental setup. One can certainly imagine
situations in which it is too expensive to carry out more than one experiment
for a specific level of the influential variable ![]() . This raises the
following question:
. This raises the
following question:
If there are no repeated observations how can we possibly gather information about the regression curve?
In the trivial case in which ![]() is a constant, estimation of
is a constant, estimation of ![]() reduces
to the point estimation of location, since an average over the response
variables
reduces
to the point estimation of location, since an average over the response
variables ![]() yields an estimate of
yields an estimate of ![]() . In practical studies though it is
unlikely (or not believed, since otherwise there is not quite a response to
study) that the regression curve is constant. Rather the assumed curve is
modeled as a smooth continuous function of a particular structure which is
``nearly constant'' in small neighborhoods around
. In practical studies though it is
unlikely (or not believed, since otherwise there is not quite a response to
study) that the regression curve is constant. Rather the assumed curve is
modeled as a smooth continuous function of a particular structure which is
``nearly constant'' in small neighborhoods around ![]() . It is difficult to
judge from looking even at a two dimensional scatter plot whether a regression
curve is locally constant. Recall for instance the binary response example as
presented in Figure 1.8 It seems to be hard to decide from just looking at
this data set whether the regression function
. It is difficult to
judge from looking even at a two dimensional scatter plot whether a regression
curve is locally constant. Recall for instance the binary response example as
presented in Figure 1.8 It seems to be hard to decide from just looking at
this data set whether the regression function ![]() is a smooth function.
However, sometimes a graphical inspection of the data is helpful. A look at a
two-dimensional histogram or similar graphical enhancements can give support
for such a smoothness assumption. One should be aware though that even for
large data sets small jumps in
is a smooth function.
However, sometimes a graphical inspection of the data is helpful. A look at a
two-dimensional histogram or similar graphical enhancements can give support
for such a smoothness assumption. One should be aware though that even for
large data sets small jumps in ![]() may occur and a smooth regression curve is
then only an approximation to the true curve.
may occur and a smooth regression curve is
then only an approximation to the true curve.
In Figure 2.1 a scatter plot of a data set of expenditure for food ![]() and
income
and
income ![]() is shown. This scatter plot of the entire data looks unclear,
especially in the lower left corner.
is shown. This scatter plot of the entire data looks unclear,
especially in the lower left corner.
![\includegraphics[scale=0.7]{ANRfoodscat.ps}](anrhtmlimg153.gif)
|
It is desirable to have a technique which helps us in seeing where the data concentrate. Such an illustration technique is the sunflower plot (Cleveland and McGill; 1984) : Figure 2.2 shows the food versus net income example.
![\includegraphics[scale=0.7]{ANRfoodsun.ps}](anrhtmlimg154.gif)
|
The sunflower plot is constructed by defining a net of squares covering the
![]() space and counting the number of observations that fall into the
disjoint squares. The number of petals of the sunflower blossom corresponds to
the number of observations in the square around the sunflower: It represents
the empirical distribution of the data. The sunflower plot of food versus
net income shows a concentration of the data around an increasing band of
densely packed ``blossoms''. The shape of this band seems to suggest smooth
dependence of the average response curve on
space and counting the number of observations that fall into the
disjoint squares. The number of petals of the sunflower blossom corresponds to
the number of observations in the square around the sunflower: It represents
the empirical distribution of the data. The sunflower plot of food versus
net income shows a concentration of the data around an increasing band of
densely packed ``blossoms''. The shape of this band seems to suggest smooth
dependence of the average response curve on ![]() .
.
Another example is depicted in Figure 2.3, where heights and ages of a group of persons are shown.
![\includegraphics[scale=0.2]{ANR2,3.ps}](anrhtmlimg158.gif)
|
The lengths of the needles in Figure 2.3 correspond to the counts of
observations that fall into a net of squares in ![]() space. The relation to
the sunflower plot is intimate: the needle length is equivalent to the number
of petals in the sunflower. In this height versus age data set, the average
response curve seems to lie in a band that rises steeply with age (up to about
10,000-15,000 days) and then slowly decreases as the individuals get older.
space. The relation to
the sunflower plot is intimate: the needle length is equivalent to the number
of petals in the sunflower. In this height versus age data set, the average
response curve seems to lie in a band that rises steeply with age (up to about
10,000-15,000 days) and then slowly decreases as the individuals get older.
For the above illustrations, the food versus income and height versus age
scatter plots our eyes in fact smooth: The data look more concentrated in a
smooth band (of varying extension). This band has no apparent jumps or rapid
local fluctuations. A reasonable approximation to the regression curve ![]() will therefore be any representative point close to the center of this band of
response variables. A quite natural choice is the mean of the response
variables near a point
will therefore be any representative point close to the center of this band of
response variables. A quite natural choice is the mean of the response
variables near a point ![]() . This ``local average'' should be constructed in
such a way that it is defined only from observations in a small neighborhood
around
. This ``local average'' should be constructed in
such a way that it is defined only from observations in a small neighborhood
around ![]() , since
, since ![]() -observations from points far away from
-observations from points far away from ![]() will have, in
general, very different mean values. This local averaging procedure
can be viewed as the basic idea of smoothing. More formally this procedure can
be defined as
will have, in
general, very different mean values. This local averaging procedure
can be viewed as the basic idea of smoothing. More formally this procedure can
be defined as
where
![]() denotes a sequence of weights which may depend
on the whole vector
denotes a sequence of weights which may depend
on the whole vector
![]() .
.
Every smoothing method to be described here is, at least asymptotically, of
the form (2.0.2). Quite often the regression estimator ![]() is just
called a smoother and the outcome of the smoothing procedure is simply
called the smooth (Tukey; 1977). A smooth of the potato data set has
already been given in Figure 1.2. A very simple smooth can be obtained by
defining the weights as constant over adjacent intervals. This procedure is
similar to the histogram, therefore Tukey (1961) called it the regressogram. A regressogram smooth for the potato data is given in Figure
2.4
The weights
is just
called a smoother and the outcome of the smoothing procedure is simply
called the smooth (Tukey; 1977). A smooth of the potato data set has
already been given in Figure 1.2. A very simple smooth can be obtained by
defining the weights as constant over adjacent intervals. This procedure is
similar to the histogram, therefore Tukey (1961) called it the regressogram. A regressogram smooth for the potato data is given in Figure
2.4
The weights
![]() have been defined here as
constant over blocks of length 0.6 starting at
have been defined here as
constant over blocks of length 0.6 starting at ![]() . Compared to the sunflower
plot (Figure 1.1) of this data set a considerable amount of noise reduction
has been achieved and the regressogram smooth is again quite different from
the linear fit.
. Compared to the sunflower
plot (Figure 1.1) of this data set a considerable amount of noise reduction
has been achieved and the regressogram smooth is again quite different from
the linear fit.
![\includegraphics[scale=0.7]{ANRpotaregress.ps}](anrhtmlimg163.gif)
|
Special attention has to be paid to the fact that smoothers, by definition,
average over observations with different mean values. The amount of averaging
is controlled by the weight sequence
![]() which is tuned
by a smoothing parameter. This smoothing parameter regulates the size of
the neighborhood around
which is tuned
by a smoothing parameter. This smoothing parameter regulates the size of
the neighborhood around ![]() . A local average over too large a neighborhood
would cast away the good with the bad. In this situation an extremely
``oversmooth'' curve would be produced, resulting in a biased estimate
. A local average over too large a neighborhood
would cast away the good with the bad. In this situation an extremely
``oversmooth'' curve would be produced, resulting in a biased estimate
![]() .
On the other hand, defining the smoothing parameter so that it corresponds to
a very small neighborhood would not sift the chaff from the wheat. Only a
small number of observations would contribute nonnegligibly to the estimate
.
On the other hand, defining the smoothing parameter so that it corresponds to
a very small neighborhood would not sift the chaff from the wheat. Only a
small number of observations would contribute nonnegligibly to the estimate
![]() at
at ![]() making it very rough and wiggly. In this case the variability
of
making it very rough and wiggly. In this case the variability
of ![]() would be inflated. Finding the choice of smoothing parameter that
balances the trade-off between oversmoothing and undersmoothing is called the smoothing parameter selection problem.
would be inflated. Finding the choice of smoothing parameter that
balances the trade-off between oversmoothing and undersmoothing is called the smoothing parameter selection problem.
To give insight into the smoothing parameter selection problem consider Figure 2.5. Both curves represent nonparametric estimates of the Engel curve, the average expenditure curve as a function of income. The more wiggly curve has been computed using a kernel estimate with a very low smoothing parameter. By contrast, the more flat curve has been computed using a very big smoothing parameter. Which smoothing parameter is correct? This question will be discussed in Chapter 5 .
![\includegraphics[scale=0.7]{ANRpotasmooth.ps}](anrhtmlimg167.gif)
|
There is another way of looking at the local averaging formula
(2.0.2).
Suppose that the weights
![]() are positive and sum to one for all
are positive and sum to one for all
![]() , that is,
, that is,

Then ![]() is a least squares estimate at point
is a least squares estimate at point ![]() since we can
write
since we can
write ![]() as a solution to the following minimization problem:
as a solution to the following minimization problem:
This formula says that the residuals are weighted quadratically. In other words:
The basic idea of local averaging is equivalent to the procedure of finding a local weighted least squares estimate.
It is well known from the theory of robustness that a wild spike in the raw
data affects the small sample properties of local least squares estimates.
When such outliers (in ![]() -direction) are present, better performance can be
expected from robust smoothers, which give less weight to large
residuals. These smoothers are usually defined as nonlinear functions of the
data and it is not immediately clear how they fit into the framework of local
averaging. In large data sets, however, they can be approximately represented
as a weighted average with suitably nonlinearly transformed residuals; see
Chapter 6. The general basic idea of weighted averaging expressed by formula
(2.0.2) thus applies also to these nonlinear smoothing techniques.
-direction) are present, better performance can be
expected from robust smoothers, which give less weight to large
residuals. These smoothers are usually defined as nonlinear functions of the
data and it is not immediately clear how they fit into the framework of local
averaging. In large data sets, however, they can be approximately represented
as a weighted average with suitably nonlinearly transformed residuals; see
Chapter 6. The general basic idea of weighted averaging expressed by formula
(2.0.2) thus applies also to these nonlinear smoothing techniques.