Several well-designed software technologies are available for utilizing parallel computing hardware. Note that each of them is suitable for a specific hardware architecture.
In this section, we use as an example the calculation of the value of
![]() by the approximation formula
by the approximation formula
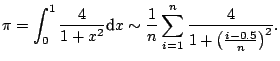 |
The case ![]() is illustrated in Fig. 8.6.
is illustrated in Fig. 8.6.
A C program to calculate the last term is given in Listing 1. The main calculation is performed in the for statement, which is easily divided into parallel-executed parts; this is an example of an embarrassingly parallel problem. We show several parallel computing techniques by using this example in this section. We choose this simple example to keep the length of following example source codes as small as possible and to give a rough idea of parallel computing techniques. Note that this example is so simple that only the most fundamental parts of each technique will be used and explained. Many important details of each technique are left to references.
#include <stdio.h>
main(int argc, char **argv)
{
int n, i;
double d, s, x, pi;
n = atoi(argv[1]);
d = 1.0/n;
s = 0.0;
for (i=1; i<=n; i++){
x = (i-0.5)*d;
s += 4.0/(1.0+x*x);
}
pi = d*s;
printf("pi=%.15f\n", pi);
}
Modern operating systems have multi-user and multi-task features even on a single processor; many users can use a single processor system and can seemingly perform many tasks at the same time. This is usually realized by multi-process mechanisms ([36]).
UNIX-like operating systems are based on the notion of a process. A process is an entity that executes a given piece of code, has its own execution stack, its own set of memory pages, its own file descriptors table and a unique process ID. Multiprocessing is realized by time-slicing the use of the processor. This technology repeatedly assigns the processor to each process for a short time. As the processor is very fast compared with human activities, it looks as though it is working simultaneously for several users. In shared memory systems, multiprocessing may be performed simultaneously on several processors. Multiprocessing mechanisms are a simple tool for realizing parallel computing.
We can use two processes to calculate the for loop in Listing 1, by using the process-handling functions of UNIX operating systems: fork(), wait() and exit(). The function fork() creates a new copy process of an existing process. The new process is called the child process, and the original process is called the parent. The return value from fork() is used to distinguish the parent from the child; the parent receives the child's process id, but the child receives zero. By using this mechanism, an if statement, for example, can be used to prescribe different work for the parent and the child. The child process finishes by calling the exit() function, and the parent process waits for the end of the child process by using the wait() function. This fork-join mechanism is fundamental to the UNIX operating system, in which the first process to start invokes another process by forking. This procedure is repeated until enough processes are invoked. Although this mechanism was originally developed for one processor and a time-slicing system, UNIX operating systems that support shared memory can run processes on different processors simultaneously.
As processes are independent and share only a limited set of common resources automatically, we must write a program for information exchange among processes. In our example, we use functions to handle shared memory segments: shmget(), shmat() and shmctl(). shmget() allocates a shared memory segment, shmat() attaches the shared memory segment to the process, and shmctl() allows the user to set information such as the owner, group and permissions on the shared memory segment. When the parent process uses fork(), the shared memory segment is inherited by the child process and both processes can access it.
Listing 2 shows a two-process version of
Listing 1. In the for statement, the
parent process works for
![]() , while the child
process works for
, while the child
process works for
![]() The child process stores
its result to *shared and the parent process receives
the value and adds it to its own result, then prints the final
result.
The child process stores
its result to *shared and the parent process receives
the value and adds it to its own result, then prints the final
result.
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/shm.h>
main(int argc, char **argv)
{
int n, i;
double d, s, x, pi;
int shmid, iproc;
pid_t pid;
double *shared;
n = atoi(argv[1]);
d = 1.0/n;
shmid = shmget(IPC_PRIVATE,
sizeof(double), (IPC_CREAT | 0600));
shared = shmat(shmid, 0, 0);
shmctl(shmid, IPC_RMID, 0);
iproc = 0;
if ((pid = fork()) == -1) {
fprintf(stderr, "The fork failed!\n");
exit(0);
} else {
if (pid != 0) iproc = 1 ;
}
s = 0.0;
for (i=iproc+1; i<=n; i+=2) {
x = (i-0.5)*d;
s += 4.0/(1.0+x*x);
}
pi = d*s;
if (pid == 0) {
*shared = pi;
exit(0);
} else {
wait(0);
pi = pi + *shared;
printf("pi=%.15f\n", pi);
}
}
Forking, however, is not appropriate for parallel computing. Much time and memory is required to duplicate everything in the parent process. Further, a complete copy is not always required, because, for example, the forked child process starts execution at the point of the fork.
As a process created using the UNIX fork() function is expensive in setup time and memory space, it is sometimes called a ''heavyweight'' process. Often a partial copy of the process is enough and other parts can be shared. Such copies can be realized by a thread or ''lightweight'' process. A thread is a stream of instructions that can be scheduled as an independent unit. It is important to understand the difference between a thread and a process. A process contains two kinds of information: resources that are available to the entire process such as program instructions, global data and working directory, and schedulable entities, which include program counters and stacks. A thread is an entity within a process that consists of the schedulable part of the process.
In a single processor system, threads are executed by time-slicing, but shared memory parallel computers can assign threads to different processors.
There were many thread libraries in the C language for specific shared memory systems. Now, however, the Pthread library is a standard thread library for many systems ([6]). The Pthread API is defined in the ANSI/IEEE POSIX 1003.1-1995 standard, which can be purchased from IEEE.
Listing 3 is an example program to
calculate ![]() by using the Pthread library. The program
creates a thread using the function
pthread_create(), then assigns a unique identifier
to a variable of type pthread_t. The caller provides
a function that will be executed by the thread. The function
pthread_exit() is used to terminate itself. The
function pthread_join() is analogous to
wait() for forking, but any thread may join any other
thread in the process, that is, there is no parent-child
relationship.
by using the Pthread library. The program
creates a thread using the function
pthread_create(), then assigns a unique identifier
to a variable of type pthread_t. The caller provides
a function that will be executed by the thread. The function
pthread_exit() is used to terminate itself. The
function pthread_join() is analogous to
wait() for forking, but any thread may join any other
thread in the process, that is, there is no parent-child
relationship.
As multi-threaded applications execute instructions concurrently, access to process-wide (or interprocess) shared memory requires a mechanism for coordination or synchronization among threads. It is realized by mutual exclusion (mutex) locks. Mutexes furnish the means to guard data structures from concurrent modification. When one thread has locked the mutex, this mechanism precludes other threads from changing the contents of the protected structure until the locker performs the corresponding mutex unlock. Functions pthread_mutex_init(), pthread_mutex_lock() and pthread_mutex_unlock() are used for this purpose.
The compiled executable file is invoked from a command line with two
arguments: n and the number of threads, which is copied to
the global variable num_threads. The ![]() th thread of the function PIworker,
which receives the value
th thread of the function PIworker,
which receives the value ![]() from the original process, calculates
a summation for about n/num_threads times. Each thread
adds its result to a global variable pi. As the variable
pi should not be accessed by more than one thread
simultaneously, this operation is locked and unlocked by the mutex
mechanism.
from the original process, calculates
a summation for about n/num_threads times. Each thread
adds its result to a global variable pi. As the variable
pi should not be accessed by more than one thread
simultaneously, this operation is locked and unlocked by the mutex
mechanism.
#include <stdio.h>
#include <pthread.h>
int n, num_threads;
double d, pi;
pthread_mutex_t reduction_mutex;
pthread_t *tid;
void *PIworker(void *arg)
{
int i, myid;
double s, x, mypi;
myid = *(int *)arg;
s = 0.0;
for (i=myid+1; i<=n; i+=num_threads) {
x = (i-0.5)*d;
s += 4.0/(1.0+x*x);
}
mypi = d*s;
pthread_mutex_lock(&reduction_mutex);
pi += mypi;
pthread_mutex_unlock(&reduction_mutex);
pthread_exit(0);
}
main(int argc, char **argv)
{
int i;
int *id;
n = atoi(argv[1]);
num_threads = atoi(argv[2]);
d = 1.0/n;
pi = 0.0;
id = (int *) calloc(n,sizeof(int));
tid = (pthread_t *) calloc(num_threads,
sizeof(pthread_t));
if(pthread_mutex_init(&reduction_mutex,NULL)) {
fprintf(stderr, "Cannot init lock\n");
exit(0);
};
for (i=0; i<num_threads; i++) {
id[i] = i;
if(pthread_create(&tid[i],NULL,
PIworker,(void *)&id[i])) {
exit(1);
};
};
for (i=0; i<num_threads; i++)
pthread_join(tid[i],NULL);
printf("pi=%.15f\n", pi);
}
We note that it is not easy to write multi-threaded applications in the C language, even if we use the Pthread library. As the Pthread library was added to the C language later, there are no assurances that original basic libraries are ''thread-safe''. The term thread-safe means that a given library function is implemented in such a manner that it can be executed correctly by multiple concurrent threads of execution. We must be careful to use thread-safe functions in multi-thread programming. The Pthread library is mainly used by professional system programmers to support advanced parallel computing technologies such as OpenMP.
The Java language supports threads as one of its essential features ([28]). The Java library provides a Thread class that supports a rich collection of methods: for example, the method start() causes the thread to execute the method run(), the method join() waits for the thread to finish execution. The lock-unlock mechanism can be easily realized by the synchronized declaration. All fundamental libraries are thread-safe. These features make Java suitable for thread programming.
public class PiJavaThread {
int n, numThreads;
double pi = 0.0;
synchronized void addPi(double p) {
pi += p;
}
public PiJavaThread(int nd, int nt) {
n = nd;
numThreads = nt;
Thread threads[] = new Thread[numThreads];
for (int i=0; i<numThreads; i++) {
threads[i] = new Thread(new PIworker(i));
threads[i].start();
}
for (int i=0; i<numThreads; i++) {
try {
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class PIworker implements Runnable {
int myid;
public PIworker(int id) {
myid = id;
}
public void run() {
double d, s, x;
d = 1.0/n;
s = 0.0;
for (int i=myid+1; i<=n; i+=numThreads) {
x = (i-0.5)*d;
s += 4.0/(1.0+x*x);
}
addPi(d*s);
}
}
public static void main(String[] args) {
PiJavaThread piJavaThread
= new PiJavaThread(Integer.parseInt(args[0]),
Integer.parseInt(args[1]));
System.out.println(" pi = " + piJavaThread.pi);
}
}
Listing 4 is an example program to
calculate the value of ![]() using the Java language. This
program is almost the same as the Pthread example. As the
method declaration for addPi() contains the keyword
synchronized, it can be performed by only one thread;
other threads must wait until the addPi() method of
the currently executing thread finishes.
using the Java language. This
program is almost the same as the Pthread example. As the
method declaration for addPi() contains the keyword
synchronized, it can be performed by only one thread;
other threads must wait until the addPi() method of
the currently executing thread finishes.
Although the Java language is designed to be thread-safe and provides several means for thread programming, it is still difficult to write efficient application programs in Java. Java's tools are generally well suited to system programming applications, such as graphical user interfaces and distributed systems, because they provide synchronization operations that are detailed and powerful, but unstructured and complex. They can be considered an assembly language for thread programming. Thus, it is not easy to use them for statistical programming.
OpenMP is a directive-based parallelization technique ([8]) that supports fork-join parallelism and is mainly for shared memory systems. The MP in OpenMP stands for ''Multi Processing''. It supports Fortran (77 and 90), C and C++, and is suitable for numerical calculation, including statistical computing. It is standardized for portability by the OpenMP Architecture Review Board ([29]). The first Fortran specification 1.0 was released in 1997, and was updated as Fortran specification 1.1 in 1999. New features were added as Fortran specification 2.0 in 2000. Several commercial compilers support OpenMP.
We use the Fortran language for our examples in this section,
because Fortran is still mainly used for high-performance
computers focused on large numerical computation. Fortran is
one of the oldest computer languages and has many reliable and
efficient numerical libraries and compilers. The Fortran
program for the simple ![]() computation is shown in
Listing 5.
computation is shown in
Listing 5.
We note that C (and C++) are also used for large numerical computations and are now supported to the same extent as Fortran. The following examples can easily be replaced by C programs (except the HPF examples) but we omit them for space reasons.
integer n, i
double precision d, s, x, pi
write(*,*) 'n?'
read(*,*) n
d = 1.0/n
s = 0.0
do i=1, n
x = (i-0.5)*d
s = s+4.0/(1.0+x*x)
enddo
pi = d*s
write(*,100) pi
100 format(' pi = ', f20.15)
end
We can parallelize this program simply by using OpenMP directives (Listing 6).
integer n, i
double precision d, s, x, pi
write(*,*) 'n?'
read(*,*) n
d = 1.0/n
s = 0.0
!$OMP PARALLEL PRIVATE(x), SHARED(d)
!$OMP& REDUCTION(+: s)
!$OMP DO
do i = 1, n
x = (i-0.5)*d
s = s+4.0/(1.0+x*x)
end do
!$OMP END DO
!$OMP END PARALLEL
pi = d*s
write(*,100) pi
100 format(' pi = ', f20.15)
end
Lines started by !$OMP are OpenMP directives to specify parallel computing. Each OpenMP directive starts with !$OMP, followed by a directive and, optionally, clauses. For example, ''!$OMP PARALLEL'' and ''!$OMP END PARALLEL'' encloses a parallel region and all code lexically enclosed is executed by all threads. The number of threads is usually specified by an environmental variable OMP_NUM_THREADS in the shell environment. We also require a process distribution directive ''!$OMP DO'' and ''!$OMP END DO'' to enclose a loop that is to be executed in parallel. Within a parallel region, data can either be private to each executing thread, or be shared among threads. By default, all data in static extents are shared (an exception is the loop variable of the parallel loop, which is always private). In the example, shared scope is not desirable for x and s, so we use a suitable clause to make them private: ''!$OMP PARALLEL PRIVATE (x, s)''. By default, data in dynamic extent (subroutine calls) are private ( an exception is data with the SAVE attribute), and data in COMMON blocks are shared.
An OpenMP compiler will automatically translate this program into a Pthread program that can be executed by several processors on shared memory systems.
PVM (Parallel Virtual Machine) is one of the first widely used message passing programming systems. It was designed to link separate host machines to form a virtual machine, which is a single manageable computing resource ([11]). It is (mainly) suitable for heterogeneous distributed memory systems. The first version of PVM was written in 1989 at Oak Ridge National Laboratory, but was not released publicly. Version 2 was written at the University of Tennessee Knoxville and released in 1991. Version 3 was redesigned and released in 1993. Version 3.4 was released in 1997. The newest minor version, 3.3.4, was released in 2001 ([30]).
PVM is freely available and portable (available on Windows and several UNIX systems). It is mainly used in Fortran, C and C++, and extended to be used in many other languages, such as Tcl/Tk, Perl and Python.
The PVM system is composed of two parts: a PVM daemon program (pvmd) and libraries of PVM interface routines. Pvmd provides communication and process control between computers. One pvmd runs on each host of a virtual machine. It serves as a message router and controller, and provides a point of contact, authentication, process control and fault detection. The first pvmd (which must be started by the user) is designated the master, while the others (started by the master) are called slaves or workers.
PVM libraries such as libpvm3.a and libfpvm3.a allow a task to interface with the pvmd and other tasks. They contain functions for packing and unpacking messages, and functions to perform PVM calls by using the message functions to send service requests to the pvmd.
Example Fortran programs are in Listings 7 and 8.
program pimaster
include '/usr/share/pvm3/include/fpvm3.h'
integer n, i
double precision d, s, pi
integer mytid,numprocs,tids(0:32),status
integer numt,msgtype,info
character*8 arch
write(*,*) 'n, numprocs?'
read(*,*) n, numprocs
call PVMFMYTID(mytid)
arch = '*'
call PVMFSPAWN('piworker',PVMDEFAULT,arch,
$ numprocs,tids,numt)
if( numt .lt. numprocs) then
write(*,*) 'trouble spawning'
call PVMFEXIT(info)
stop
endif
d = 1.0/n
msgtype = 0
do 10 i=0, numprocs-1
call PVMFINITSEND(PVMDEFAULT,info)
call PVMFPACK(INTEGER4, numprocs, 1, 1, info)
call PVMFPACK(INTEGER4, i, 1, 1, info)
call PVMFPACK(INTEGER4, n, 1, 1, info)
call PVMFPACK(REAL8, d, 1, 1, info)
call PVMFSEND(tids(i),msgtype,info)
10 continue
s=0.0
msgtype = 5
do 20 i=0, numprocs-1
call PVMFRECV(-1,msgtype,info)
call PVMFUNPACK(REAL8,x,1,1,info)
s = s+x
20 continue
pi = d*s
write(*,100) pi
100 format(' pi = ', f20.15)
call PVMFEXIT(info)
end
program piworker
include '/usr/share/pvm3/include/fpvm3.h'
integer n, i
double precision s, x, d
integer mytid,myid,numprocs,msgtype,master,info
call PVMFMYTID(mytid)
msgtype = 0
call PVMFRECV(-1,msgtype,info)
call PVMFUNPACK(INTEGER4, numprocs, 1, 1, info)
call PVMFUNPACK(INTEGER4, myid, 1, 1, info)
call PVMFUNPACK(INTEGER4, n, 1, 1, info)
call PVMFUNPACK(REAL8, d, 1, 1, info)
s = 0.0
do 10 i = myid+1, n, numprocs
x = (i-0.5)*d
s = s+4.0/(1.0+x*x)
10 continue
call PVMFINITSEND(PVMDEFAULT,info)
call PVMFPACK(REAL8, s,1,1, info)
call PVMFPARENT(master)
msgtype = 5
call PVMFSEND(master,msgtype,info)
call PVMFEXIT(info)
end
Listing 7 is the master program, and Listing 8 is the slave program, and its compiled executable file name should be piworker. Both programs include the Fortran PVM header file fpvm3.h.
The first PVM call PVMFMYTID() in the master program informs the pvmd of its existence and assigns a task id to the calling task.
After the program is enrolled in the virtual machine, the master program spawns slave processes by the routine PVMFSPAWN(). The first argument is a string containing the name of the executable file that is to be used. The fourth argument specifies the number of copies of the task to be spawned and the fifth argument is an integer array that is to contain the task ids of all tasks successfully spawned. The routine returns the number of tasks that were successfully created via the last argument.
To send a message from one task to another, a send buffer is created to hold the data. The routine PVMFINITSEND() creates and clears the buffer and returns a buffer identifier. The buffer must be packed with data to be sent by the routine PVMFPACK(). The first argument specifies the type of data to be packed. The second argument is the first item to be packed, the third is the total number of items to be packed and the fourth is the stride to use when packing. A single message can contain any number of different data types; however, we should ensure that the received message is unpacked in the same way it was originally packed by the routine PVMFUNPACK(). The routine PVMFSEND() attaches an integer label of msgtype and sends the contents of the send buffer to the task specified by the first argument.
After the required data have been distributed to each worker process, the master program must receive a partial sum from each of the worker processes by the PVMFRECV() routine. This receives a message from the task specified by the first argument with the label of the second argument and places it into the receive buffer. Note that a value of -1 for an argument will match with any task id and/or label. The master program expects a label value of 5 on messages from the worker tasks.
The unpacking routine PVMFUNPACK() has the same arguments as PVMFPACK(). The second argument shows where the first item unpacked is to be stored.
After the sum has been computed and printed, the master task informs the PVM daemon that it is withdrawing from the virtual machine. This is done by calling the routine PVMFEXIT().
The worker program uses the same PVM routines as the master program. It also uses PVMFPARENT() routine to find the task id of the master task that spawned the current task.
When we compile Fortran PVM codes, we must link in both the PVM Fortran library and the standard PVM library compiled for the target machine architecture. Before executing the program, the executables of the worker program should be available in a specific directory on all the slave nodes. The default authentication is performed by rsh call.
MPI (Message Passing Interface) is the most widely used parallel computing technique. It specifies a library for adding message passing mechanisms to existing languages such as Fortran or C. MPI is mainly used for homogeneous distributed memory systems.
MPI appeared after PVM. PVM was a research effort and did not address the full spectrum of issues: it lacked vendor support, and was not implemented at the most efficient level for a particular hardware. The MPI Forum ([24]) was organized in 1992 with broad participation by vendors (such as IBM, Intel, SGI), portability library writers (including PVM), and users such as application scientists and library writers. MPI-1.1 was released in 1995, MPI-1.2 was released in 1997, and MPI-2 was released in 1997.
MPI-1 has several functions that were not implemented in PVM. Communicators encapsulate communication spaces for library safety. Data types reduce copying costs and permit heterogeneity. Multiple communication modes allow precise buffer management. MPI-1 has extensive collective operations for scalable global communication, and supports process topologies that permit efficient process placement and user views of process layout ([12]).
In MPI-2, other functions were added: extensions to the message passing model, dynamic process management, one-sided operations (remote memory access), parallel I/O, thread support, C++ and Fortran 90 bindings, and extended collective operations ([13]).
MPI implementations are released from both vendors and research groups. MPICH ([25]) and LAM/MPI ([20]) are widely used free implementations.
Although MPI has more than 150 routines, many parallel programs can be written using just six routines, only two of which are non-trivial: MPI_INIT(), MPI_FINALIZE(), MPI_COMM_SIZE(), MPI_COMM_RANK(), MPI_SEND() and MPI_RECV(). An example program is shown in Listing 9.
include 'mpif.h'
integer n, i
double precision d, s, x, pi, temp
integer myid, numprocs, ierr, status(3)
integer sumtag, sizetag, master
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD,numprocs,ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr)
sizetag = 10
sumtag = 17
master = 0
if (myid .eq. master) then
write(*,*) 'n?'
read(*,*) n
do i = 1, numprocs-1
call MPI_SEND(n,1,MPI_INTEGER,i,sizetag,
$ MPI_COMM_WORLD,ierr)
enddo
else
call MPI_RECV(n,1,MPI_INTEGER,master,sizetag,
$ MPI_COMM_WORLD,status,ierr)
endif
d = 1.0/n
s = 0.0
do i = myid+1, n, numprocs
x = (i-0.5)*d
s = s+4.0/(1.0+x*x)
enddo
pi = d*s
if (myid .ne. master) then
call MPI_SEND(pi,1,MPI_DOUBLE_PRECISION,
$ master,sumtag,MPI_COMM_WORLD,ierr)
else
do i = 1, numprocs-1
call MPI_RECV(temp,1,MPI_DOUBLE_PRECISION,
$ i,sumtag,MPI_COMM_WORLD,status,ierr)
pi = pi+temp
enddo
endif
if (myid .eq. master) then
write(*, 100) pi
100 format(' pi = ', f20.15)
endif
call MPI_FINALIZE(ierr)
end
MPI follows the single program-multiple data (SPMD) parallel execution model. SPMD is a restricted version of MIMD in which all processors run the same programs, but unlike SIMD, each processor may take a different flow path in the common program.
If the example program is stored in file prog8.f, typical command lines for executing it are
f77 -o prog8 prog8.f -lmpi
mpirun -np 5 prog8
where the command mpirun starts five copies of
process prog8 simultaneously. All processes
communicate via MPI routines.
The first MPI call must be MPI_INIT(), which initializes the message passing routines. In MPI, we can divide our tasks into groups, called communicators. MPI_COMM_SIZE() is used to find the number of tasks in a specified MPI communicator. In the example, we use the communicator MPI_COMM_WORLD, which includes all MPI processes. MPI_COMM_RANK() finds the rank (the name or identifier) of the tasks running the code. Each task in a communicator is assigned an identifying number from 0 to numprocs-1.
MPI_SEND() allows the passing of any kind of variable, even a large array, to any group of tasks. The first argument is the variable we want to send, the second argument is the number of elements passed. The third argument is the kind of variable, the fourth is the id number of the task to which we send the message, and the fifth is a message tag by which the receiver verifies that it receives the message it expects. Once a message is sent, we must receive it on another task. The arguments of the routine MPI_RECV() are similar to those of MPI_SEND(). When we finish with the message passing routines, we must close out the MPI routines by the call MPI_FINALIZE().
In parallel computing, collective operations often appears. MPI supports useful routines for them. MPI_BCAST distributes data from one process to all others in a communicator. MPI_REDUCE combines data from all processes in a communicator and returns it to one process. In many numerical algorithms, SEND/RECEIVE can be replaced by BCAST/REDUCE, improving both simplicity and efficiency. Listing 9 can be replaced by Listing 10 (some parts of Listing 8 are omitted).
...
master = 0
if (myid .eq. master) then
write(*,*) 'n?'
read(*,*) n
endif
call MPI_BCAST(n,1,MPI_INTEGER,master,
$ MPI_COMM_WORLD,ierr)
d = 1.0/n
s = 0.0
...
enddo
pi = d*s
call MPI_REDUCE(pi,temp,1,MPI_DOUBLE_PRECISION,
$ MPI_SUM,master,MPI_COMM_WORLD,ierr)
pi = temp
if (myid .eq. master) then
write(*, 100) pi
...
In distributed shared memory systems, both OpenMP and MPI can be used together to use all the processors efficiently. Again, Listing 9 can be replaced by Listing 11 (the same parts of Listing 9 are omitted) to use OpenMP.
...
d = 1.0/n
s = 0.0
!$OMP PARALLEL PRIVATE(x), SHARED(d)
!$OMP& REDUCTION(+: s)
!$OMP DO
do i = myid+1, n, numprocs
x = (i-0.5)*d
s = s+4.0/(1.0+x*x)
enddo
!$OMP END DO
!$OMP END PARALLEL
pi = d*s
if (myid .ne. master) then
...
HPF (High Performance Fortran) is a Fortran 90 with further data parallel programming features ([19]). In data parallel programming, we specify which processor owns what data, and the owner of the data does the computation on the data (Owner-computes rule).
Fortran 90 provides many features that are well suited to data parallel programming, such as array processing syntax, new functions for array calculations, modular programming constructs and object-oriented programming features.
HPF adds additional features to enable data parallel programming. We use compiler directives to distribute data on the processors, to align arrays and to declare that a loop can be calculated in parallel without affecting the numerical results. HPF also has a loop control structure that is more flexible than DO, and new intrinsic functions for array calculations.
The High Performance Fortran Forum (HPFF) ([17]) is a coalition of industry, academic and laboratory representatives, and defined HPF 1.0 in 1993. HPF 1.1 was released in 1994 and HPF 2.0 was released in 1997. Several commercial and free HPF compilers are now available.
Listing 12 is an example program for
calculating ![]() in HPF.
in HPF.
integer n, i
double precision d, s, pi
double precision, dimension (:),
$ allocatable :: x, y
!HPF$ PROCESSORS procs(4)
!HPF$ DISTRIBUTE x(CYCLIC) ONTO procs
!HPF$ ALIGN y(i) WITH x(i)
write(*,*) 'n?'
read(*,*) n
allocate(x(n))
allocate(y(n))
d = 1.0/n
!HPF$ INDEPENDENT
FORALL (i = 1:n)
x(i) = (i-0.5)*d
y(i) = 4.0/(1.0 + x(i)*x(i))
end FORALL
pi = d*SUM(y)
write (*, 100) pi
100 format(' pi = ', f20.15)
deallocate(x)
deallocate(y)
end
!HPF$ is used for all HPF compiler directives. We
note that this is a comment to non-HPF compilers and is
ignored by them. The PROCESSORS directive specifies
the shape of the grid of abstract processors. Another example
''!HPF$ PROCESSORS exprocs(6,2)'' specifies a
![]() array of
array of
![]() abstract processors labelled
exprocs.
abstract processors labelled
exprocs.
The DISTRIBUTE directive partitions an array by specifying a regular distribution pattern for each dimension ONTO the arrangement of abstract processors. The CYCLIC pattern spreads the elements one per processor, wrapping around when it runs out of processors, i.e., this pattern distributes the data in the same way that the program in Listing 9 performs. Another pattern is BLOCK, which breaks the array into equal-sized blocks, one per processor. The rank of the abstract processor grid must be equal to the number of distributed axes of the array.
The ALIGN directive is used to specify relationships
between data objects. In the example program, elements of ![]() and
and ![]() that have the same index are placed on the same
processor.
that have the same index are placed on the same
processor.
The INDEPENDENT directive informs the compiler that in the execution of the FORALL construct or the do loop, no iteration affects any other iteration in any way.
The FORALL statement is a data parallel construct that defines the assignment of multiple elements in an array but does not restrict the order of assignment to individual elements. Note that the do loop executes on each element in a rigidly defined order.
The SUM intrinsic function performs reduction on whole arrays.
We may compare HPF with OpenMP, because both systems use compiler directives in a standard language (Fortran) syntax. In OpenMP, the user specifies the distribution of iterations, while in HPF, the user specifies the distribution of data. In other words, OpenMP adopts the instruction parallel programming model while HPF adopts data parallel programming model. OpenMP is suitable for shared memory systems whereas HPF is suitable for distributed memory systems.
![\includegraphics[width=48mm]{text/2-8/Figure6.eps}](img2857.gif)