



Next: 9.6 Metadata and XML
Up: 9. Statistical Databases
Previous: 9.4 Access Methods
Subsections
ETL is a shorthand notation for a workflow of the initial
popularization or a follow-up update of a DW, a data mart or an OLAP
application. In the first step data must be extracted from the various
data sources and temporarily stored in a so-called staging area of
a DWS. Transformation means to modify data, schema and data quality
according to requirement specifications of the DWS. Loading is the
integration of replicated and aggregated data in the DW. As the data
volume may be huge, incremental loading within pre-selected time slots
by means of a bulk loader is appropriate.
Extraction can be triggered by events linked to time and state of
a DBS in operation or can be executed under human control. Mostly
extraction is deferred according to an extraction schedule supplied by
monitoring of the DWS. However, changes of data in the source system
are tracked in real time, if the actuality of data is mandatory for
some decision makers, see Kimball (1996).
As the data sources are generally heterogeneous, the efforts to wrap
single data sources can be enormous. Therefore software companies
defined standard interfaces, which are supported by almost all DBMS
and ETL tools. For example, the OLE database provider for ODBC, see
Microsoft (1998, 2003), Oracle (2003) and IBM (2003).
Transformations are needed to resolve conflicts of schema
and data integration and to improve data quality, see
Chap. III.9.
We first turn to the first type of conflicts. Spaccapietra et
al. (1992) consider four classes of conflicts of schema integration,
which are to be resolved in each case.
- Semantic conflicts exist, if two source schemas refer to the
same object, but the corresponding set of attributes is not identical,
i.e. the class extensions are different. As an example take two customer
files. One record structure includes the attribute name gender, while it is
missing in the other one.
- A second kind of conflict of integration happens if synonyms,
homonyms, different data types, domains or
measurements units exist. For instance, think of the synonym
part/article, a homonym like water/money pool, string/date as a domain,
and Euro/USD. The ambiguity of our natural language becomes clear when one
thinks of the meaning of ''name'' - family name, nickname, former family
name, artist name, friar name, ...
- Schema heterogeneity conflicts appear if the source schemas
differ from the target schema of the DW. For example, sales and departments
can be modeled as two relations Sales and Department of
a relational data model or as a nested relation
Department
 Sales as part of an object oriented
model. Another kind of conflict corresponds to the mapping of local source
keys to global surrogates, see Bauer and Günzel (2001). This problem gets
tightened if entity identification is necessary in order decide whether a pair
of records from two data sources refer to same entity or not. Fellegi and
Sunter (1969) were the first to solve this problem by the record-linkage
technique, which is now considered as a special classification method, see
Neiling (2003).
Sales as part of an object oriented
model. Another kind of conflict corresponds to the mapping of local source
keys to global surrogates, see Bauer and Günzel (2001). This problem gets
tightened if entity identification is necessary in order decide whether a pair
of records from two data sources refer to same entity or not. Fellegi and
Sunter (1969) were the first to solve this problem by the record-linkage
technique, which is now considered as a special classification method, see
Neiling (2003).
- Structural conflicts are present if the representation of an
object is different in two schemas. There may exist only one customer schema
with the attribute gender in order to discriminate between
''males'' and ''females''. Alternatively, there may be two schemas in use,
one linked to ''females'', the other one to ''males''.
The second type of conflicts, i.e., conflicts of data integration,
happens, if false or differently represented data are to be
integrated. False data are generated by erroneous or obsolete
entries. Differences in representation are caused by non- identical
coding like male/female versus 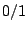 or by different sizes of
rounding-off errors.
or by different sizes of
rounding-off errors.
Next: 9.6 Metadata and XML
Up: 9. Statistical Databases
Previous: 9.4 Access Methods