Given one or more
varsets, we now need to operate on them to produce
combinations of variables. A typical scatterplot of a variable
X against a variable Y, for example, is
built from tuples
![]() that are elements in a set
product. We use graphics algebra on values stored in varsets
to make these tuples. There are three binary operators in this
algebra: cross, nest, and blend.
that are elements in a set
product. We use graphics algebra on values stored in varsets
to make these tuples. There are three binary operators in this
algebra: cross, nest, and blend.
| Country | City | 1980 Population | 2000 Population |
| Japan | Tokyo |
|
|
| India | Mumbai |
|
|
| USA | New York |
|
|
| Nigeria | Lagos |
|
|
| USA | Los Angeles |
|
|
| Japan | Osaka |
|
|
| Philippines | Manila |
|
|
| France | Paris |
|
|
| Russia | Moscow |
|
|
| UK | London |
|
|
| Peru | Lima |
|
|
| USA | Chicago |
|
|
| Iraq | Bagdad |
|
|
| Canada | Toronto |
|
|
| Spain | Madrid |
|
|
| Germany | Berlin |
|
|
| Australia | Melbourne |
|
|
| USA | Melbourne | ||
| USA | Moscow | ||
| USA | Berlin | ||
| USA | Paris | ||
| USA | London | ||
| USA | Toronto | ||
| USA | Manila | ||
| USA | Lima | ||
| USA | Madrid | ||
| USA | Bagdad |
We will define these operators in set notation and illustrate them by using a table of real data. Table 11.1 shows 1980 and 2000 populations for selected world cities. During various periods in US history, it was fashionable to name towns and cities after their European and Asian counterparts. Sometimes this naming was driven by immigration, particularly in the colonial era (New Amsterdam, New York, New London). At other times, exotic names reflected a fascination with foreign travel and culture, particularly in the Midwest (Paris, Madrid). Using a dataset containing namesakes will help reveal some of the subtleties of graphics algebra.
We begin by assuming there are four varsets derived from this table: country, city, pop1980, and pop2000 (we use lower case for varsets when they are denoted by names instead of single letters). Each varset has one column. The varsets resulting from algebraic operations will have one or more columns.
There is one set of objects for all four varsets: ![]() cities. This may or may not be a subset of the domain for the
four associated variables. If we wish to generalize analyses
of this varset to other cities, then the set of possible
objects in these varsets might be a subdomain of the set of
all cities existing in 1980 and 2000. We might even consider
this set of objects to be a subset of all possible cities in
all of recorded history. While these issues might seem more
the province of sampling and generalizability theory, they
affect the design of a graphics system. Databases, for
example, include facilities for semantic integrity
constraints that ensure domain integrity in data
tables. Data-based graphics systems share similar
requirements.
cities. This may or may not be a subset of the domain for the
four associated variables. If we wish to generalize analyses
of this varset to other cities, then the set of possible
objects in these varsets might be a subdomain of the set of
all cities existing in 1980 and 2000. We might even consider
this set of objects to be a subset of all possible cities in
all of recorded history. While these issues might seem more
the province of sampling and generalizability theory, they
affect the design of a graphics system. Databases, for
example, include facilities for semantic integrity
constraints that ensure domain integrity in data
tables. Data-based graphics systems share similar
requirements.
There are sets of values for these varsets. The country varset has country names in the set of values comprising its domain. The definition of the domain of the varset depends on how we wish to use it. For example, we might include spellings of city names in languages other than English. We might also include country names not contained in this particular varset. Such definitions would affect whether we could add new cities to a database containing these data. For pop1980 and pop2000, we would probably make the domain be the set of positive integers.
Cross joins the left argument with the right to produce a set of tuples stored in the multiple columns of the new varset:
![$\displaystyle \notag
{\includegraphics[clip]{text/2-11/k1.eps}} %\hack{\displaybreak}
$](img3018.gif) |
The resulting set of tuples is a subset of the product of the domains of the two varsets. The domain of a varset produced by a cross is the product of the separate domains.
One may think of a cross as a horizontal concatenation of the table representation of two varsets, assuming the rows of each varset are equivalent and in the same order. The following example shows a crossing of two varsets using set notation with simple integer keys for the objects:
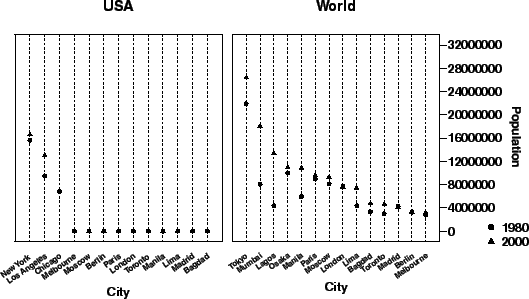
Figure 11.2 shows a graphic based on the
algebraic expression city ![]() pop2000. We
choose the convention of representing the first variable in an
expression on the horizontal axis and the second on the
vertical. We also restrict the domain of pop2000 to
be
pop2000. We
choose the convention of representing the first variable in an
expression on the horizontal axis and the second on the
vertical. We also restrict the domain of pop2000 to
be
![]() .
.
Although most of the US namesake cities have smaller populations, it is not easy to discern them in the graphic. We can separate the US from the other cities by using a variable called group that we derive from the country names. Such a new variable is created easily in a database or statistical transformation language with an expression like
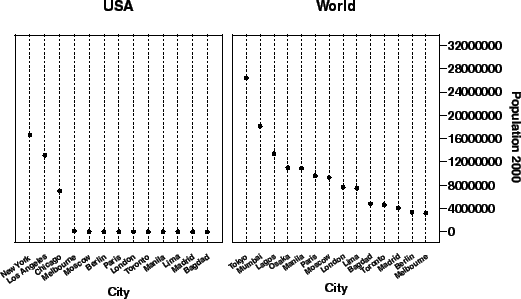
Figure 11.3 shows a graphic based on the
three-dimensional algebraic expression city ![]() pop2000
pop2000 ![]() group. This expression
produces a varset with three columns. The first column is
assigned to the horizontal axis, the second to the vertical,
and the third to the horizontal axis again, which has the
effect of splitting the frame into two frames. This general
pattern of alternating horizontal and vertical roles for the
columns of a varset provides a simple layout scheme for
complex algebraic expressions. We may think of this as
a generalization of the Trellis layout scheme ([5]).
We could, of course, represent this same varset in a 3D plot
projected into 2D, but the default system behavior is to
prefer 2D with recursive partitioning. We will describe this
in more detail in Sect 11.9.
group. This expression
produces a varset with three columns. The first column is
assigned to the horizontal axis, the second to the vertical,
and the third to the horizontal axis again, which has the
effect of splitting the frame into two frames. This general
pattern of alternating horizontal and vertical roles for the
columns of a varset provides a simple layout scheme for
complex algebraic expressions. We may think of this as
a generalization of the Trellis layout scheme ([5]).
We could, of course, represent this same varset in a 3D plot
projected into 2D, but the default system behavior is to
prefer 2D with recursive partitioning. We will describe this
in more detail in Sect 11.9.
Chicago stands out as an anomaly in Fig. 11.3 because of its relatively large population. We might want to sort the cities in a different order for the left panel or eliminate cities not found in the US, but the algebraic expression won't let us do that. Because group is crossed with the other variables, there is only one domain of cities shared by both country groups. If we want to have different domains for the two panels, we need our next operator, nest.
Nest partitions the left argument using the values in the right:
![$\displaystyle \notag
{\includegraphics[]{text/2-11/k2.eps}}$](img3033.gif) |
The following example shows a nesting of two categorical variables:
If A is a continuous variable, then we have something like the following:
The name nest comes from design-of-experiments
terminology. We often use the word within to describe
its effect. For example, if we assess schools and teachers in
a district, then teachers within schools specifies
that teachers are nested within schools. Assuming each teacher
in the district teaches at only one school, we would conclude
that if our data contain two teachers with the same name at
different schools, they are different people. Those familiar
with experimental design may recognize that the expression
![]() is equivalent to the notation
is equivalent to the notation
![]() in a design specification. Both
expressions mean A is nested within B. Statisticians'
customary use of parentheses to denote nesting conceals the
fact that nesting involves an operator, however. Because
nesting is distributive over blending, we have made this
operator explicit and retained the conventional mathematical
use of parentheses in an algebra.
in a design specification. Both
expressions mean A is nested within B. Statisticians'
customary use of parentheses to denote nesting conceals the
fact that nesting involves an operator, however. Because
nesting is distributive over blending, we have made this
operator explicit and retained the conventional mathematical
use of parentheses in an algebra.
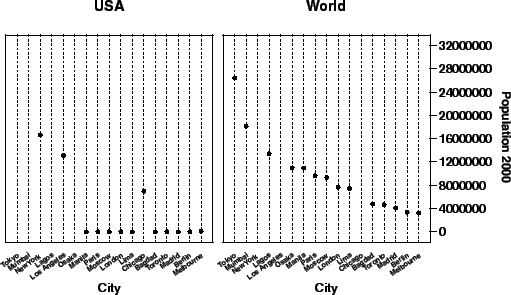
Figure 11.4 shows a graphic based on the
algebraic expression city/group ![]() pop2000. The horizontal axis in each panel now shows
a different set of cities: one for the USA and one for the rest of the
world. This graphic differs from the one in
Fig. 11.3 not only because the axes
look different, but also because the meanings of the cities
in each panels are different. For example, the city named
Paris appears twice in both figures. In
Fig. 11.3, on the one hand, we assume the name
Paris in the left panel is comparable to the name Paris in the
right. That is, it refers to a common name (Paris) occurring in two
different contexts. In Fig. 11.4, on the other
hand, we assume the name Paris references two different cities. They
happen to have the same name, but are not equivalent. Such
distinctions are critical, but often subtle.
pop2000. The horizontal axis in each panel now shows
a different set of cities: one for the USA and one for the rest of the
world. This graphic differs from the one in
Fig. 11.3 not only because the axes
look different, but also because the meanings of the cities
in each panels are different. For example, the city named
Paris appears twice in both figures. In
Fig. 11.3, on the one hand, we assume the name
Paris in the left panel is comparable to the name Paris in the
right. That is, it refers to a common name (Paris) occurring in two
different contexts. In Fig. 11.4, on the other
hand, we assume the name Paris references two different cities. They
happen to have the same name, but are not equivalent. Such
distinctions are critical, but often subtle.
Blend produces a union of varsets:
![$\displaystyle \notag
{\includegraphics[]{text/2-11/k3.eps}}$](img3052.gif) |
In vernacular, we often use the conjunction and to signify that two sets are blended into one (although the word or would be more appropriate technically). For example, if we measure diastolic and systolic blood pressure among patients in various treatment conditions and we want to see blood pressure plotted on a common axis, we can plot diastolic and systolic against treatment. The following example shows a blending of two varsets, using integers for keys:
Figure 11.5 shows an example of a blend using
our cities data. The graphic is based on the algebraic
expression
city ![]() (pop1980+pop2000). The
horizontal axis represents the cities and the vertical axis
represents the two repeated population measures. We have
included different symbol types and a legend to distinguish
the measures. We will see later how shape aesthetics are used
to create this distinction.
(pop1980+pop2000). The
horizontal axis represents the cities and the vertical axis
represents the two repeated population measures. We have
included different symbol types and a legend to distinguish
the measures. We will see later how shape aesthetics are used
to create this distinction.
As with the earlier graphics, we see that it is difficult to
distinguish US and world cities. Figure 11.6
makes the distinction clear by splitting the horizontal axis into two
nested subgroups. The graphic is based on the algebraic expression
(city/group) ![]() (pop1980+pop2000). Once again, the vertical axis
represents the two repeated population measures blended on a single
dimension. We see most
of the cities gaining population between 1980 and 2000.
(pop1980+pop2000). Once again, the vertical axis
represents the two repeated population measures blended on a single
dimension. We see most
of the cities gaining population between 1980 and 2000.
The following rules are derivable from the definitions of the graphics operators:
The identity element for blend is an empty list. Cross and nest have no identity.
Nest takes precedence over cross and blend. Cross takes precedence over blend. This hierarchical order may be altered through the use of parentheses.
Given a table
![]() and a table
and a table
![]() in a database, we can use SQL to
perform the operations in chart algebra. This section outlines
how to do this.
in a database, we can use SQL to
perform the operations in chart algebra. This section outlines
how to do this.
Of course, this operation is inefficient and requires optimization. Alternatively, one can do a simple join and generate the missing tuples with an iterator when needed.
Alternatively, we can accumulate the subset of tuples in a nest operation with a simple join:
If we use this latter method, we must distinguish the entries used for tags and those used for values.
Blend is performed through UNION. If UNION all is not available, we can concatenate key columns to be sure that all rows appear in the result set.
SQL statements can be composed by using the grammar for chart algebra. Compound statements can then be submitted for optimization and execution by a database compiler. Alternatively, pre-optimization can be performed on the chart algebra parse tree object and the optimized parse tree used to generate SQL. Secondary optimization can then be performed by the database compiler.
Research on algebras that could be used for displaying data has occurred in many fields. We will summarize these approaches in separate sections.
The US Bureau of Labor Statistics pioneered a language for laying out tables ([25]). While not a formal algebra, this Table Production Language (TPL) contained many of the elements needed to assemble complex tables. [14] outlined an algebra for displaying relational data; this algebra closely followed TPL, although the latter is not referenced. [42] presented an algebra for structuring tables and graphics.
[28] and [41] developed a language for implementing factorial and nested experimental designs, following [11]. The operators in this language are similar to the cross and nest operators in the present paper. The algebraic design language was implemented in the GENSTAT statistical computer program for generating and analyzing general linear statistical models.
[30] described an algebra for querying OLAP cubes. The result sets from their algebraic expressions could be used for graphic displays. [2] used a similar algebra for statistical modeling of data contained in a cube.
[23] developed an algebra for querying relational databases and generating charts. His general goal was to develop an intelligent system that could offer graphical responses to verbal or structural queries. [32] followed a similar strategy in developing graphical representations of relational data. They extended Mackinlay's and others' ideas by using concepts from computational geometry.
A parse tree for a given algebraic expression maps nicely to XML in a manner similar to the way MathML (http://www.w3.org/TR/MathML2/) is defined. We have developed an implementation, called VizML (http://xml.spss.com/visualization), that includes not only the algebraic components of the specification, but also the aesthetic and geometric aspects. Ultimately, VizML makes it possible to embed chart algebraic operations in a database.
![\includegraphics[width=90mm]{text/2-11/figure1.eps}](img3029.gif)
![\includegraphics[width=100mm]{text/2-11/figure4.eps}](img3058.gif)