We now turn to the problem of estimating the
marginal effects of the regressors ![]() . The marginal effect of an
explanatory variable tells how
. The marginal effect of an
explanatory variable tells how ![]() changes on average if this
variable is varying. In other words, the marginal effect
represents the conditional expectation
changes on average if this
variable is varying. In other words, the marginal effect
represents the conditional expectation
![]() where the expectation is not only taken on the error distribution
but also on all other regressors. (Note, that we usually suppressed
the
where the expectation is not only taken on the error distribution
but also on all other regressors. (Note, that we usually suppressed
the
![]() in all expectations up to now. This is the only
case where we need to explicitely mention on which distribution
the expectation is calculated.)
in all expectations up to now. This is the only
case where we need to explicitely mention on which distribution
the expectation is calculated.)
As already indicated, in case of true additivity
the marginal effects correspond exactly to the additive
component functions ![]() .
The estimator here is based on an integration idea, coming
from the following observation. Denote by
.
The estimator here is based on an integration idea, coming
from the following observation. Denote by ![]() the marginal
density of
the marginal
density of ![]() . We have from
(8.2)
. We have from
(8.2)
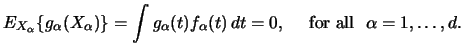
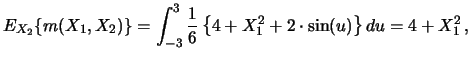
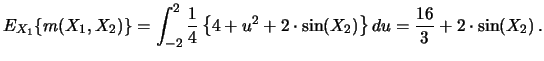
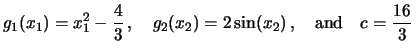
Many extensions and modifications of the integration approach have been developed recently. We consider now the simultaneous estimation of both the functions and their derivatives by combining the procedure with a local polynomial approach (Subsections 8.2.1, 8.2.2) and the estimation of interaction terms (Subsection 8.2.3).
In order to estimate the marginal effect
![]() ,
equation (8.12) suggests the following idea:
First estimate the function
,
equation (8.12) suggests the following idea:
First estimate the function
![]() with
a multidimensional pre-smoother
with
a multidimensional pre-smoother
![]() , then
integrate out the variables different from
, then
integrate out the variables different from ![]() . In the
estimation procedure integration can be replaced by averaging
(over the directions not of interest,
i.e.
. In the
estimation procedure integration can be replaced by averaging
(over the directions not of interest,
i.e.
![]() ) resulting in
) resulting in
Note that to get the marginal effects, we just integrate
![]() over all other (the nuisance) directions
over all other (the nuisance) directions
![]() .
In case of additivity these marginal
effects are the additive component functions
.
In case of additivity these marginal
effects are the additive component functions ![]() plus the constant
plus the constant ![]() .
As for backfitting, the constant
.
As for backfitting, the constant ![]() can be estimated consistently by
can be estimated consistently by
![]() at
at ![]() -rate. Hence,
a possible estimate for
-rate. Hence,
a possible estimate for ![]() is
is
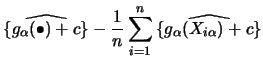 |
|||
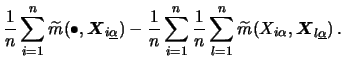 |
(8.15) |
It remains to discuss how to obtain a reasonable pre-estimator
![]() . Principally
this could be any multivariate nonparametric estimator. We
make use here of a special type of multidimensional local linear kernel
estimators, cf. Ruppert & Wand (1994) and
Severance-Lossin & Sperlich (1999).
This estimator is given by minimizing
. Principally
this could be any multivariate nonparametric estimator. We
make use here of a special type of multidimensional local linear kernel
estimators, cf. Ruppert & Wand (1994) and
Severance-Lossin & Sperlich (1999).
This estimator is given by minimizing
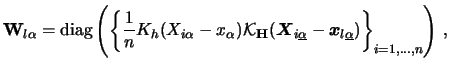
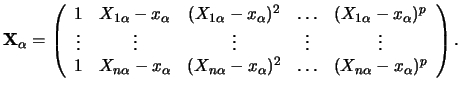
To derive asymptotic properties of these estimators
the concept of equivalent kernels is used, see e.g.
Ruppert & Wand (1994). The main idea is that the local
polynomial smoother of degree ![]() is asymptotically equivalent
(i.e. has the same leading term) to a kernel estimator using a
higher order kernel given by
is asymptotically equivalent
(i.e. has the same leading term) to a kernel estimator using a
higher order kernel given by
We now extend the marginal integration method to the estimation of
derivatives of the functions
![]() .
For additive linear functions their
first derivatives are constants and so all higher order
derivatives vanish. However, very often in economics the
derivatives of the marginal effects are of essential interest,
e.g. to determine the elasticities or returns to scale as in
Example 8.5.
.
For additive linear functions their
first derivatives are constants and so all higher order
derivatives vanish. However, very often in economics the
derivatives of the marginal effects are of essential interest,
e.g. to determine the elasticities or returns to scale as in
Example 8.5.
To estimate the derivatives of the additive components,
we do not need any further extension of our method, since using a local
polynomial estimator of order ![]() for the pre-estimator
for the pre-estimator
![]() provides us simultaneously with both component
functions and derivative estimates up to degree
provides us simultaneously with both component
functions and derivative estimates up to degree ![]() . The
reason is that the optimal
. The
reason is that the optimal ![]() in equation (8.16)
is an estimate for
in equation (8.16)
is an estimate for
![]() , provided that dimension
, provided that dimension ![]() is separable from the others. In
case of additivity this is automatically given.
is separable from the others. In
case of additivity this is automatically given.
Thus, we can use
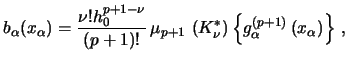
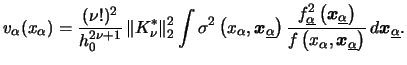
Additionally, for the regression function estimate constructed by
the additive component estimates
![]() and
and
![]() , i.e.
, i.e.
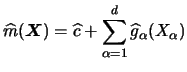
In the following example we illustrate the smoothing
properties of this estimator for ![]() and
and ![]() .
.
![\includegraphics[width=1.4\defpicwidth]{SPMdemoi1.ps}](spmhtmlimg2363.gif)
|
As pointed out before, marginal integration estimates marginal effects.
These are identical to the additive components, if the model is truly
additive. But what happens if the underlying model is not purely additive?
How do the estimators behave when we have
some interaction between explanatory variables,
for example given by an additional term
![]() ?
?
An obvious weakness of the truly additive model is that those interactions are completely ignored, and in certain econometric contexts -- production function modeling being one of them -- the absence of interaction terms has often been criticized. For that reason we will now extend the regression model by pairwise interactions resulting in
For the marginal integration estimator bivariate interaction terms have been studied in Sperlich et al. (2002). They provide asymptotic properties and additionally introduce test procedures to check for significance of the interactions. In the following we will only sketch the construction of the relevant estimation procedure and its application. For the theoretical results we remark that they are higher dimensional extensions of Theorem 8.3 and refer to the above mentioned article.
For the estimation of (8.20) by marginal integration we have to extend our identification condition
As before, equations (8.21) and (8.22)
should not be considered as restrictions. It is
always possible to shift the functions
![]() and
and
![]() in the vertical direction without changing the functional
forms or the overall regression function. Moreover, all models of the
form (8.20) are equivalent to exactly one model satisfying
(8.21) and (8.22).
in the vertical direction without changing the functional
forms or the overall regression function. Moreover, all models of the
form (8.20) are equivalent to exactly one model satisfying
(8.21) and (8.22).
According to the definition of
![]() , let
, let
![]() now denote the
now denote the ![]() -dimensional random
variable obtained by removing
-dimensional random
variable obtained by removing ![]() and
and ![]() from
from
![]() . With some abuse of notation we will write
. With some abuse of notation we will write
![]() to
highlight the directions in
to
highlight the directions in ![]() -dimensional space represented by the
-dimensional space represented by the ![]() and
and ![]() coordinates. We denote the marginal densities of
coordinates. We denote the marginal densities of
![]() ,
,
![]() and
and
![]() by
by
![]() ,
,
![]() , and
, and
![]() , respectively.
, respectively.
Again consider marginal integration as used before
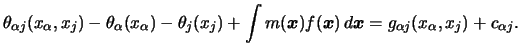
Using the same estimation procedure as described above,
i.e., replacing the expectations by averages and the function ![]() by an appropriate pre-estimator, we get estimates
for
by an appropriate pre-estimator, we get estimates
for
![]() and for the
interaction terms
and for the
interaction terms
![]() . For the ease of notation we
give only the formula for
. For the ease of notation we
give only the formula for ![]() , i.e., the local linear estimator, in the
pre-estimation step. We obtain
, i.e., the local linear estimator, in the
pre-estimation step. We obtain
| (8.25) |
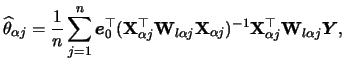
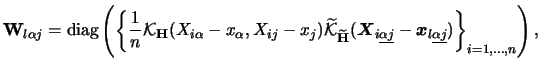
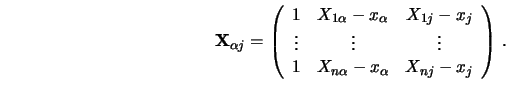
Finally, let us turn to an example, which presents the application of marginal integration estimation, derivative (elasticity) estimation and allows us to illustrate the use of interaction terms.
We use a subset of ![]() observations of an original
data set of more than 1,000 Wisconsin farms collected by the Farm Credit
Service of St. Paul, Minnesota in 1987. Severance-Lossin & Sperlich (1999)
removed outliers and incomplete records and selected farms which only
produced animal outputs.
The data consist of farm level inputs and outputs measured in dollars.
In more detail, output
observations of an original
data set of more than 1,000 Wisconsin farms collected by the Farm Credit
Service of St. Paul, Minnesota in 1987. Severance-Lossin & Sperlich (1999)
removed outliers and incomplete records and selected farms which only
produced animal outputs.
The data consist of farm level inputs and outputs measured in dollars.
In more detail, output ![]() is livestock, and the input variables are
is livestock, and the input variables are
![\includegraphics[width=1.4\defpicwidth]{SPMfafam.ps}](spmhtmlimg2393.gif)
![\includegraphics[width=1.4\defpicwidth]{SPMfahir.ps}](spmhtmlimg2394.gif)
![\includegraphics[width=1.4\defpicwidth]{SPMfamis.ps}](spmhtmlimg2395.gif)
|
![\includegraphics[width=1.43\defpicwidth]{SPMfaani.ps}](spmhtmlimg2396.gif)
![\includegraphics[width=1.43\defpicwidth]{SPMfaass.ps}](spmhtmlimg2397.gif)
|
A purely additive model (ignoring any possible interaction) is of the form
The results are given in Figures 8.5, 8.6.
We use (product) Quartic kernels for all dimensions
and bandwidths proportional to the standard deviation
of ![]() (
(
![]() ,
,
![]() ). It is known that
the integration estimator is quite robust against different
choices of bandwidths, see e.g. Sperlich et al. (1999).
). It is known that
the integration estimator is quite robust against different
choices of bandwidths, see e.g. Sperlich et al. (1999).
To highlight the shape of the estimates we display the main part
of the point clouds including the function estimates. The graphs
give some indication of nonlinearity, in particular
for ![]() ,
, ![]() and
and ![]() .
The derivatives seem to indicate that the
elasticities for these inputs increase and could finally lead to
increasing returns to scale. Note that for all dimensions
(especially where the mass of the observations is located) the
nonparametric results differ a lot from the parametric case. An
obvious conclusion from the economic point of view is
that for instance larger farms are more productive (intuitively
quite reasonable).
.
The derivatives seem to indicate that the
elasticities for these inputs increase and could finally lead to
increasing returns to scale. Note that for all dimensions
(especially where the mass of the observations is located) the
nonparametric results differ a lot from the parametric case. An
obvious conclusion from the economic point of view is
that for instance larger farms are more productive (intuitively
quite reasonable).
In Figures 8.7 to 8.8 we present the estimates
of the bivariate interaction terms
![]() . For their
estimation and graphical presentation we trimmed the data by
removing
. For their
estimation and graphical presentation we trimmed the data by
removing ![]() of the most extreme observations. Again
Quartic kernels were used, here with
bandwidths
of the most extreme observations. Again
Quartic kernels were used, here with
bandwidths
![]() and
and
![]() as above.
as above.
Obviously, often it is hard to interpret those interaction terms.
But as long as we can visualize relationships a careful
interpretation can be tried. Sperlich et al. (2002) find
that a weak form of interaction is present. The variable ![]() (family labor)
plays an important role in the interactions, especially
(family labor)
plays an important role in the interactions, especially
![]() (family labor and miscellaneous inputs),
(family labor and miscellaneous inputs),
![]() (family labor and intermediate run assets) and
(family labor and intermediate run assets) and ![]() (miscellaneous inputs and intermediate run assets) should be
taken into account.
(miscellaneous inputs and intermediate run assets) should be
taken into account. ![]()
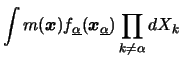
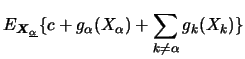
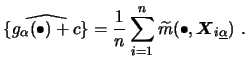
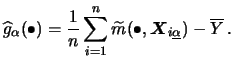
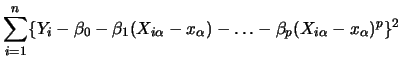
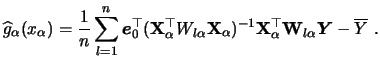
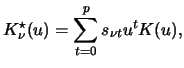
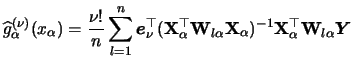
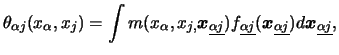
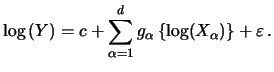
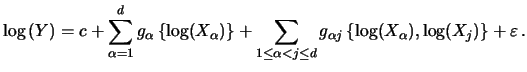
![\includegraphics[width=1.45\defpicwidth]{SPMinter11.ps}](spmhtmlimg2403.gif)
![\includegraphics[width=1.45\defpicwidth]{SPMinter12.ps}](spmhtmlimg2404.gif)