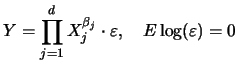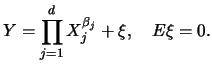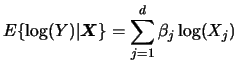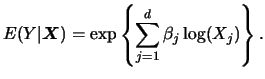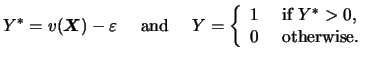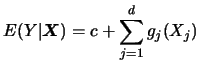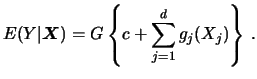Researchers have looked for possible remedies, and a lot of effort has been allocated to developing methods which reduce the complexity of high dimensional regression problems. This refers to the reduction of dimensionality as well as allowance for partly parametric modeling. Not surprisingly, one follows the other. The resulting models can be grouped together as so-called semiparametric models.
All models that we will study in the following chapters can be motivated as generalizations of well-known parametric models, mainly of the linear model
Let us take a closer look at model (5.1). This model is known as the generalized linear model. Its use and estimation are extensively treated in McCullagh & Nelder (1989). Here we give only some selected motivating examples.
What is the reason for introducing this functional ![]() , called the
link?
(Note that other authors call its inverse
, called the
link?
(Note that other authors call its inverse ![]() the link.)
Clearly, if
the link.)
Clearly, if ![]() is the identity we are back in the classical linear
model. As a first alternative let us consider a quite common approach for
investigating growth models. Here,
the model is often assumed to be multiplicative
instead of additive, i.e.
is the identity we are back in the classical linear
model. As a first alternative let us consider a quite common approach for
investigating growth models. Here,
the model is often assumed to be multiplicative
instead of additive, i.e.
The most common cases in which link functions are used are
binary responses (
![]() )
or multicategorical (
)
or multicategorical (
![]() ) responses and count data (
) responses and count data (![]() Poisson).
For the binary case, let us introduce an example that we will study
in more detail in Chapters 7 and 9.
Poisson).
For the binary case, let us introduce an example that we will study
in more detail in Chapters 7 and 9.
| Yes | No | (in %) | |||
| MIGRATION INTENTION | 38.5 | 61.5 | |||
| FAMILY/FRIENDS IN WEST | 85.6 | 11.2 | |||
| UNEMPLOYED/JOB LOSS CERTAIN | 19.7 | 78.9 | |||
| CITY SIZE 10,000-100,000 | 29.3 | 64.2 | |||
| FEMALE | 51.1 | 49.8 | |||
| Min | Max | Mean | S.D. | ||
| AGE (in years) | 18 | 65 | 39.84 | 12.61 | |
| HOUSEHOLD INCOME (in DM) | 200 | 4000 | 2194.30 | 752.45 |
In Example 5.1,
we hope that the vector of regressors
![]() captures the variables that systematically affect each person's
utility whereas unobserved or random influences
are absorbed by the term
captures the variables that systematically affect each person's
utility whereas unobserved or random influences
are absorbed by the term
![]() .
Suppose further, that the components of
.
Suppose further, that the components of
![]() influence net-utility
through a multivariate function
influence net-utility
through a multivariate function
![]() and that the error
term is additive. Then the latent-variable model is given by
and that the error
term is additive. Then the latent-variable model is given by
Recall that standard parametric models assume that
![]() is independently distributed of
is independently distributed of
![]() with known distribution
function
with known distribution
function
![]() , and that the index
, and that the index
![]() has the following simple form:
has the following simple form:
The binary choice model can be easily extended to the multicategorical case, which is usually called discrete choice model. We will not discuss extensions for multicategorical responses here. Some references for these models are mentioned in the bibliographic notes.
Several approaches have been proposed to reduce dimensionality or to generalize parametric regression models in order to allow for nonparametric relationships. Here, we state three different approaches:
The intention of variable selection
is to choose an appropriate subset of variables,
![]() ,
from the set of all variables that could
potentially enter the regression. Of course, the selection of the
variables could be determined by the particular problem at hand,
i.e. we choose the variables according to insights provided by
some underlying economic theory. This approach, however, does not
really solve the statistical side of our modeling process. The
curse of dimensionality could lead us to keep the number of
variables as low as possible. On the other hand, fewer variables
could in turn reduce the explanatory power of the model.
Thus, after having chosen a set of variables on theoretical
grounds in a first step, we still do not know how many and, more
importantly, which of these variables will lead to optimal
regression results. Therefore, a variable selection method is
needed that uses a statistical selection criterion.
,
from the set of all variables that could
potentially enter the regression. Of course, the selection of the
variables could be determined by the particular problem at hand,
i.e. we choose the variables according to insights provided by
some underlying economic theory. This approach, however, does not
really solve the statistical side of our modeling process. The
curse of dimensionality could lead us to keep the number of
variables as low as possible. On the other hand, fewer variables
could in turn reduce the explanatory power of the model.
Thus, after having chosen a set of variables on theoretical
grounds in a first step, we still do not know how many and, more
importantly, which of these variables will lead to optimal
regression results. Therefore, a variable selection method is
needed that uses a statistical selection criterion.
Vieu (1994) has proposed to use the integrated square
error ![]() to measure the quality of a given subset of variables. In
theory, a subset of variables is defined to be an optimal subset
if it minimizes the integrated squared error:
to measure the quality of a given subset of variables. In
theory, a subset of variables is defined to be an optimal subset
if it minimizes the integrated squared error:
Index models play an important role in econometrics. An
index is a summary of different variables into one number,
e.g. the price index, the growth index, or the cost-of-living index.
It is clear
that by summarizing all the information contained in the variables
![]() into one ``single index'' term we will greatly
reduce the dimensionality of a problem. Models based on such an
index are known as
single index models (SIM). In particular we will
discuss single index models of the following form:
into one ``single index'' term we will greatly
reduce the dimensionality of a problem. Models based on such an
index are known as
single index models (SIM). In particular we will
discuss single index models of the following form:
Obviously, (5.9) generalizes (5.7) in that
we do not assume the link function ![]() to be known. For that
purpose we replaced
to be known. For that
purpose we replaced ![]() by
by ![]() to emphasize that
the link function needs to be estimated.
Notice, that often the general index
function
to emphasize that
the link function needs to be estimated.
Notice, that often the general index
function
![]() is replaced by the linear
index
is replaced by the linear
index
![]() .
Equations (5.5) and (5.6) together with (5.8)
give examples for such linear index functions.
.
Equations (5.5) and (5.6) together with (5.8)
give examples for such linear index functions.
In many applications a canonical partitioning of the explanatory variables exists. In particular, if there are categorical or discrete explanatory variables we may want to keep them separate from the other design variables. Note that only the continuous variables in the nonparametric part of the model cause the curse of dimensionality (Delgado & Mora, 1995). In the following chapters we will study the following models:
For the sake of clarity, let us now
separate the ![]() -dimensional vector of explanatory variables
into
-dimensional vector of explanatory variables
into
![]() and
and
![]() . The
regression of
. The
regression of ![]() on
on
![]() is assumed to have the form:
is assumed to have the form:
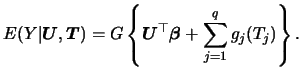
More discussion and motivation is given in the following chapters where the different models are discussed in detail and the specific estimation procedures are presented. Before proceeding with this task, however, we will first introduce some facts about the parametric generalized linear model (GLM). The following section is intended to give more insight into this model since its concept and the technical details of its estimation will be necessary for its semiparametric modification in Chapters 6 to 9.