Asymptotic statistical properties are only one part of the story. For the applied researcher knowledge of the finite sample behavior of a method and its robustness are essential. This section is reserved for this topic.
We present and examine now results on the finite sample performance of the competing backfitting and integration approaches. To keep things simple we only use local constant and local linear estimates here. For a more detailed discussion see Sperlich et al. (1999) and Nielsen & Linton (1998). Let us point out again, that
The following two subsections refer to results for the specific models
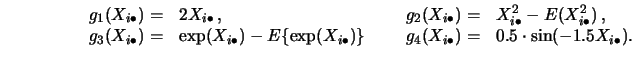
Note that all estimators presented in this section (two-dimensional
backfitting and marginal integration estimators)
are linear in
![]() , i.e. of the form
, i.e. of the form
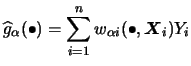
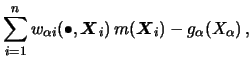 |
|||
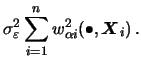 |
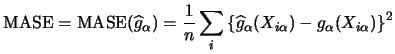
As we have already discussed in the first part of this book, the
choice of the smoothing parameter is crucial in
practice. The integration estimator requires to choose two
bandwidths, ![]() for the direction of interest and
for the direction of interest and
![]() for
the nuisance direction. Possible practical approaches are the rule of thumb of
Linton & Nielsen (1995) and the plug-in method suggested in
Severance-Lossin & Sperlich (1999). Both methods use the MASE-minimizing
bandwidth, the former approximating it by means of parametric
pre-estimators, the latter one by using nonparametric
pre-estimators.
for
the nuisance direction. Possible practical approaches are the rule of thumb of
Linton & Nielsen (1995) and the plug-in method suggested in
Severance-Lossin & Sperlich (1999). Both methods use the MASE-minimizing
bandwidth, the former approximating it by means of parametric
pre-estimators, the latter one by using nonparametric
pre-estimators.
For example, the formula for the MASE-minimizing (and thus asymptotically optimal) bandwidth in the local linear case is given by
In case of backfitting the procedure becomes possible due to the fact that we only consider one-dimensional smoothers. Here, the MASE-minimizing bandwidth is commonly approximated by the MASE-minimizing bandwidth for the corresponding one-dimensional kernel regression case.
![\includegraphics[width=0.9\defpicwidth]{SPMmse-hr33.ps}](spmhtmlimg2436.gif)
![\includegraphics[width=0.9\defpicwidth]{SPMmse-hn03.ps}](spmhtmlimg2437.gif)
|
![\includegraphics[width=0.9\defpicwidth]{SPMmse-hr34.ps}](spmhtmlimg2438.gif)
![\includegraphics[width=0.9\defpicwidth]{SPMmse-hn04.ps}](spmhtmlimg2439.gif)
|
Obviously, the backfitting estimator is rather sensitive to the
choice of bandwidth. To get small MASE values it is important for the
backfitting method to choose the smoothing parameter
appropriately.
For the integration estimator the results differ depending on the
model. This method is nowhere near as sensitive to the choice of
bandwidth as the backfitting. Focusing on the ![]() we have
similar results as for the MASE but weakened concerning the
sensitivity. Here the results differ more depending on the data
generating model.
we have
similar results as for the MASE but weakened concerning the
sensitivity. Here the results differ more depending on the data
generating model.
Table 8.1 presents the MASE when using
local linear smoothers and the asymptotically optimal bandwidths.
To exclude boundary effects each entry of the table consists
of two rows: evaluation on the complete data set in the upper row, and
evaluation on trimmed data in the lower row. The trimming was implemented
by cutting off ![]() of the data on each side of the support.
of the data on each side of the support.
| covariance |
|
|
|
|
|
|
|
|
|
|
|
|
|
| model |
|
|
|
|
|||||||||
| back | 0.047 | 0.041 | 0.020 | 0.046 | 0.028 | 0.053 | 0.124 | 0.135 | 0.128 | 0.068 | 0.081 | 0.111 | |
| 0.038 | 0.031 | 0.014 | 0.037 | 0.018 | 0.033 | 0.107 | 0.116 | 0.099 | 0.046 | 0.055 | 0.081 | ||
|
|
int | 0.019 | 0.030 | 0.057 | 0.031 | 0.075 | 0.081 | 0.047 | 0.048 | 0.089 | 0.053 | 0.049 | 0.056 |
| 0.013 | 0.017 | 0.047 | 0.024 | 0.059 | 0.071 | 0.022 | 0.026 | 0.078 | 0.026 | 0.022 | 0.041 | ||
| back | 0.083 | 0.079 | 0.047 | 0.073 | 0.053 | 0.058 | 0.112 | 0.121 | 0.110 | 0.051 | 0.062 | 0.096 | |
| 0.071 | 0.060 | 0.024 | 0.058 | 0.032 | 0.028 | 0.101 | 0.110 | 0.091 | 0.039 | 0.048 | 0.075 | ||
|
|
int | 0.090 | 0.116 | 0.530 | 0.137 | 0.234 | 0.528 | 0.048 | 0.480 | 1.32 | 0.057 | 0.603 | 2.41 |
| 0.028 | 0.029 | 0.205 | 0.027 | 0.031 | 0.149 | 0.032 | 0.061 | 0.151 | 0.040 | 0.265 | 1.02 | ||
| back | 0.052 | 0.054 | 0.049 | 0.051 | 0.054 | 0.057 | 0.061 | 0.063 | 0.068 | 0.065 | 0.066 | 0.064 | |
| 0.032 | 0.031 | 0.028 | 0.030 | 0.029 | 0.035 | 0.035 | 0.035 | 0.037 | 0.038 | 0.037 | 0.038 | ||
|
|
int | 0.115 | 0.145 | 0.619 | 0.175 | 0.285 | 0.608 | 0.118 | 0.561 | 1.37 | 0.085 | 0.670 | 2.24 |
| 0.041 | 0.041 | 0.252 | 0.043 | 0.053 | 0.194 | 0.076 | 0.083 | 0.189 | 0.044 | 0.257 | 0.681 | ||
We see that no estimator is uniformly superior to the others. All results depend more significantly on the design distribution and the underlying model than on the particular estimation procedure. The main conclusion is that backfitting almost always fits the overall regression better whereas the marginal integration often does better for the additive components. Recalling the construction of the procedures this is not surprising, but exactly what one should have expected.
Also not surprisingly, the integration estimator suffers more heavily from boundary effects. For increasing correlation both estimators perform worse, but this effect is especially present for the integration estimator. This is in line with the theory saying that the integration estimator is inefficient for correlated designs, see Linton (1997). Here a bandwidth matrix with appropriate non-zero arguments in the off diagonals can help in case of high correlated regressors, see a corresponding study in Sperlich et al. (1999). They point out that the fit can be improved significantly by using well defined off-diagonal elements in the bandwidth matrices. A similar analysis would be harder to do for the backfitting method as it depends only on one-dimensional smoothers. We remark that internalized marginal integration estimators (Dette et al., 2004) and smoothed backfitting estimators (Mammen et al., 1999; Nielsen & Sperlich, 2002) are much better suited to deal with correlated regressors.
How do the additive approaches overcome the
curse of dimensionality?
We compare now the additive estimation method with the
bivariate Nadaraya-Watson kernel smoother. We define equivalent
kernels as the linear weights ![]() used in the estimates for fitting the
regression function at a particular point. In the following we take the
center point
used in the estimates for fitting the
regression function at a particular point. In the following we take the
center point ![]() , which is used in Figures 8.11
to 8.13. All estimators are based on
univariate or bivariate Nadaraya-Watson smoothers (in the latter
case using a diagonal bandwidth matrix).
, which is used in Figures 8.11
to 8.13. All estimators are based on
univariate or bivariate Nadaraya-Watson smoothers (in the latter
case using a diagonal bandwidth matrix).
![\includegraphics[width=1.4\defpicwidth]{SPMam-nw.ps}](spmhtmlimg2451.gif)
|
![\includegraphics[width=1.4\defpicwidth]{SPMam-b.ps}](spmhtmlimg2452.gif)
|
![\includegraphics[width=1.4\defpicwidth]{SPMam-int.ps}](spmhtmlimg2453.gif)
|
Obviously, additive methods (Figures 8.12, 8.13) are characterized by their local panels along the axes instead of being uniformly equal in all directions like the bivariate Nadaraya-Watson (Figure 8.11). Since additive estimators are made up of components that behave like univariate smoothers, they can overcome the curse of dimensionality. The pictures for the additive smoothers look very similar (apart from some negative weights for the backfitting).
Finally, we see clearly how both additive methods run
into problems when the correlation between the regressors is
increasing. In particular for the marginal integration estimator
recall that before we apply the
integration over the nuisance directions, we pre-estimate
![]() on all combinations of realizations of
on all combinations of realizations of ![]() and
and ![]() .
For example, since
.
For example, since ![]() are both uniform on
are both uniform on ![]() it
may happen that we have to pre-estimate the regression function
at the point
it
may happen that we have to pre-estimate the regression function
at the point
![]() . Now imagine that
. Now imagine that
![]() and
and ![]() are positively correlated. In small samples, the
pre-estimate for
are positively correlated. In small samples, the
pre-estimate for
![]() is then usually obtained by
extrapolation. The insufficient quality of the pre-estimate
does then transfer to the final estimate.
is then usually obtained by
extrapolation. The insufficient quality of the pre-estimate
does then transfer to the final estimate.
Consider the empirical model
The data base for this analysis is drawn from the Kienbaum Vergütungsstudie, containing data about top management compensation of German AGs and the compensation of managing directors (Geschäftsführer) of incorporateds (GmbHs). To measure compensation we use managerial compensation per capita due to the lack of more detailed information. The analysis is based on the following four industry groups.
| Group | 1 | 2 | 3 | 4 |
| # observations | 131 | 148 | 41 | 38 |
| constant | 4.128 |
4.547 |
3.776 |
4.120 |
| ROS | 1.641 | 0.959 | 15.01 |
8.377 |
| log(SIZE) | 0.258 |
0.201 |
0.283 |
0.249 |
We first present the results of the parametric analysis for each group, see Table 8.2. The sensitivity parameter for the size variable can be directly interpreted as the size elasticity in each case.
![\includegraphics[width=1.4\defpicwidth]{SPMmanag4.ps}](spmhtmlimg2465.gif)
|
We now check for a possible heterogeneous behavior over the groups. A two-dimensional Nadaraya-Watson estimate is shown in Figure 8.14. Considering the plots we realize that the estimated surfaces are similar for the industry groups 1 and 2 (upper row) while the surfaces for the two other groups clearly differ. Further, we see a strong positive relation for compensation to firm size at least in groups 1 and 2, and a weaker one to the performance measure varying over years and groups. Finally, interaction of the regressors -- especially in groups 3 and 4 -- can be recognized.
The backfitting procedure projects the data into the space of additive models. We used for the backfitting estimators univariate local linear kernel smoother with Quartic kernel and bandwidth inflation factors 0.75, 0.5 for group 1 and 2 and 1.25, 1.0 for groups 3 and 4. In the Figure 8.15 we compare the nonparametric (additive) components with the parametric (linear) functions. Over all groups we observe a clear nonlinear impact of ROS. Note, that the low values for significance in the parametric model describe only the linear impact, which here seem to be caused by functional misspecification (or interactions).
Finally, in Figure 8.16 we estimate the marginal
effects of the regressors using
local linear smoothers.
The estimated marginal effects are presented together with
![]() -bands, where we use for
-bands, where we use for ![]() the variance
functions of the estimates. Note that for ROS in group 1 the ranges
are slightly different as in Figure 8.15.
the variance
functions of the estimates. Note that for ROS in group 1 the ranges
are slightly different as in Figure 8.15.
Generally, the results are consistent with the findings above. The nonlinear effects in the impact of ROS are stronger, especially in groups 1 and 2. Since the abovementioned bumps in the firm size do not exist here, we can conclude that indeed interaction effects are responsible for this. The backfitting results differ substantially from the estimated marginal effects in group 3 and 4 what again underlines the presence of interaction effects.
To summarize, we conclude that the separation into groups is
useful, but groups 1 and 2 respectively 3 and 4 seem to behave similarly. The
assumption of additivity seems to be violated for groups 3 and 4.
Furthermore, the nonparametric estimates yield different results due
to nonlinear effects and interaction, so that parametric
elasticities underestimate the true elasticity in our example. ![]()
Additive models were first considered for economics and econometrics by Leontief (1947a,b). Intensive discussion of their application to economics can be found in Deaton & Muellbauer (1980) and Fuss et al. (1978). Wecker & Ansley (1983) introduced especially the backfitting method in economics.
The development of the backfitting procedure has a long history. The procedure goes back to algorithms of Friedman & Stuetzle (1982) and Breiman & Friedman (1985). We also refer to Buja et al. (1989) and the references therein. Asymptotic theory for backfitting has been studied first by Opsomer & Ruppert (1997), and later on (under more general conditions) in the above mentioned paper of Mammen et al. (1999).
The marginal integration estimator was first presented by Tjøstheim & Auestad (1994a) and Linton & Nielsen (1995), the idea can also be found in Newey (1994) or Boularan et al. (1994) for estimating growth curves. Hengartner et al. (1999) introduce modifications leading to computational efficiency. Masry & Tjøstheim (1997); Masry & Tjøstheim (1995) use marginal integration and prove its consistency in the context of time series analysis. Dalelane (1999) and Achmus (2000) prove consistency of bootstrap methods for marginal integration. Linton (1997) combines marginal integration and a one step backfitting iteration to obtain an estimator that is both efficient and easy to analyze.
Interaction models have been considered in different papers. Stone et al. (1997) and Andrews & Whang (1990) developed estimators for interaction terms of any order by polynomial splines. Spline estimators have also been used by Wahba (1990). For series estimation we refer in particular to Newey (1995) and the references therein. Härdle et al. (2001) use wavelets to test for additive models. Testing additivity is a field with a growing amount of literature, such as Chen et al. (1995), Eubank et al. (1995) and Gozalo & Linton (2001).
A comprehensive resource for additive modeling is is the textbook by Hastie & Tibshirani (1990) who focus on the backfitting approach. Further references are Sperlich (1998) and Ruppert et al. (1990).
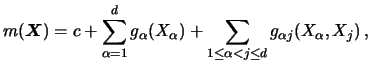
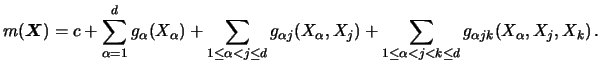
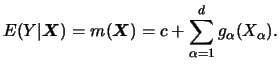
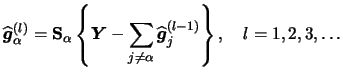
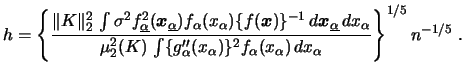
![\includegraphics[width=1.4\defpicwidth]{SPMmanag2.ps}](spmhtmlimg2464.gif)
![\includegraphics[width=1.4\defpicwidth]{SPMmanag5.ps}](spmhtmlimg2466.gif)