EXERCISE 10.1
In Example
10.4 we have computed
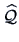
and
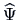
using the method of principal factors. We used a two-step
iteration for
. Perform the third iteration step and
compare the results (i.e., use the given
as
a pre-estimate to find the final
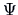
).
EXERCISE 10.2
Using the bank data set, how many factors can you find with the
Method of Principal Factors?
EXERCISE 10.3
Repeat Exercise
10.2 with the U.S. company data set!
EXERCISE 10.4
Generalize the two-dimensional rotation matrix in Section
10.2 to
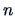
-dimensional space.
EXERCISE 10.5
Compute the orthogonal factor model for
[Solution:
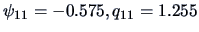
]
EXERCISE 10.6
Perform a factor analysis on the type of families in the
French food data set. Rotate the resulting factors in a way which provides
the most reasonable interpretation. Compare your result with the varimax
method.
EXERCISE 10.7
Perform a factor analysis on the variables
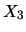
to
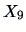
in
the U.S. crime data set (Table
B.10).
Would it make sense to use all of the variables for the analysis?
EXERCISE 10.8
Analyze the athletic records data set (Table
B.18).
Can you recognize any patterns if you sort the countries according
to the estimates of the factor scores?
EXERCISE 10.9
Perform a factor analysis on the U.S. health data set
(Table
B.16) and estimate the factor scores.
EXERCISE 10.10
Redo Exercise
10.9 using the U.S. crime data in
Table
B.10. Compare the estimated factor scores
of the two data sets.
EXERCISE 10.11
Analyze the vocabulary data given in Table
B.17.
