12. Discriminant Analysis
Discriminant analysis is used in situations where the
clusters are known a priori. The aim of discriminant
analysis is to classify an observation, or several observations, into
these known groups.
For instance, in credit scoring, a bank knows from past experience that
there are good customers (who repay their loan without any problems) and
bad customers (who showed difficulties in repaying their loan). When a new
customer asks for a loan, the bank has to decide whether
or not to give the loan.
The past records of the bank provides two data sets: multivariate
observations 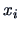 on the two categories of customers (including for example
age, salary, marital status, the amount of the loan, etc.).
The new
customer is a new observation
on the two categories of customers (including for example
age, salary, marital status, the amount of the loan, etc.).
The new
customer is a new observation 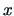 with the same variables. The
discrimination rule has to classify the customer into one of the two existing
groups and the discriminant analysis should evaluate the risk of a
possible ``bad decision''.
with the same variables. The
discrimination rule has to classify the customer into one of the two existing
groups and the discriminant analysis should evaluate the risk of a
possible ``bad decision''.
Many other examples are described below, and in most applications, the
groups correspond to natural classifications or to groups known from
history (like in the credit scoring example). These
groups could have been formed by a cluster analysis performed on past data.
Section 12.1 presents the allocation rules when the populations
are known, i.e., when we know the distribution of each population.
As described in Section 12.2 in practice
the population characteristics have to be estimated from history.
The methods are illustrated in several examples.