In Econometrics the relationships between economic variables proposed by the Economic Theory are usually studied within the framework of linear regression models (see chapters 1 and 2). The data of many economic and business variables are collected in the form of time series. In this section we deal with the problems that may appear when estimating regression models with time series data.
It can be proved that many of the results on the properties of LS estimators
and inference rely on
the assumption of stationarity of the explanatory variables. Thus, the
standard proof of consistency of the LS estimator depends on the
assumption plim
![]() , where
, where ![]() is the data matrix and
is the data matrix and ![]() is a
fixed matrix. This assumption implies that the sample moments converge to
the population values as the sample size
is a
fixed matrix. This assumption implies that the sample moments converge to
the population values as the sample size ![]() increases. But the
explanatory variables must be stationary in order to have fixed
values in the matrix
increases. But the
explanatory variables must be stationary in order to have fixed
values in the matrix ![]() .
.
As it has been discussed in section 4.3.2, many of the
macroeconomic, finance, monetary variables are nonstationary presenting
trending behaviour in most cases. From an econometric point view, the
presence of a deterministic trend (linear or not) in the explanatory
variables does not raise any problem. But many economic and business time
series are nonstationary even after eliminating deterministic trends due to
the presence of unit roots, that is, they are generated by integrated
processes. When nonstationary time series are used in a regression
model one may obtain apparently significant relationships from unrelated
variables. This phenomenom is called spurious regression.
Granger and Newbold (1974) estimated regression models of the type:
These results found by Granger and Newbold (1974) were analytically explained
by Phillips (1986). He shows that the t-ratios in model (4.54)
do not follow a t-Student distribution and they go to infinity as ![]() increases. This implies that for any critical value the ratios of rejection
of the null hypothesis
increases. This implies that for any critical value the ratios of rejection
of the null hypothesis ![]() increase with
increase with ![]() . Phillips (1986)
showed as well that the D-W statistic converges to zero as
. Phillips (1986)
showed as well that the D-W statistic converges to zero as ![]() goes to
infinity, while it converges to a value different
from zero when the variables are related. Then, the value of the D-W
statistic may help us to distinguish between genuine and spurious
regressions. Summarizing, the spurious regression results are due to the
nonstationarity of the variables and the problem is not solved by
increasing the sample size
goes to
infinity, while it converges to a value different
from zero when the variables are related. Then, the value of the D-W
statistic may help us to distinguish between genuine and spurious
regressions. Summarizing, the spurious regression results are due to the
nonstationarity of the variables and the problem is not solved by
increasing the sample size ![]() , it even gets worse.
, it even gets worse.
Due to the problems raised by regressing nonstationary variables, econometricians have looked for solutions. One classical approach has been to detrend the series adjusting a determinist trend or including directly a deterministic function of time in the regression model (4.54) to take into account the nonstationary behaviour of the series. However, Phillips (1986) shows that this does not solve the problem if the series are integrated. The t-ratios in the regression model with a deterministic trend do not follow a t-Student distribution and therefore standard inference results could be misleading. Furthermore, it still appears spurious correlation between detrended random walks, that is, spurious regression. A second approach to work with nonstationary series is to look for relationships between stationary differenced series. However, it has to be taken into account that the information about the long-run relationship is lost, and the economic relationship may be different between levels and between increments.
When estimating regression models using time series data it is necessary to know whether the variables are stationary or not (either around a level or a deterministic linear trend) in order to avoid spurious regression problems. This analysis can be perform by using the unit root and stationarity tests presented in section 4.3.3.
It is well known that if two series are integrated to different orders,
linear combinations of them will be integrated to the higher of the two
orders. Thus, for instance, if two economic variables
![]() are
are
![]() , the linear combination of them,
, the linear combination of them, ![]() , will be
generally
, will be
generally ![]() . But it is possible that certain combinations of those
nonstationary series are stationary. Then it is said that the pair
. But it is possible that certain combinations of those
nonstationary series are stationary. Then it is said that the pair
![]() is cointegrated.
The notion of cointegration is important to the analysis of long-run
relationships between economic time series. Some examples are disposable
income and consumption, goverment spending and tax revenues or interest
rates on assets of differents maturities. Economic theory suggests that
economic time series vectors should move jointly, that is, economic
time series should be characterized by means of a long-run equilibrium
relationship. Cointegration implies that these pairs of variables have
similar stochastic trends. Besides, the dynamics of the economic variables
suggests that they may deviate from this equilibrium in the short term, and
when the variables are cointegrated the term
is cointegrated.
The notion of cointegration is important to the analysis of long-run
relationships between economic time series. Some examples are disposable
income and consumption, goverment spending and tax revenues or interest
rates on assets of differents maturities. Economic theory suggests that
economic time series vectors should move jointly, that is, economic
time series should be characterized by means of a long-run equilibrium
relationship. Cointegration implies that these pairs of variables have
similar stochastic trends. Besides, the dynamics of the economic variables
suggests that they may deviate from this equilibrium in the short term, and
when the variables are cointegrated the term ![]() is stationary.
is stationary.
The definition of cointegration can be generalized to a set of ![]() variables (Engle and Granger; 1987): The components of the vector
variables (Engle and Granger; 1987): The components of the vector ![]() are said to
be co-integrated of order d,b denoted
are said to
be co-integrated of order d,b denoted
![]() , if (i) all
components of
, if (i) all
components of ![]() are
are ![]() ; (ii) there exists a vector
; (ii) there exists a vector
![]() so that
so that
![]() . The vector
. The vector ![]() is
called the co-integrating vector.
is
called the co-integrating vector.
The relationship
![]() captures the long-run equilibrium. The
term
captures the long-run equilibrium. The
term
![]() represents the deviation from the long-run
equilibrium so it is called the equilibrium error. In general, more than
one cointegrating relationship may exist between
represents the deviation from the long-run
equilibrium so it is called the equilibrium error. In general, more than
one cointegrating relationship may exist between ![]() variables, with a
maximum of
variables, with a
maximum of ![]() . For the case of two
. For the case of two ![]() variables, the long-run
equilibrium can be written as
variables, the long-run
equilibrium can be written as
![]() and the
cointegrating vector is
and the
cointegrating vector is
![]() ).
Clearly the cointegrating vector is not unique, since by multiplying both
sides of
).
Clearly the cointegrating vector is not unique, since by multiplying both
sides of
![]() by a nonzero scalar the equality remains valid.
by a nonzero scalar the equality remains valid.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
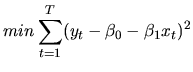
At is has been mentioned above, a classical approach to build regression
models for nonstationary variables is to difference the series in order to
achieve stationarity and analyze the relationship between stationary
variables. Then, the information about the long-run relationship is lost.
But the presence of cointegration between regressors and dependent variable
implies that the level of these variables are related in the log-run. So,
although the variables are nonstationary, it seems more appropriate in this
case to estimate the relationship between levels, without differencing the
data, that is, to estimate the cointegrating relationship. On the other
hand, it could be interesting as well to formulate a model that combines
both long-run and short-run behaviour of the variables. This approach is
based on the estimation of error correction models (![]() ) that relate the
change in one variable to the deviations from the long-run equilibrium in
the previous period. For example, an
) that relate the
change in one variable to the deviations from the long-run equilibrium in
the previous period. For example, an ![]() for two
for two ![]() variables can be
written as:
variables can be
written as:
This model can be generalized as follows (Engle and Granger; 1987):
a vector of time series ![]() has an error correction representation if it
can be expressed as:
has an error correction representation if it
can be expressed as:
In the previous example it means that the following equation is estimated
by least squares:
![\includegraphics[width=0.8\defpicwidth]{eucoi.ps}](xegbohtmlimg2160.gif)