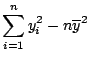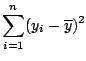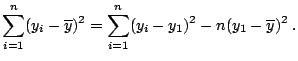Numbers are the lifeblood of statistics, and computational statistics relies heavily on how numbers are represented and manipulated on a computer. Computer hardware and statistical software handle numbers well, and the methodology of computer arithmetic is rarely a concern. However, whenever we push hardware and software to their limits with difficult problems, we can see signs of the mechanics of floating point arithmetic around the frayed edges. To work on difficult problems with confidence and explore the frontiers of statistical methods and software, we need to have a sound understanding of the foundations of computer arithmetic. We need to know how arithmetic works and why things are designed the way they are.
As scientific computation began to rely heavily on computers, a monumental decision was made during the 1960's to change from base ten arithmetic to base two. Humans had been doing base ten arithmetic for only a few hundred years, during which time great advances were possible in science in a short period of time. Consequently, the resistance to this change was strong and understandable. The motivation behind the change to base two arithmetic is merely that it is so very easy to do addition (and subtraction) and multiplication in base two arithmetic. The steps are easy enough that a machine can be designed - wire a board of relays - or design a silicon chip - to do base two arithmetic. Base ten arithmetic is comparatively quite difficult, as its recent mathematical creation would suggest. However two big problems arise in changing from base ten to base two: (1) we need to constantly convert numbers written in base ten by humans to base two number system and then back again to base ten for humans to read the results, and (2) we need to understand the limits of arithmetic in a different number system.
Computers use two basic ways of writing numbers: fixed point (for
integers) and floating point (for real numbers). Numbers are written
on a computer following base two positional notation. The
positional number system is a convention for expressing
a number as a list of integers (digits), representing a number ![]() in
base
in
base ![]() by
a list of digits
by
a list of digits
![]() whose mathematical
meaning is
whose mathematical
meaning is
The system based on (1.1), known as fixed point
arithmetic, is useful for writing integers. The choice of ![]() dominates current computer hardware, although smaller (
dominates current computer hardware, although smaller (![]() ) choices
are available via software and larger (
) choices
are available via software and larger (![]() ) hardware had been
common in high performance computing. Recent advances in computer
architecture may soon lead to the standard changing to
) hardware had been
common in high performance computing. Recent advances in computer
architecture may soon lead to the standard changing to ![]() . While
the writing of a number in base two requires only the listing of its
binary digits, a convention is necessary for expression of negative
numbers. The survivor of many years of intellectual competition is
the two's complement convention. Here the first (leftmost)
bit is reserved for the sign, using the convention that 0 means
positive and 1 means negative. Negative numbers are written by
complementing each bit (replace 1 with 0, 0 with 1) and adding
one to the result. For
. While
the writing of a number in base two requires only the listing of its
binary digits, a convention is necessary for expression of negative
numbers. The survivor of many years of intellectual competition is
the two's complement convention. Here the first (leftmost)
bit is reserved for the sign, using the convention that 0 means
positive and 1 means negative. Negative numbers are written by
complementing each bit (replace 1 with 0, 0 with 1) and adding
one to the result. For ![]() (easier to display), this means that
(easier to display), this means that
![]() and its negative are written as
and its negative are written as
Following the two's complement convention with ![]() bits, the smallest
(negative) number that can be written is
bits, the smallest
(negative) number that can be written is ![]() and the largest
positive number is
and the largest
positive number is ![]() ; zero has a unique representation of
(
; zero has a unique representation of
(
![]() ). Basic arithmetic (addition and
multiplication) using two's complement is easy to code, essentially
taking the form of mod
). Basic arithmetic (addition and
multiplication) using two's complement is easy to code, essentially
taking the form of mod ![]() arithmetic, with special tools for
overflow and sign changes. See, for example, [8] for
history and details, as well as algorithms for base conversions.
arithmetic, with special tools for
overflow and sign changes. See, for example, [8] for
history and details, as well as algorithms for base conversions.
The great advantage of fixed point (integer) arithmetic is that it is so very fast. For many applications, integer arithmetic suffices, and most nonscientific computer software only uses fixed point arithmetic. Its second advantage is that it does not suffer from the rounding error inherent in its competitor, floating point arithmetic, whose discussion follows.
To handle a larger subset of the real numbers, the positional notation system includes an exponent to express the location of the radix point (generalization of the decimal point), so that the usual format is a triple (sign, exponent, fraction) to represent a number as
An important conceptual leap is the understanding that most numbers
are represented only approximately in floating point arithmetic. This
extends beyond the usual irrational numbers such as ![]() or
or ![]() that
cannot be represented with a finite number of digits. A novice user
may enter a familiar assignment such as
that
cannot be represented with a finite number of digits. A novice user
may enter a familiar assignment such as ![]() and, observing
that the computer prints out
and, observing
that the computer prints out ![]() , may consider this an
error. When the ''
, may consider this an
error. When the ''![]() '' was entered, the computer had to
first parse the text ''
'' was entered, the computer had to
first parse the text ''![]() '' and recognize the decimal point
and arabic numbers as a representation, for humans, of a real number
with the value
'' and recognize the decimal point
and arabic numbers as a representation, for humans, of a real number
with the value
![]() . The second step is to convert
this real number to a base two floating point number - approximating
this base ten number with the closest base two number - this is the
function
. The second step is to convert
this real number to a base two floating point number - approximating
this base ten number with the closest base two number - this is the
function ![]() . Just as
. Just as ![]() produces the repeating decimal
produces the repeating decimal
![]() in base
in base ![]() , the number
, the number ![]() produces
a repeating binary representation
produces
a repeating binary representation
![]() ,
and is chopped or rounded to the nearest floating point number
,
and is chopped or rounded to the nearest floating point number
![]() . Later, in printing this same number out, a second
conversion produces the closest base
. Later, in printing this same number out, a second
conversion produces the closest base ![]() number to
number to ![]() with few digits; in this case
with few digits; in this case ![]() , not an error at
all. Common practice is to employ numbers that are integers divided by
powers of two, since they are exactly represented. For example,
distributing
, not an error at
all. Common practice is to employ numbers that are integers divided by
powers of two, since they are exactly represented. For example,
distributing ![]() equally spaced points makes more sense than the
usual
equally spaced points makes more sense than the
usual ![]() , since
, since ![]() can be exactly represented for any
integer
can be exactly represented for any
integer ![]() .
.
A breakthrough in hardware for scientific computing came with the
adoption and implementation of the IEEE ![]() binary floating point
arithmetic standard, which has standards for two levels of precision,
single precision and double precision
([6]). The single precision standard uses
binary floating point
arithmetic standard, which has standards for two levels of precision,
single precision and double precision
([6]). The single precision standard uses ![]() bits to
represent a number: a single bit for the sign,
bits to
represent a number: a single bit for the sign, ![]() bits for the
exponent and
bits for the
exponent and ![]() bits for the fraction. The double precision
standard requires
bits for the fraction. The double precision
standard requires ![]() bits, using
bits, using ![]() more bits for the exponent and
adds
more bits for the exponent and
adds ![]() to the fraction for a total of
to the fraction for a total of ![]() . Since the leading
digit of a normalized number is nonzero, in base two the leading digit
must be one. As a result, the floating point form (1.2) above
takes a slightly modified form:
. Since the leading
digit of a normalized number is nonzero, in base two the leading digit
must be one. As a result, the floating point form (1.2) above
takes a slightly modified form:
The two extreme values of the exponent are employed for special
features. At the high end, the case exponent![]() signals two
infinities (
signals two
infinities (![]() ) with the largest possible fraction. These
values arise as the result of an overflow operation. The
most common causes are adding or multiplying two very large numbers,
or from a function call that produces a result that is larger than any
floating point number. For example, the value of
) with the largest possible fraction. These
values arise as the result of an overflow operation. The
most common causes are adding or multiplying two very large numbers,
or from a function call that produces a result that is larger than any
floating point number. For example, the value of ![]() is larger
than any finite number in
is larger
than any finite number in
![]() for
for ![]() in single
precision. Before adoption of the standard,
in single
precision. Before adoption of the standard,
![]() would
cause the program to cease operation due to this ''exception''.
Including
would
cause the program to cease operation due to this ''exception''.
Including ![]() as members of
as members of
![]() permits the
computations to continue, since a sensible result is now available.
As a result, further computations involving the value
permits the
computations to continue, since a sensible result is now available.
As a result, further computations involving the value ![]() can
proceed naturally, such as
can
proceed naturally, such as
![]() . Again using the
. Again using the
![]() , but with any other fraction represents
not-a-number, usually written as ''NaN'', and used to
express the result of invalid operations, such as
, but with any other fraction represents
not-a-number, usually written as ''NaN'', and used to
express the result of invalid operations, such as ![]() ,
,
![]() ,
,
![]() , and square roots of negative
numbers. For statistical purposes, another important use of NaN is to
designate missing values in data. The use of infinities and NaN permit
continued execution in the case of anomalous arithmetic operations,
instead of causing computation to cease when such anomalies occur.
The other extreme
, and square roots of negative
numbers. For statistical purposes, another important use of NaN is to
designate missing values in data. The use of infinities and NaN permit
continued execution in the case of anomalous arithmetic operations,
instead of causing computation to cease when such anomalies occur.
The other extreme
![]() signals a denormalized number
with the net exponent of
signals a denormalized number
with the net exponent of ![]() and an unnormalized fraction, with the
representation following (1.2), rather than the
usual (1.4) with the unstated and unstored 1. The
denormalized numbers further expand the available numbers in
and an unnormalized fraction, with the
representation following (1.2), rather than the
usual (1.4) with the unstated and unstored 1. The
denormalized numbers further expand the available numbers in
![]() , and permit a soft underflow. Underflow, in
contrast to overflow, arises when the result of an arithmetic
operation is smaller in magnitude than the smallest representable
positive number, usually caused by multiplying two small numbers
together. These denormalized numbers begin approximately
, and permit a soft underflow. Underflow, in
contrast to overflow, arises when the result of an arithmetic
operation is smaller in magnitude than the smallest representable
positive number, usually caused by multiplying two small numbers
together. These denormalized numbers begin approximately ![]() near the reciprocal of the largest positive number. The denormalized
numbers provide even smaller numbers, down to
near the reciprocal of the largest positive number. The denormalized
numbers provide even smaller numbers, down to ![]() . Below that,
the next number in
. Below that,
the next number in
![]() is the floating point zero: the
smallest exponent and zero fraction - all bits zero.
is the floating point zero: the
smallest exponent and zero fraction - all bits zero.
Most statistical software employs only double precision arithmetic,
and some users become familiar with apparent aberrant behavior such as
a sum of residuals of ![]() instead of zero. While many areas of
science function quite well using single precision, some problems,
especially nonlinear optimization, nevertheless require double
precision. The use of single precision requires a sound understand of
rounding error. However, the same rounding effects remain in double
precision, but because their effects are so often obscured from view,
double precision may promote a naive view that computers are perfectly
accurate.
instead of zero. While many areas of
science function quite well using single precision, some problems,
especially nonlinear optimization, nevertheless require double
precision. The use of single precision requires a sound understand of
rounding error. However, the same rounding effects remain in double
precision, but because their effects are so often obscured from view,
double precision may promote a naive view that computers are perfectly
accurate.
The machine unit expresses a relative accuracy in storing a real
number as a floating point number. Another similar quantity, the
machine epsilon, denoted by
![]() , is defined as the smallest
positive number than, when added to one, gives a result that is
different from one. Mathematically, this can be written as
, is defined as the smallest
positive number than, when added to one, gives a result that is
different from one. Mathematically, this can be written as
Often one of the more surprising aspects of floating point arithmetic
is that some of the more familiar laws of algebra are occasionally
violated: in particular, the associative and distributive laws. While
most occurrences are just disconcerting to those unfamiliar to
computer arithmetic, one serious concern is cancellation. For
a simple example, consider the case of base ten arithmetic with ![]() digits, and take
digits, and take ![]() and
and ![]() , and note
that both
, and note
that both ![]() and
and ![]() may have been rounded, perhaps
may have been rounded, perhaps ![]() was
was
![]() or
or
![]() or
or
![]() . Now
. Now
![]() would be stored as
would be stored as
![]() and
and ![]() would be written
as
would be written
as
![]() , and when these two numbers are subtracted,
we have the unnormalized difference
, and when these two numbers are subtracted,
we have the unnormalized difference
![]() .
Normalization would lead to
.
Normalization would lead to
![]() where merely
''?'' represents that some digits need to take their place. The
simplistic option is to put zeros, but
where merely
''?'' represents that some digits need to take their place. The
simplistic option is to put zeros, but ![]() is just as
good an estimate of the true difference between
is just as
good an estimate of the true difference between ![]() and
and ![]() as
as
![]() , or
, or ![]() , for that matter. The problem
with cancellation is that the relative accuracy that floating point
arithmetic aims to protect has been corrupted by the loss of the
leading significant digits. Instead of a small error in the sixth
digit, we now have that error in the third digit; the relative error
has effectively been magnified by a factor of
, for that matter. The problem
with cancellation is that the relative accuracy that floating point
arithmetic aims to protect has been corrupted by the loss of the
leading significant digits. Instead of a small error in the sixth
digit, we now have that error in the third digit; the relative error
has effectively been magnified by a factor of ![]() due to the
cancellation of the first
due to the
cancellation of the first ![]() digits.
digits.
The best way to deal with the potential problem caused by catastrophic cancellation is to avoid them. In many cases, the cancellation may be avoided by reworking the computations analytically to handle the cancellation:
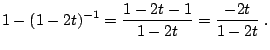 |
One application where rounding error must be understood and cancellation cannot be avoided is numerical differentiation, where calls to a function are used to approximate a derivative from a first difference:
![$\displaystyle \left[\,f(x+h)-f(x)\right]/h\approx f'(x)+\frac{1}{2}hf''(x)\;.$](img385.gif) |
The second approach for avoiding the effects of cancellation is to develop different methods. A common cancellation problem in statistics arises from using the formula
To illustrate the effect of cancellation, take the simple problem of
![]() observations,
observations,
![]() so that
so that
![]() through
through
![]() . Again using six decimal digits, the
computations of the sum and mean encounter no problems, and we easily
get
. Again using six decimal digits, the
computations of the sum and mean encounter no problems, and we easily
get
![]() or
or
![]() , and
, and
![]() or
or
![]() . However, each square
loses some precision in rounding:
. However, each square
loses some precision in rounding:
Admittedly, while this example is contrived to show an absurd result, a negative sum of squares, the equally absurd value of zero is hardly unusual. Similar computations - differences of sum of squares - are routine, especially in regression and in the computation of eigenvalues and eigenvectors. In regression, the orthogonalization method (1.10) and (1.11) is more commonly seen in its general form. In all these cases, simply centering can improve the computational difficulty and reduce the effect of limited precision arithmetic.
Another problem with floating point arithmetic is the sheer
accumulation of rounding error. While many applications run well in
spite of a large number of calculations, some approaches encounter
surprising problems. An enlightening example is just to add up many
ones:
![]() . Astonishingly, this infinite series appears to
converge - the partial sums stop increasing as soon as the ratio of
the new number to be added, in this case, one, to the current sum
(
. Astonishingly, this infinite series appears to
converge - the partial sums stop increasing as soon as the ratio of
the new number to be added, in this case, one, to the current sum
(![]() ) drops below the machine epsilon. Following (1.5), we have
) drops below the machine epsilon. Following (1.5), we have
![]() , from which we find
, from which we find
One of the more interesting methods for dealing with the inaccuracies
of floating point arithmetic is interval arithmetic. The key is that
a computer can only do arithmetic operations: addition, subtraction,
multiplication, and division. The novel idea, though, is that instead
of storing the number ![]() , its lower and upper bounds
, its lower and upper bounds
![]() are stored, designating an interval for
are stored, designating an interval for ![]() . Bounds
for each of these arithmetic operations can be then established as
functions of the input. For addition, the relationship can be written
as:
. Bounds
for each of these arithmetic operations can be then established as
functions of the input. For addition, the relationship can be written
as: