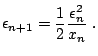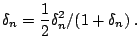An algorithm is a list of directed actions to accomplish a designated task. Cooking recipes are the best examples of algorithms in everyday life. The level of a cookbook reflect the skill of the cook: a gourmet cookbook may include the instruction ''saute the onion until transparent'' while a beginner's cookbook would describe how to choose and slice the onion, what kind of pan, the level of heat, etc. Since computers are inanimate objects incapable of thought, instructions for a computer algorithm must go much, much further to be completely clear and unambiguous, and include all details.
Most cooking recipes would be called single pass algorithms, since they are a list of commands to be completed in consecutive order. Repeating the execution of the same tasks, as in baking batches of cookies, would be described in algorithmic terms as looping. Looping is the most common feature in mathematical algorithms, where a specific task, or similar tasks, are to be repeated many times. The computation of an inner product is commonly implemented using a loop:
![]()
do ![]() to
to ![]()
![]()
end do
where the range of the loop includes the single statement
with a multiplication and addition. In an iterative
algorithm, the number of times the loop is be repeated is not known in
advance, but determined by some monitoring mechanism. For mathematical
algorithms, the focus is most often monitoring convergence of
a sequence or series. Care must be taken in implementing iterative
algorithms to insure that, at some point, the loop will be terminated,
otherwise an improperly coded procedure may proceed indefinitely in an
infinite loop. Surprises occur when the convergence of an
algorithm can be proven analytically, but, because of the discrete
nature of floating point arithmetic, the procedure implementing that
algorithm may not converge. For example, in a square-root problem to
be examined further momentarily, we cannot find
![]() so
that
so
that ![]() is exactly equal to
is exactly equal to ![]() . The square of one number
may be just below two, and the square of the next largest number in
. The square of one number
may be just below two, and the square of the next largest number in
![]() may be larger than
may be larger than ![]() . When monitoring convergence,
common practice is to convert any test for equality of two floating
point numbers or expressions to tests of closeness:
. When monitoring convergence,
common practice is to convert any test for equality of two floating
point numbers or expressions to tests of closeness:
algorithm sort(list)
break list into two pieces: first and second
sort (first)
sort (second)
put sorted lists first and second together to form
one sorted list
end algorithm sort
Implemented recursively, a big problem is quickly broken
into tiny pieces and the key to the performance of divide-and-conquer
algorithms is in combining the solutions to lots of little problems to
address the big problem. In cases where these solutions can be easily
combined, these recursive algorithms can achieve remarkable
breakthroughs in performance. In the case of sorting, the standard
algorithm, known as bubblesort, takes ![]() work to sort a problem
of size
work to sort a problem
of size ![]() - if the size of the problem is doubled, the work goes up
by factor of
- if the size of the problem is doubled, the work goes up
by factor of ![]() . The Discrete Fourier Transform, when written as the
multiplication of an
. The Discrete Fourier Transform, when written as the
multiplication of an
![]() matrix and a vector, involves
matrix and a vector, involves ![]() multiplications and additions. In both cases, the problem is broken
into two subproblems, and the mathematics of divide and conquer
follows a simple recursive relationship, that the time/work
multiplications and additions. In both cases, the problem is broken
into two subproblems, and the mathematics of divide and conquer
follows a simple recursive relationship, that the time/work ![]() to solve a problem of size
to solve a problem of size ![]() is the twice the time/work to solve
two subproblem with half the size, plus the time/work
is the twice the time/work to solve
two subproblem with half the size, plus the time/work ![]() , to put
the solutions together:
, to put
the solutions together:
The performance of an algorithm may be measured in many ways,
depending on the characteristics of the problems the it may be
intended to solve. The sample variance problem above provides an
example. The simple algorithm using (1.7) requires minimal
storage and computation, but may lose accuracy when the variance is
much smaller than the mean: the common test problem for exhibiting
catastrophic cancellation employs
![]() for single
precision. The two-pass method (1.8) requires all of the
observations to be stored, but provides the most accuracy and least
computation. Centering using the first observation (1.9) is
nearly as fast, requires no extra storage, and its accuracy only
suffers when the first observation is unlike the others. The last
method, arising from the use of Givens transformations (1.10)
and (1.11), also requires no extra storage, gives sound
accuracy, but requires more computation. As commonly seen in the
marketplace of ideas, the inferior methods have not survived, and the
remaining competitors all have tradeoffs with speed, storage, and
numerical stability.
for single
precision. The two-pass method (1.8) requires all of the
observations to be stored, but provides the most accuracy and least
computation. Centering using the first observation (1.9) is
nearly as fast, requires no extra storage, and its accuracy only
suffers when the first observation is unlike the others. The last
method, arising from the use of Givens transformations (1.10)
and (1.11), also requires no extra storage, gives sound
accuracy, but requires more computation. As commonly seen in the
marketplace of ideas, the inferior methods have not survived, and the
remaining competitors all have tradeoffs with speed, storage, and
numerical stability.
The most common difficult numerical problems in statistics involve optimization, or root-finding: maximum likelihood, nonlinear least squares, M-estimation, solving the likelihood equations or generalized estimating equations. And the algorithms for solving these problems are typically iterative algorithms, using the results from the current step to direct the next step.
To illustrate, consider the problem of computing the square root of
a real number ![]() . Following from the previous discussion of floating
point arithmetic, we can restrict
. Following from the previous discussion of floating
point arithmetic, we can restrict ![]() to the interval
to the interval ![]() . One
approach is to view the problem as a root-finding problem, that is, we
seek
. One
approach is to view the problem as a root-finding problem, that is, we
seek ![]() such that
such that
![]() . The bisection algorithm is
a simple, stable method for finding a root. In this case, we may
start with an interval known to contain the root, say
. The bisection algorithm is
a simple, stable method for finding a root. In this case, we may
start with an interval known to contain the root, say ![]() ,
with
,
with ![]() and
and ![]() . Then bisection tries
. Then bisection tries ![]() ,
the midpoint of the current interval. If
,
the midpoint of the current interval. If ![]() , then
, then
![]() , and the root is known to belong in the new
interval
, and the root is known to belong in the new
interval ![]() . The algorithm continues by testing the midpoint
of the current interval, and eliminating half of the interval. The
rate of convergence of this algorithm is linear, since the interval of
uncertainty, in this case, is cut by a constant
. The algorithm continues by testing the midpoint
of the current interval, and eliminating half of the interval. The
rate of convergence of this algorithm is linear, since the interval of
uncertainty, in this case, is cut by a constant ![]() with each
step. For other algorithms, we may measure the rate at which the
distance from the root decreases. Adapting Newton's method to this
root-finding problem yields Heron's iteration
with each
step. For other algorithms, we may measure the rate at which the
distance from the root decreases. Adapting Newton's method to this
root-finding problem yields Heron's iteration
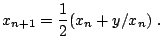 |
While we can stop this algorithm when ![]() , as discussed
previously, there may not be any floating point number that will give
a zero to the function, hence the stopping rule (1.12). Often
in root-finding problems, we stop when
, as discussed
previously, there may not be any floating point number that will give
a zero to the function, hence the stopping rule (1.12). Often
in root-finding problems, we stop when ![]() is small enough. In
some problems, the appropriate ''small enough'' quantity to ensure
the desired accuracy may depend on parameters of the problem, as in
this case, the value of
is small enough. In
some problems, the appropriate ''small enough'' quantity to ensure
the desired accuracy may depend on parameters of the problem, as in
this case, the value of ![]() . As a result, termination criterion for
the algorithm is changed to: stop when the relative change in
. As a result, termination criterion for
the algorithm is changed to: stop when the relative change in ![]() is
small
is
small
As discussed previously, rounding error with floating point
computation affects the level of accuracy that is possible with
iterative algorithms for root-finding. In general, the relative error
in the root is at the same relative level as the computation of the
function. While optimization problems have many of the same
characteristics as root-finding problems, the effect of computational
error is a bit more substantial: ![]() digits of accuracy in the
function to be optimization can produce but
digits of accuracy in the
function to be optimization can produce but ![]() digits in the
root/solution.
digits in the
root/solution.
In the multidimensional case, the common problems are solving a system
of nonlinear equations or optimizing a function of several variables.
The most common tools for these problems are Newton's method or
secant-like variations. Given the appropriate regularity conditions,
again we can achieve quadratic convergence with Newton's method, and
superlinear convergence with secant-like variations. In the case of
optimization, we seek to minimize ![]() , and Newton's method is based
on minimizing the quadratic approximation:
, and Newton's method is based
on minimizing the quadratic approximation:
![$\displaystyle \boldsymbol{x}^{(n+1)} = \boldsymbol{x}^{(n)} - \left[ \boldsymbo...
...}\right) \right]^{-1} \boldsymbol{\nabla} f\left(\boldsymbol{x}^{(n)}\right)\;.$](img471.gif) |
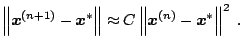 |
In both problems, the scaling of the parameters is quite important, as measuring the error with the Euclidean norm presupposes that errors in each component are equally weighted. Most software for optimization includes a parameter vector for suitably scaling the parameters, so that one larger parameter does not dominate the convergence decision. In solving nonlinear equations, the condition of the problem is given by
![$\displaystyle \left \Vert \boldsymbol{J}_{\boldsymbol{g}} \left(\boldsymbol{x}^...
...l{J}_{\boldsymbol{g}}\left(\boldsymbol{x}^{(n)}\right)\right]^{-1} \right \Vert$](img479.gif) |
With the optimization problem, there is a natural scaling with
![]() in contrast with the Jacobian matrix.
Here, the eigenvectors of the Hessian matrix
in contrast with the Jacobian matrix.
Here, the eigenvectors of the Hessian matrix
![]() dictate the condition of the
problem; see, for example, [4] and [3]. Again,
parameter scaling remains one of the most important tools.
dictate the condition of the
problem; see, for example, [4] and [3]. Again,
parameter scaling remains one of the most important tools.