The Bootstrap for dependent data is a lively research area. A lot of ideas are around and have let to quite different proposals. In this section we do not want to give a detailed overview and description of the different proposals. We only want to sketch the main ideas. Models for dependent data may principally differ from i.i.d. models. For dependent data the data generating process is often not fully specified. Then there exists no unique natural way for resampling. The resampling should be carried out in such a way that the dependence structure should be captured. This can be easily done in case of classical finite-dimensional ARMA models with i.i.d. residuals. In these models the resamples can be generated by fitting the parameters and by using i.i.d. residuals in the resampling. We will discuss the situation when no finite-dimensional model is assumed. For other overviews on the bootstrap for time series analysis, see [12,30,70] and the time series chapter in [18] and the book [49]. In particular, [30] give an overview over the higher order performance of the different resampling schemes.
The most popular bootstrap methods for dependent data are block, sieve, local, wild and Markov bootstrap and subsampling. They all are nonparametric procedures.
The method that works under a minimal amount of assumptions is the
subsampling. It is used to approximate the distribution of an
estimate
![]() estimating an unknown parameter
estimating an unknown parameter ![]() .
In the
subsampling subsamples of consecutive observations of length
.
In the
subsampling subsamples of consecutive observations of length ![]() are taken. These subsamples are drawn randomly from the whole
time series. For the subsamples estimates
are taken. These subsamples are drawn randomly from the whole
time series. For the subsamples estimates
![]() are
calculated. If it is known that for a sequence
are
calculated. If it is known that for a sequence ![]() the statistic
the statistic
![]() has a limiting distribution then under
very weak conditions the conditional distribution of
has a limiting distribution then under
very weak conditions the conditional distribution of
![]() has the same limiting
distribution. Higher order considerations show that the
subsampling has a very poor rate of convergence, see [35]. It does not even achieve the rate of convergence
of a normal approximation. It may be argued that this poor
performance is the price for its quite universal applicability.
Subsampling has also been used in i.i.d. settings where classical
bootstrap does not work. For a detailed discussion of the
subsampling see [72].
has the same limiting
distribution. Higher order considerations show that the
subsampling has a very poor rate of convergence, see [35]. It does not even achieve the rate of convergence
of a normal approximation. It may be argued that this poor
performance is the price for its quite universal applicability.
Subsampling has also been used in i.i.d. settings where classical
bootstrap does not work. For a detailed discussion of the
subsampling see [72].
The basic idea of the
block
bootstrap is closely related to the i.i.d. nonparametric
bootstrap. Both procedures are based on drawing observations with
replacement. In the block
bootstrap however instead of single observations blocks of consecutive
observations are drawn. This is done to capture the dependence
structure of neighbored observations. Different versions of this idea
have been proposed in [31,13,45,54] and [71]. It has been shown that this approach works
for a large class of stationary processes. The blocks of consecutive
observations are drawn with replacement from a set of blocks. In the
first proposal this was done for a set of nonoverlapping blocks of
fixed length ![]() :
:
![]() ,
,
![]() Later papers proposed to use all (also
overlapping) blocks of length
Later papers proposed to use all (also
overlapping) blocks of length ![]() , i.e. the
, i.e. the ![]() -th block consists of
the observations
-th block consists of
the observations
![]() (Moving block
bootstrap). The
bootstrap resample is obtained by sampling
(Moving block
bootstrap). The
bootstrap resample is obtained by sampling ![]() blocks randomly with
replacement and putting them together to a
time series of length
blocks randomly with
replacement and putting them together to a
time series of length ![]() . By construction, the
bootstrap
time series has a nonstationary (conditional) distribution. The
resample becomes stationary if the block length
. By construction, the
bootstrap
time series has a nonstationary (conditional) distribution. The
resample becomes stationary if the block length ![]() is random and
generated from a geometric distribution. This version of the block
bootstrap is called the stationary bootstrap and was introduced in
[71]. Recently, [65,67] proposed another
modification that uses tapering methods to smooth the effects of
boundaries between neighbored blocks. With respect to higher order
properties the moving block
bootstrap outperforms the version with non overlapping blocks and both
achieve a higher order accuracy as the stationary
bootstrap (see [34,46,47,49]).
is random and
generated from a geometric distribution. This version of the block
bootstrap is called the stationary bootstrap and was introduced in
[71]. Recently, [65,67] proposed another
modification that uses tapering methods to smooth the effects of
boundaries between neighbored blocks. With respect to higher order
properties the moving block
bootstrap outperforms the version with non overlapping blocks and both
achieve a higher order accuracy as the stationary
bootstrap (see [34,46,47,49]).
The block bootstrap has turned out as a very powerful method for dependent data. It does not achieve the accuracy of the bootstrap for i.i.d. data but it outperforms the subsampling. It works reasonably well under very weak conditions on the dependency structure. It has been applied to a very broad range of applications. For the block bootstrap no specific assumption is made on the structure of the data generating process.
We now describe some methods that use more specific assumptions on the dependency structure.
The i.i.d. resampling can also be applied to models of dependent data where the stochastics is driven by i.i.d. innovations. The distribution of the innovations can be estimated by using fitted residuals. In the resampling i.i.d. innovations can be generated by i.i.d. resampling from this fitted distribution. An example is an autoregressive linear model:
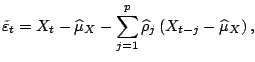 |
In a series of papers this approach has been studied for the case that
model (2.3) only approximately holds. This is the case
if the underlying
time series is a stationary linear process, i.e. ![]() has an
infinite order autoregressive representation:
has an
infinite order autoregressive representation:
Another residual based bootstrap scheme has been proposed for a nonparametric autoregression model:
[25] also consider two other bootstrap procedures for the model (2.6): the regression bootstrap and the wild bootstrap. In the regression bootstrap, a nonparametric regression model is generated with (conditionally) fixed design. We describe this approach for the case of a homoscedasstic autoregression model:
Modifications of the regression
bootstrap are the
local
bootstrap ([64]) and the
wild
bootstrap. The
wild
bootstrap also uses a regression model with (conditionally) fixed
covariables. But it is designed to work also for heteroscedastic
errors. It has been first proposed for regression models with
independent but not identically distributed error variables, see [78,1]. For nonparametric models
it was first proposed in [29]. In the
nonparametric autoregression model (2.7)
wild
bootstrap resamples are generated as in (2.8). But now
the error variables
![]() are generated as
are generated as
![]() where
where
![]() are centered fitted residuals and where
are centered fitted residuals and where
![]() are (conditionally) i.i.d. variables with
conditional zero mean and conditional unit variance (given the
original sample). For achieving higher order accuracy it has also
been proposed to use
are (conditionally) i.i.d. variables with
conditional zero mean and conditional unit variance (given the
original sample). For achieving higher order accuracy it has also
been proposed to use ![]() with conditional third moment equal
to
with conditional third moment equal
to ![]() . One could argue that in this
resampling scheme the distribution of
. One could argue that in this
resampling scheme the distribution of
![]() is fitted by the
conditional distribution of
is fitted by the
conditional distribution of ![]() . Then
. Then ![]() different
distributions are fitted in a model where only
different
distributions are fitted in a model where only ![]() observations are
available. This is the reason why in [29] this approach was called
wild
bootstrap. For a more detailed discussion of the
wild
bootstrap, see [52,53,56,57,58]. The asymptotic
analysis of the
wild
bootstrap and other
regression type
bootstrap methods in model (2.7) is much simpler than the
autoregression
bootstrap. In the
bootstrap world it only requires mathematical analysis of
a nonparametric regression model. Only the discussion of uniform
nonparametric confidence bands remains rather complicated because it
involves strong approximations of the
bootstrap nonparametric regression estimates by Gaussian processes,
see [62]. The
wild
bootstrap works under quite weak model assumptions. Essentially it is
only assumed that the conditional expectation of an observation given
the past is a smooth function of the last
observations are
available. This is the reason why in [29] this approach was called
wild
bootstrap. For a more detailed discussion of the
wild
bootstrap, see [52,53,56,57,58]. The asymptotic
analysis of the
wild
bootstrap and other
regression type
bootstrap methods in model (2.7) is much simpler than the
autoregression
bootstrap. In the
bootstrap world it only requires mathematical analysis of
a nonparametric regression model. Only the discussion of uniform
nonparametric confidence bands remains rather complicated because it
involves strong approximations of the
bootstrap nonparametric regression estimates by Gaussian processes,
see [62]. The
wild
bootstrap works under quite weak model assumptions. Essentially it is
only assumed that the conditional expectation of an observation given
the past is a smooth function of the last ![]() observations (for some
finite
observations (for some
finite ![]() ). Generality has its price.
Resampling schemes that use more detailed modeling may achieve
a better accuracy. We now consider
resampling under the stronger assumption that not only the mean but
also the whole conditional distribution of an observation smoothly
depends on the last
). Generality has its price.
Resampling schemes that use more detailed modeling may achieve
a better accuracy. We now consider
resampling under the stronger assumption that not only the mean but
also the whole conditional distribution of an observation smoothly
depends on the last ![]() observations (for some finite
observations (for some finite ![]() ).
Resampling schemes that work under this smooth Markov assumption are
the
Markov
Bootstrap schemes.
).
Resampling schemes that work under this smooth Markov assumption are
the
Markov
Bootstrap schemes.
We discuss the
Markov
bootstrap for a Markov model of order ![]() . We will describe two
implementations of the
Markov
bootstrap. For both implementations one has to assume that the
conditional distribution of
. We will describe two
implementations of the
Markov
bootstrap. For both implementations one has to assume that the
conditional distribution of ![]() given
given
![]() smoothly
depends on
smoothly
depends on ![]() . The first version was introduced by [73]. It is based on a nonparametric estimate of the
transition density
. The first version was introduced by [73]. It is based on a nonparametric estimate of the
transition density ![]() of
of ![]() given
given ![]() . Using
kernel density estimates of the density of
. Using
kernel density estimates of the density of ![]() and of the joint
density of
and of the joint
density of
![]() one can estimate
one can estimate ![]() by
by
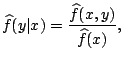 |
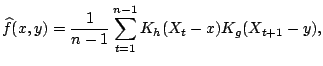 |
|
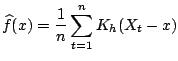 |
The second version of the
Markov
bootstrap can be described as a limiting version of the latter for ![]() . Then in the limiting case the
bootstrap process takes values only in the set of observations
. Then in the limiting case the
bootstrap process takes values only in the set of observations
![]() . Given
. Given
![]() , the next observation
, the next observation
![]() is equal to
is equal to ![]()
![]() with probability
with probability
![]() . This
resampling scheme was introduced in [66,68]. Higher order properties are not yet
known. It may be expected that it has similar asymptotic properties
as the smoothed version of the
Markov
bootstrap. The unsmoothed version has the advantage that the
bootstrap
time series is forced to live on the observed values of the original
time series. This leads to a more stable dynamic of the
bootstrap
time series, in particular for smaller sample sizes. Furthermore, for
higher dimensional Markov processes the unsmoothed version is based on
only
. This
resampling scheme was introduced in [66,68]. Higher order properties are not yet
known. It may be expected that it has similar asymptotic properties
as the smoothed version of the
Markov
bootstrap. The unsmoothed version has the advantage that the
bootstrap
time series is forced to live on the observed values of the original
time series. This leads to a more stable dynamic of the
bootstrap
time series, in particular for smaller sample sizes. Furthermore, for
higher dimensional Markov processes the unsmoothed version is based on
only ![]() dimensional kernel density smoothing whereas smoothed
bootstrap requires
dimensional kernel density smoothing whereas smoothed
bootstrap requires ![]() dimensional kernel smoothing. Here,
dimensional kernel smoothing. Here,
![]() denotes the dimension of the Markov process. Again, one can argue
that this leads to a more stable finite sample performance of
unsmoothed
bootstrap. On the other hand, the smoothed
Markov
bootstrap takes advantage of smoothness of
denotes the dimension of the Markov process. Again, one can argue
that this leads to a more stable finite sample performance of
unsmoothed
bootstrap. On the other hand, the smoothed
Markov
bootstrap takes advantage of smoothness of ![]() with respect
to
with respect
to ![]() . For larger data sets this may lead to improvements, in case
of smooth transition densities.
. For larger data sets this may lead to improvements, in case
of smooth transition densities.
For the periodogram
![]() it is known that its
values for
it is known that its
values for
![]() ,
,
![]() are asymptotically
independent. For the first two moments one gets that for
are asymptotically
independent. For the first two moments one gets that for
![]()
In this
resampling
bootstrap values
![]() of the periodogram
of the periodogram
![]() are generated. The
resampling uses two estimates
are generated. The
resampling uses two estimates
![]() and
and ![]() of the
spectral density. In some implementations these estimates can be
chosen identically. The first estimate is used for fitting residuals
of the
spectral density. In some implementations these estimates can be
chosen identically. The first estimate is used for fitting residuals
![]() . The
bootstrap residuals
. The
bootstrap residuals
![]() are drawn with replacement
from the centered fitted residuals
are drawn with replacement
from the centered fitted residuals
![]() where
where
![]() is the average of
is the average of
![]() over
over
![]() . The
bootstrap periodogram is then calculated by putting
. The
bootstrap periodogram is then calculated by putting
![]() .
.
The
frequency domain
bootstrap can be used to estimate the distribution of statistics
![]() . Then the distribution
of
. Then the distribution
of
![]() is estimated by the conditional distribution of
is estimated by the conditional distribution of
![]() . Unfortunately, in general this approach
does not work. This can be easily seen by a comparison of the
asymptotic variances of the statistics. The original statistic
. Unfortunately, in general this approach
does not work. This can be easily seen by a comparison of the
asymptotic variances of the statistics. The original statistic
![]() has variance that is
asymptotically equivalent to
has variance that is
asymptotically equivalent to
![$\displaystyle n^{-1} \sum w_j^2 f(\omega_j)^2 + \left [ \frac{\mathrm{E} \left[...
...psilon_j^2\right]^2}- 3 \right ]\left [ n^{-1} \sum w_j f(\omega_j)\right]^2{},$](img3771.gif) |
Although the frequency domain bootstrap does not work in general, there exist three important examples where it works. In all three examples the second term in the asymptotic expansion of the variance vanishes. This happens e.g. if the kurtosis of the innovations is equal to zero:
![$\displaystyle \frac{\mathrm{E} \left[\varepsilon_j^4\right]}{\mathrm{E} \left[ \varepsilon_j^2\right]^2}- 3 = 0{}.$](img3773.gif) |
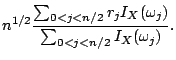 |
![$\displaystyle n^{1/2} \left [\frac{\sum_{0< j < n/2} r_j I_X(\omega_j)} {\sum_{...
...\frac{\sum_{0< j < n/2} r_j f(\omega_j)}{\sum_{0< j < n/2} f(\omega_j)}\right ]$](img3776.gif) |
|
![$\displaystyle \approx n^{-1/2} \sum_{0< j < n/2} \left[w_j I_X(\omega_j) - w_j f(\omega_j) \right]$](img3777.gif) |
There exists also another example where the
frequency domain
bootstrap works. Nonparametric smoothing estimates of the spectral
density are linear statistics where the weights ![]() are now local.
For example for kernel smoothing weights
are now local.
For example for kernel smoothing weights
![]() with bandwidth
with bandwidth ![]() and kernel function
and kernel function ![]() one has
one has
![]() . On the other hand,
. On the other hand,
![]() is of lower order. Now, both
the variance of the original spectral density estimate and the
variance of the
bootstrap spectral density estimate have variance that is up to terms
of order
is of lower order. Now, both
the variance of the original spectral density estimate and the
variance of the
bootstrap spectral density estimate have variance that is up to terms
of order ![]() is equal to the same quantity
is equal to the same quantity
![]() . The correlation between
. The correlation between
![]() and
and
![]() for
for
![]() (see (2.11)) only contributes
to higher order terms. [23] firstly
observed this relation and used this fact to show that the
frequency domain
bootstrap works for nonparametric spectral density estimation. In
their approach, both
(see (2.11)) only contributes
to higher order terms. [23] firstly
observed this relation and used this fact to show that the
frequency domain
bootstrap works for nonparametric spectral density estimation. In
their approach, both
![]() and
and ![]() are nonparametric
kernel smoothing estimates. For
are nonparametric
kernel smoothing estimates. For ![]() a bandwidth has been
chosen that is of larger order than the bandwidth
a bandwidth has been
chosen that is of larger order than the bandwidth ![]() . Then
bootstrap consistently estimates the bias of the spectral density
estimate. Similar approaches have been used in
bootstrap schemes for other settings of
nonparametric curve estimation, see [59]. For
the
frequency domain
bootstrap for parametric problems one can choose
. Then
bootstrap consistently estimates the bias of the spectral density
estimate. Similar approaches have been used in
bootstrap schemes for other settings of
nonparametric curve estimation, see [59]. For
the
frequency domain
bootstrap for parametric problems one can choose
![]() , see [16].
, see [16].
We now have discussed a large class of resampling schemes for dependent data. They are designed for different assumptions on the dependency structure ranging from quite general stationarity assumptions (subsampling), mixture conditions (block bootstrap), linearity assumptions (sieve bootstrap, frequency domain bootstrap), conditional mean Markov property (wild bootstrap), Markov properties (Markov bootstrap) and autoregressive structure (autoregressive bootstrap). It may be generally conjectured that resampling schemes for more restrictive models are more accurate as long as these more restrictive assumptions really apply. These conjectures are supported by asymptotic results based on higher order Edgeworth expansions. (Although these results should be interpreted with care because of the poor performance of higher order Edgeworth expansions for finite samples, see also the discussion in the introduction.) The situation is also complicated by the fact that in time series analysis typically models are used as approximations to the truth and they are not interpreted as true models. Thus one has to study the much more difficult problem how resampling schemes perform if the underlying assumptions are only approximately fulfilled.
Resampling for dependent data has stimulated very creative ideas and discussions and it had lead to a large range of different approaches. Partially, the resampling structure is quite different from the stochastic structure of the original time series. In the regression bootstrap regression data are used instead of autoregression series. In the sieve bootstrap and in the frequency domain bootstrap models are used that only approximate the original model.
For dependent data the bootstrap has broadened the field of possible statistical applications. The bootstrap offered new ways of implementing statistical procedures and made it possible to treat new types of applied problems by statistical inference.
The discussion of the bootstrap for dependent data is not yet finished. For the comparison of the proposed resampling schemes a complete understanding is still missing and theoretical research is still going on. Applications of time series analysis will also require new approaches. Examples are unit root tests, cointegration analysis and the modeling of financial time series.
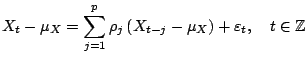
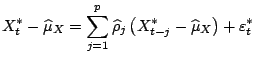
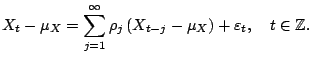
![$\displaystyle \mathrm{Cov} [I_X(\omega_j), I_X(\omega_k)] = n^{-1} f(\omega_j) ...
...\right]}{\mathrm{E} \left[\varepsilon_j^2\right]^2} - 3 \right ] + o(n^{-1}){},$](img3754.gif)