Let's return to the example in Fig. 3.1. If the analysts are interested in the input/output behavior within 'local area 1', then a first-order polynomial may be adequate. Maybe, a second-order polynomial is required to get a valid approximation in 'local area 2', which is larger and shows non-linear behavior of the input/output function. However, Kleijnen and Van Beers (2003a) present an example illustrating that the second-order polynomial gives very poor predictions - compared with Kriging.
Kriging has been often applied in deterministic simulation models. Such simulations are used for the development of airplanes, automobiles, computer chips, computer monitors, etc.; see Sacks et al. (1989)'s pioneering article, and - for an update - see Simpson et al. (2001). For Monte Carlo experiments, I do not know any applications yet. First, I explain the basics of Kriging; then DOE aspects.
Kriging is an interpolation method that predicts unknown values of a random process; see the classic textbook on Kriging in spatial statistics, Cressie (1993). More precisely, a Kriging prediction is a weighted linear combination of all output values already observed. These weights depend on the distances between the input for which the output is to be predicted and the inputs already simulated. Kriging assumes that the closer the inputs are, the more positively correlated the outputs are. This assumption is modeled through the correlogram or the related variogram, discussed below.
Note that in deterministic simulation, Kriging has an important advantage over regression analysis: Kriging is an exact interpolator; that is, predicted values at observed input values are exactly equal to the observed (simulated) output values. In random simulation, however, the observed output values are only estimates of the true values, so exact interpolation loses its intuitive appeal. Therefore regression uses OLS, which minimizes the residuals - squared and summed over all observations.
The simplest type of Kriging - to which I restrict myself in this
chapter - assumes the following metamodel (also see
(3.4) with
![]() and
and
![]() :
:
The Kriging predictor for the unobserved input
![]() - denoted by
- denoted by
![]() - is
a weighted linear combination of all the
- is
a weighted linear combination of all the ![]() output data already
observed -
output data already
observed -
![]() :
:
To quantify the weights
![]() in (3.14), Kriging
derives the best linear unbiased estimator (BLUE), which
minimizes the Mean Squared Error (MSE) of the predictor:
in (3.14), Kriging
derives the best linear unbiased estimator (BLUE), which
minimizes the Mean Squared Error (MSE) of the predictor:
![]() : vector of the
: vector of the ![]() (co)variances between the
output at the new input
(co)variances between the
output at the new input
![]() and the outputs at the
and the outputs at the ![]() old inputs, so
old inputs, so
![]()
![]() :
:
![]() matrix of the covariances between the
outputs at the
matrix of the covariances between the
outputs at the ![]() old inputs - with element (
old inputs - with element (![]() ) equal to
) equal to
![]()
![]() : vector of
: vector of ![]() ones.
ones.
I point out that the optimal weights defined by (3.15) vary with
the input value for which output is to be predicted (see
![]() ), whereas linear regression uses the same estimated
parameters
), whereas linear regression uses the same estimated
parameters
![]() for all inputs to be predicted.
for all inputs to be predicted.
The most popular design type for Kriging is Latin hypercube sampling (LHS). This design type was invented by McKay, Beckman, and Conover (1979) for deterministic simulation models. Those authors did not analyze the input/output data by Kriging (but they did assume input/output functions more complicated than the low-order polynomials in classic DOE). Nevertheless, LHS is much applied in Kriging nowadays, because LHS is a simple technique (it is part of spreadsheet add-ons such as @Risk).
LHS offers flexible design sizes ![]() (number of scenarios
simulated) for any number of simulation inputs,
(number of scenarios
simulated) for any number of simulation inputs, ![]() . A simplistic
example is shown for
. A simplistic
example is shown for ![]() and
and ![]() in Table 3.5 and
Fig. 3.4, which are constructed as follows.
in Table 3.5 and
Fig. 3.4, which are constructed as follows.
| Scenario | Interval factor 1 | Interval factor 2 |
Because LHS implies randomness, the resulting design may happen to
include outlier scenarios (to be simulated). Furthermore, it
might happen - with small probability - that in Fig. 3.4 all
scenarios lie on the main diagonal, so the values of the two inputs
have a correlation coefficient of ![]() . Therefore LHS may be adjusted
to give (nearly) orthogonal designs; see Ye (1998).
. Therefore LHS may be adjusted
to give (nearly) orthogonal designs; see Ye (1998).
Let's compare classic designs and LHS geometrically. Figure 3.3
illustrates that many classic designs consists of corners of
![]() -dimensional cubes. These designs imply simulation of
extreme scenarios. LHS, however, has better space
filling properties.
-dimensional cubes. These designs imply simulation of
extreme scenarios. LHS, however, has better space
filling properties.
This property has inspired many statisticians to develop other space
filling designs. One type maximizes the minimum Euclidean distance
between any two points in the ![]() -dimensional experimental
area. Related designs minimize the maximum distance. See Koehler and
Owen (1996), Santner et al. (2003), and also Kleijnen et al. (2003a).
-dimensional experimental
area. Related designs minimize the maximum distance. See Koehler and
Owen (1996), Santner et al. (2003), and also Kleijnen et al. (2003a).
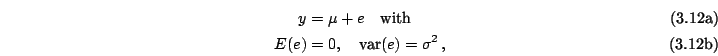
![\begin{subequations}\begin{align}\widehat{y}(\boldsymbol{x}_{0} )&=\sum\limits_{...
...-3mm] \sum \limits_{i = 1}^{n} \lambda _{i} &= 1\,,\end{align}\end{subequations}](img3876.gif)
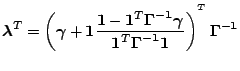
![\includegraphics[clip]{text/3-3/fig4.eps}](img3891.gif)