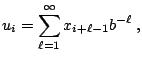The most widely used RNGs are based on the linear recurrence
A multiple recursive generator (MRG) uses (2.2)
with a large value of ![]() and defines the output as
and defines the output as
![]() .
For
.
For ![]() , this is the classical linear congruential
generator (LCG).
In practice, the output function is modified slightly to make sure
that
, this is the classical linear congruential
generator (LCG).
In practice, the output function is modified slightly to make sure
that ![]() never takes the value 0 or
never takes the value 0 or ![]() (e.g., one may define
(e.g., one may define
![]() , or
, or
![]() if
if ![]() and
and
![]() otherwise) but to simplify the theoretical analysis, we will
follow the common convention of assuming that
otherwise) but to simplify the theoretical analysis, we will
follow the common convention of assuming that
![]() (in which
case
(in which
case ![]() does take the value 0 occasionally).
does take the value 0 occasionally).
Let
![]() denote the
denote the ![]() th unit vector in
th unit vector in ![]() dimensions, with a
dimensions, with a ![]() in position
in position ![]() and 0's elsewhere. Denote by
and 0's elsewhere. Denote by
![]() the values of
the values of
![]() produced by the
recurrence (2.2) when the initial state
produced by the
recurrence (2.2) when the initial state
![]() is
is
![]() .
An arbitrary initial state
.
An arbitrary initial state
![]() can be
written as the linear combination
can be
written as the linear combination
![]() and
the corresponding sequence is a linear combination of the sequences
and
the corresponding sequence is a linear combination of the sequences
![]() , with reduction of the coordinates
modulo
, with reduction of the coordinates
modulo ![]() . Reciprocally, any such linear combination reduced
modulo
. Reciprocally, any such linear combination reduced
modulo ![]() is a sequence that can be obtained from some initial state
is a sequence that can be obtained from some initial state
![]() . If we divide everything by
. If we divide everything by ![]() we find
that for the MRG, for each
we find
that for the MRG, for each ![]() ,
,
![]() where
where
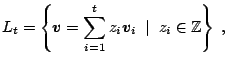 |
This lattice structure implies that the points of ![]() are
distributed according to a very regular pattern, in equidistant
parallel hyperplanes. Graphical illustrations of this, usually for
LCGs, can be found in a myriad of papers and books; e.g.,
[23,31,34], and [40].
Define the dual lattice to
are
distributed according to a very regular pattern, in equidistant
parallel hyperplanes. Graphical illustrations of this, usually for
LCGs, can be found in a myriad of papers and books; e.g.,
[23,31,34], and [40].
Define the dual lattice to ![]() as
as
The lattice property holds as well for the point sets ![]() formed
by values at arbitrary lags defined by a fixed set of indices
formed
by values at arbitrary lags defined by a fixed set of indices
![]() . One has
. One has
![]() for some
lattice
for some
lattice ![]() , and the largest distance between successive hyperplanes
for a family of hyperplanes that cover all the points of
, and the largest distance between successive hyperplanes
for a family of hyperplanes that cover all the points of ![]() is
is
![]() , where
, where ![]() is the euclidean length of a shortest
nonzero vector in
is the euclidean length of a shortest
nonzero vector in
![]() , the dual lattice to
, the dual lattice to ![]() .
.
The lattice ![]() and its dual can be constructed as explained in
[10] and [49]. Finding the shortest nonzero
vector in a lattice with basis
and its dual can be constructed as explained in
[10] and [49]. Finding the shortest nonzero
vector in a lattice with basis
![]() can be formulated
as an integer programming problem with a quadratic objective function:
can be formulated
as an integer programming problem with a quadratic objective function:
Minimize 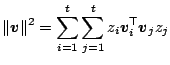 |
For any given dimension ![]() and
and ![]() points per unit of volume, there
is an absolute upper bound on the best possible value of
points per unit of volume, there
is an absolute upper bound on the best possible value of ![]() ([8,31,42]). Let
([8,31,42]). Let
![]() denote such
an upper bound.
To define a figure of merit that takes into account several sets
denote such
an upper bound.
To define a figure of merit that takes into account several sets ![]() ,
in different numbers of dimensions, it is common practice to divide
,
in different numbers of dimensions, it is common practice to divide
![]() by an upper bound, in order to obtain a standardized value
between 0 and
by an upper bound, in order to obtain a standardized value
between 0 and ![]() , and then take the worst case over a given class
, and then take the worst case over a given class
![]() of sets
of sets ![]() .
This gives a figure of merit of the form
.
This gives a figure of merit of the form
An important observation is that for ![]() , the
, the ![]() -dimensional
vector
-dimensional
vector
![]() always belongs to
always belongs to
![]() , because for any vector
, because for any vector
![]() , the first
, the first ![]() coordinates of
coordinates of
![]() must satisfy the recurrence (2.2),
which implies that
must satisfy the recurrence (2.2),
which implies that
![]() must be an
integer. Therefore, one always has
must be an
integer. Therefore, one always has
![]() . Likewise, if
. Likewise, if ![]() contains 0 and all indices
contains 0 and all indices ![]() such that
such that
![]() , then
, then
![]() ([39]). This means that the sum of squares of the
coefficients
([39]). This means that the sum of squares of the
coefficients ![]() must be large if we want to have any
chance that the lattice structure be good.
must be large if we want to have any
chance that the lattice structure be good.
Contructing MRGs with only two nonzero coefficients and taking these
coefficients small has been a very popular idea, because this makes
the implementation easier and faster ([14,31]).
However, MRGs thus obtained have a bad structure. As a worst-case
illustration, consider the widely-available additive or subtractive
lagged-Fibonacci generator,
based on the recurrence (2.2) where the two coefficients
![]() and
and ![]() are both equal to
are both equal to ![]() . In this case, whenever
. In this case, whenever ![]() contains
contains
![]() , one has
, one has
![]() , so the distance
between the hyperplanes is at least
, so the distance
between the hyperplanes is at least
![]() . In particular, for
. In particular, for
![]() , all the points of
, all the points of ![]() (aside from the zero
vector) are contained in only two planes! This type of structure can
have a dramatic effect on certain simulation problems and is a good
reason for staying away from these lagged-Fibonacci generators,
regardless of their parameters.
(aside from the zero
vector) are contained in only two planes! This type of structure can
have a dramatic effect on certain simulation problems and is a good
reason for staying away from these lagged-Fibonacci generators,
regardless of their parameters.
A similar problem occurs for the ''fast MRG'' proposed by [14], based on the recurrence
| (2.4) |
To get around this structural problem when ![]() contains certain sets
of indices, [70] and [31] recommend to skip some
of the output values in order to break up the bad vectors. For the
lagged-Fibonacci generator, for example, one can output
contains certain sets
of indices, [70] and [31] recommend to skip some
of the output values in order to break up the bad vectors. For the
lagged-Fibonacci generator, for example, one can output ![]() successive
values produced by the recurrence, then skip the next
successive
values produced by the recurrence, then skip the next ![]() values,
output the next
values,
output the next ![]() , skip the next
, skip the next ![]() , and so on. A large value
of
, and so on. A large value
of ![]() (e.g.,
(e.g., ![]() or more) may get rid of the bad structure, but
slows down the generator. See [98] for further discussion.
or more) may get rid of the bad structure, but
slows down the generator. See [98] for further discussion.
The modulus ![]() is often taken as a large prime number close to the
largest integer directly representable on the computer (e.g., equal or
near
is often taken as a large prime number close to the
largest integer directly representable on the computer (e.g., equal or
near ![]() for 32-bit computers). Since each
for 32-bit computers). Since each ![]() can be as
large as
can be as
large as ![]() , one must be careful in computing the right side
of (2.2) because the product
, one must be careful in computing the right side
of (2.2) because the product
![]() is typically
not representable as an ordinary integer. Various techniques for
computing this product modulo
is typically
not representable as an ordinary integer. Various techniques for
computing this product modulo ![]() are discussed and compared by
[21,48,41], and [56].
Note that if
are discussed and compared by
[21,48,41], and [56].
Note that if
![]() , using
, using ![]() is equivalent to using
the negative coefficient
is equivalent to using
the negative coefficient ![]() , which is sometimes more convenient
from the implementation viewpoint. In what follows, we assume that
, which is sometimes more convenient
from the implementation viewpoint. In what follows, we assume that
![]() can be either positive or negative.
can be either positive or negative.
One approach is to perform the arithmetic modulo ![]() in
in ![]() -bit
(double precision) floating-point arithmetic ([41]).
Under this representation, assuming that the usual IEEE floating-point
standard is respected, all positive integers up to
-bit
(double precision) floating-point arithmetic ([41]).
Under this representation, assuming that the usual IEEE floating-point
standard is respected, all positive integers up to ![]() are
represented exactly. Then, if each coefficient
are
represented exactly. Then, if each coefficient ![]() is selected to
satisfy
is selected to
satisfy
![]() , the product
, the product
![]() will
always be represented exactly and
will
always be represented exactly and
![]() can be
computed by the instructions
can be
computed by the instructions
A second technique,
called approximate factoring ([48]), uses only the
integer representation and works under the condition that ![]() or
or
![]() for some integer
for some integer
![]() . One
precomputes
. One
precomputes
![]() and
and
![]() .
Then,
.
Then,
![]() can be computed by
can be computed by
| if |
The powers-of-two decomposition approach selects coefficients
![]() that can be written as a sum or difference of a small number of
powers of
that can be written as a sum or difference of a small number of
powers of ![]() ([99,56,62]). For example, one may take
([99,56,62]). For example, one may take
![]() and
and
![]() for some positive
integers
for some positive
integers ![]() ,
, ![]() ,
, ![]() , and
, and ![]() . To compute
. To compute
![]() ,
decompose
,
decompose
![]() (where
(where
![]() mod
mod![]() ) and
observe that
) and
observe that
| (2.5) |
Another interesting idea for improving efficiency is to take all
nonzero coefficients ![]() equal to the same constant
equal to the same constant ![]() ([72,15]). Then, computing the right side
of (2.2) requires a single multiplication. [15]
provide specific parameter sets and concrete implementations for MRGs
of this type, for prime
([72,15]). Then, computing the right side
of (2.2) requires a single multiplication. [15]
provide specific parameter sets and concrete implementations for MRGs
of this type, for prime ![]() near
near ![]() , and
, and ![]() ,
, ![]() ,
and
,
and ![]() .
.
One may be tempted to take ![]() equal to a power of two, say
equal to a power of two, say ![]() ,
because then the ''
mod
,
because then the ''
mod![]() '' operation is much easier: it suffices
to keep the
'' operation is much easier: it suffices
to keep the ![]() least significant bits and mask-out all others.
However, taking a power-of-two modulus is not recommended because it
has several strong disadvantages in terms of the quality of the RNG
([35,40]). In particular, the least significant bits
have very short periodicity and the period length of the
recurrence (2.2) cannot exceed
least significant bits and mask-out all others.
However, taking a power-of-two modulus is not recommended because it
has several strong disadvantages in terms of the quality of the RNG
([35,40]). In particular, the least significant bits
have very short periodicity and the period length of the
recurrence (2.2) cannot exceed
![]() if
if ![]() ,
and
,
and ![]() if
if ![]() and
and ![]() . The maximal period length
achievable with
. The maximal period length
achievable with ![]() and
and ![]() , for example, is more than
, for example, is more than
![]() times smaller than the maximal period length achievable with
times smaller than the maximal period length achievable with
![]() and
and
![]() (a prime number).
(a prime number).
The conditions that make MRG implementations run faster (e.g., only
two nonzero coefficients both close to zero) are generally in conflict
with those required for having a good lattice structure and
statistical robustness. Combined MRGs are one solution to
this problem. Consider ![]() distinct MRGs evolving in parallel, based
on the recurrences
distinct MRGs evolving in parallel, based
on the recurrences
Suppose that the ![]() are pairwise relatively prime, that
are pairwise relatively prime, that ![]() and
and ![]() have no common factor for each
have no common factor for each ![]() , and that each
recurrence (2.6) is purely periodic with period
length
, and that each
recurrence (2.6) is purely periodic with period
length ![]() . Let
. Let
![]() and let
and let ![]() be the least
common multiple of
be the least
common multiple of
![]() . Under these conditions,
the following results have been proved by [61] and
[37]: (a) the sequence (2.8) is exactly
equivalent to the output sequence of a MRG with (composite)
modulus
. Under these conditions,
the following results have been proved by [61] and
[37]: (a) the sequence (2.8) is exactly
equivalent to the output sequence of a MRG with (composite)
modulus ![]() and coefficients
and coefficients ![]() that can be computed explicitly as
explained in [37]; (b) the two sequences
in (2.7) and (2.8) have period
length
that can be computed explicitly as
explained in [37]; (b) the two sequences
in (2.7) and (2.8) have period
length ![]() ; and (c) if both sequences have the same initial state,
then
; and (c) if both sequences have the same initial state,
then
![]() where
where
![]() can
be bounded explicitly by a constant
can
be bounded explicitly by a constant ![]() which is very small
when the
which is very small
when the ![]() are close to each other.
are close to each other.
Thus, these combined MRGs can be viewed as practical ways of
implementing an MRG with a large ![]() and several large nonzero
coefficients. The idea is to cleverly select the components so that:
(1) each one is easy to implement efficiently (e.g., has only two
small nonzero coefficients) and (2) the MRG that corresponds to the
combination has a good lattice structure. If each
and several large nonzero
coefficients. The idea is to cleverly select the components so that:
(1) each one is easy to implement efficiently (e.g., has only two
small nonzero coefficients) and (2) the MRG that corresponds to the
combination has a good lattice structure. If each ![]() is prime and
if each component
is prime and
if each component ![]() has maximal period length
has maximal period length
![]() ,
then each
,
then each ![]() is even and
is even and ![]() cannot exceed
cannot exceed
![]() . Tables of good parameters for combined MRGs of
different sizes that reach this upper bound are given in
[41] and [62], together with C implementations.
. Tables of good parameters for combined MRGs of
different sizes that reach this upper bound are given in
[41] and [62], together with C implementations.
The recurrence (2.2) can be written in matrix form as
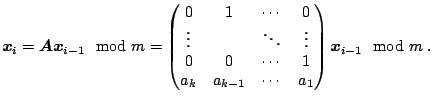 |
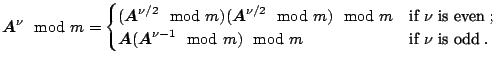 |
These types of recurrences were introduced by [73] to obtain
a large period even when ![]() is a power of two (in which case the
implementation may be faster). They were studied and generalized by
[90,9,11], and
[24]. The basic idea is to add a carry to the
linear recurrence (2.2). The general form of this RNG,
called multiply-with-carry (MWC), can be written as
is a power of two (in which case the
implementation may be faster). They were studied and generalized by
[90,9,11], and
[24]. The basic idea is to add a carry to the
linear recurrence (2.2). The general form of this RNG,
called multiply-with-carry (MWC), can be written as
Define
![]() and let
and let ![]() be the inverse
of
be the inverse
of ![]() in arithmetic modulo
in arithmetic modulo ![]() , assuming for now that
, assuming for now that ![]() .
A major result proved in [90,11], and
[24] is that if the initial states agree, the output
sequence
.
A major result proved in [90,11], and
[24] is that if the initial states agree, the output
sequence
![]() is exactly the same as that produced by
the LCG with modulus
is exactly the same as that produced by
the LCG with modulus ![]() and multiplier
and multiplier ![]() . Therefore, the MWC can
be seen as a clever way of implementing a LCG with very large modulus.
It has been shown by [11] that the value of
. Therefore, the MWC can
be seen as a clever way of implementing a LCG with very large modulus.
It has been shown by [11] that the value of ![]() for
this LCG satisfies
for
this LCG satisfies
![]() for
for ![]() ,
which means that the lattice structure will be bad unless the sum of
squares of coefficients
,
which means that the lattice structure will be bad unless the sum of
squares of coefficients ![]() is large.
is large.
In the original proposals of [73], called
add-with-carry and subtract-with-borrow, one has
![]() for some
for some ![]() and the other
coefficients
and the other
coefficients ![]() are zero, so
are zero, so
![]() for
for ![]() and the
generator has essentially the same structural defect as the additive
lagged-Fibonacci generator. In the version studied by
[11], it was assumed that
and the
generator has essentially the same structural defect as the additive
lagged-Fibonacci generator. In the version studied by
[11], it was assumed that
![]() . Then, the period
length cannot exceed
. Then, the period
length cannot exceed ![]() if
if ![]() is a power of two. A concrete
implementation was given in that paper. [24] pointed out
that the maximal period length of
is a power of two. A concrete
implementation was given in that paper. [24] pointed out
that the maximal period length of
![]() can be achieved by
allowing a more general
can be achieved by
allowing a more general ![]() . They provided specific parameters that
give a maximal period for
. They provided specific parameters that
give a maximal period for ![]() ranging from
ranging from ![]() to
to ![]() and
and
![]() up to approximately
up to approximately
![]() .
.