The term semiparametric refers to models in which there is an
unknown function in addition to an unknown finite dimensional
parameter. For example, the binary response model
![]() is semiparametric if the function
is semiparametric if the function ![]() and the vector
of coefficients
and the vector
of coefficients ![]() are both treated as unknown quantities. This
section describes two semiparametric models of conditional mean
functions that are important in applications. The section also
describes a related class of models that has no unknown
finite-dimensional parameters but, like semiparametric models,
mitigates the disadvantages of fully nonparametric models. Finally,
this section describes a class of transformation models that is
important in estimation of hazard functions among other
applications. Powell (1994) discusses additional semiparametric
models.
are both treated as unknown quantities. This
section describes two semiparametric models of conditional mean
functions that are important in applications. The section also
describes a related class of models that has no unknown
finite-dimensional parameters but, like semiparametric models,
mitigates the disadvantages of fully nonparametric models. Finally,
this section describes a class of transformation models that is
important in estimation of hazard functions among other
applications. Powell (1994) discusses additional semiparametric
models.
In a semiparametric single index model, the conditional mean function has the form
Model (10.1) contains many widely used parametric models
as special cases. For example, if ![]() is the identity function, then
(10.1) is a linear model. If
is the identity function, then
(10.1) is a linear model. If ![]() is the cumulative normal
or logistic distribution function, then (10.1) is a binary
probit or logit model. When
is the cumulative normal
or logistic distribution function, then (10.1) is a binary
probit or logit model. When ![]() is unknown, (10.1)
provides a specification that is more flexible than a parametric model
but retains many of the desirable features of parametric models, as
will now be explained.
is unknown, (10.1)
provides a specification that is more flexible than a parametric model
but retains many of the desirable features of parametric models, as
will now be explained.
One important property of single index models is that they avoid the
curse of dimensionality. This is because the index
![]() aggregates the dimensions of
aggregates the dimensions of ![]() , thereby achieving dimension
reduction. Consequently, the difference between the estimator of
, thereby achieving dimension
reduction. Consequently, the difference between the estimator of ![]() and the true function can be made to converge to zero at the same rate
that would be achieved if
and the true function can be made to converge to zero at the same rate
that would be achieved if
![]() were observable. Moreover,
were observable. Moreover,
![]() can be estimated with the same rate of convergence that is
achieved in a parametric model. Thus, in terms of the rates of
convergence of estimators, a single index model is as accurate as
a parametric model for estimating
can be estimated with the same rate of convergence that is
achieved in a parametric model. Thus, in terms of the rates of
convergence of estimators, a single index model is as accurate as
a parametric model for estimating ![]() and as accurate as
a one-dimensional nonparametric model for estimating
and as accurate as
a one-dimensional nonparametric model for estimating ![]() . This
dimension reduction feature of single index models gives them
a considerable advantage over nonparametric methods in applications
where
. This
dimension reduction feature of single index models gives them
a considerable advantage over nonparametric methods in applications
where ![]() is multidimensional and the single index structure is
plausible.
is multidimensional and the single index structure is
plausible.
A single-index model permits limited extrapolation. Specifically, it
yields predictions of
![]() at values of
at values of ![]() that are not in
the support of
that are not in
the support of ![]() but are in the support of
but are in the support of
![]() . Of course,
there is a price that must be paid for the ability to
extrapolate. A single index model makes assumptions that are stronger
than those of a nonparametric model. These assumptions are testable on
the support of
. Of course,
there is a price that must be paid for the ability to
extrapolate. A single index model makes assumptions that are stronger
than those of a nonparametric model. These assumptions are testable on
the support of ![]() but not outside of it. Thus, extrapolation
(unavoidably) relies on untestable assumptions about the behavior of
but not outside of it. Thus, extrapolation
(unavoidably) relies on untestable assumptions about the behavior of
![]() beyond the support of
beyond the support of ![]() .
.
Before ![]() and
and ![]() can be estimated, restrictions must be imposed
that insure their identification. That is,
can be estimated, restrictions must be imposed
that insure their identification. That is, ![]() and
and ![]() must be
uniquely determined by the population distribution of
(
must be
uniquely determined by the population distribution of
(![]() ,
, ![]() ). Identification of single index models has been
investigated by Ichimura (1993) and, for the special case of binary
response models, Manski (1988). It is clear that
). Identification of single index models has been
investigated by Ichimura (1993) and, for the special case of binary
response models, Manski (1988). It is clear that ![]() is not
identified if
is not
identified if ![]() is a constant function or there is an exact linear
relation among the components of
is a constant function or there is an exact linear
relation among the components of ![]() (perfect multicollinearity). In
addition, (10.1) is observationally equivalent to the
model
(perfect multicollinearity). In
addition, (10.1) is observationally equivalent to the
model
![]() , where
, where
![]() and
and
![]() are arbitrary and
are arbitrary and ![]() is defined by the
relation
is defined by the
relation
![]() for all
for all ![]() in the support
of
in the support
of
![]() . Therefore,
. Therefore, ![]() and
and ![]() are not identified unless
restrictions are imposed that uniquely specify
are not identified unless
restrictions are imposed that uniquely specify ![]() and
and ![]() . The restriction on
. The restriction on ![]() is called location
normalization and can be imposed by requiring
is called location
normalization and can be imposed by requiring ![]() to contain no
constant (intercept) component. The restriction on
to contain no
constant (intercept) component. The restriction on ![]() is called
scale normalization. Scale normalization can be achieved by
setting the
is called
scale normalization. Scale normalization can be achieved by
setting the ![]() coefficient of one component of
coefficient of one component of ![]() equal to
one. A further identification requirement is that
equal to
one. A further identification requirement is that ![]() must include at
least one continuously distributed component whose
must include at
least one continuously distributed component whose ![]() coefficient
is non-zero. Horowitz (1998) gives an example that illustrates the
need for this requirement. Other more technical identification
requirements are discussed by Ichimura (1993) and Manski (1988).
coefficient
is non-zero. Horowitz (1998) gives an example that illustrates the
need for this requirement. Other more technical identification
requirements are discussed by Ichimura (1993) and Manski (1988).
The main estimation challenge in single index models is
estimating ![]() . Given an estimator
. Given an estimator ![]() of
of ![]() ,
, ![]() can be
estimated by carrying out the nonparametric regression of
can be
estimated by carrying out the nonparametric regression of ![]() on
on
![]() (e.g, by using kernel estimation). Several estimators of
(e.g, by using kernel estimation). Several estimators of
![]() are available. Ichimura (1993) describes a nonlinear least
squares estimator. Klein and Spady (1993) describe a semiparametric
maximum likelihood estimator for the case in which
are available. Ichimura (1993) describes a nonlinear least
squares estimator. Klein and Spady (1993) describe a semiparametric
maximum likelihood estimator for the case in which ![]() is
binary. These estimators are difficult to compute because they require
solving complicated nonlinear optimization problems. Powell,
et al. (1989) describe a density-weighted average
derivative estimator (DWADE) that is non-iterative and easily
computed. The DWADE applies when all components of
is
binary. These estimators are difficult to compute because they require
solving complicated nonlinear optimization problems. Powell,
et al. (1989) describe a density-weighted average
derivative estimator (DWADE) that is non-iterative and easily
computed. The DWADE applies when all components of ![]() are continuous
random variables. It is based on the relation
are continuous
random variables. It is based on the relation
The usefulness of single-index models can be illustrated with an
example that is taken from Horowitz and Härdle (1996). The example
consists of estimating a model of product innovation by German
manufacturers of investment goods. The data, assembled in 1989 by the
IFO Institute of Munich, consist of observations on 1100
manufacturers. The dependent variable is ![]() if a manufacturer
realized an innovation during 1989 in a specific product category and
0 otherwise. The independent variables are the number of employees in
the product category (
if a manufacturer
realized an innovation during 1989 in a specific product category and
0 otherwise. The independent variables are the number of employees in
the product category (![]() ), the number of employees in the entire
firm (
), the number of employees in the entire
firm (![]() ), an indicator of the firm's production capacity
utilization (
), an indicator of the firm's production capacity
utilization (![]() ), and a variable
), and a variable ![]() , which is
, which is ![]() if a firm
expected increasing demand in the product category and 0
otherwise. The first three independent variables are standardized so
that they have units of standard deviations from their means. Scale
normalization was achieved by setting
if a firm
expected increasing demand in the product category and 0
otherwise. The first three independent variables are standardized so
that they have units of standard deviations from their means. Scale
normalization was achieved by setting
![]() .
.
Table 10.1 shows the parameter estimates obtained using
a binary probit model and the semiparametric method of Horowitz and
Härdle (1996). Figure 10.2 shows a kernel estimate of
![]() . There are two important differences between the
semiparametric and probit estimates. First, the semiparametric
estimate of
. There are two important differences between the
semiparametric and probit estimates. First, the semiparametric
estimate of
![]() is small and statistically
nonsignificant, whereas the probit estimate is significant at the
is small and statistically
nonsignificant, whereas the probit estimate is significant at the
![]() level and similar in size to
level and similar in size to
![]() . Second, in the
binary probit model,
. Second, in the
binary probit model, ![]() is a cumulative normal distribution function,
so
is a cumulative normal distribution function,
so ![]() is a normal density function. Figure 10.2
reveals, however, that
is a normal density function. Figure 10.2
reveals, however, that ![]() is bimodal. This bimodality suggests
that the data may be a mixture of two populations. An obvious next
step in the analysis of the data would be to search for variables that
characterize these populations. Standard diagnostic techniques for
binary probit models would provide no indication that
is bimodal. This bimodality suggests
that the data may be a mixture of two populations. An obvious next
step in the analysis of the data would be to search for variables that
characterize these populations. Standard diagnostic techniques for
binary probit models would provide no indication that ![]() is
bimodal. Thus, the semiparametric estimate has revealed an important
feature of the data that could not easily be found using standard
parametric methods.
is
bimodal. Thus, the semiparametric estimate has revealed an important
feature of the data that could not easily be found using standard
parametric methods.
| EMPLP | EMPLF | CAP | DEM |
| Semiparametric Model | |||
| 1 | 0.032 | 0.346 | 1.732 |
| (0.023) | (0.078) | (0.509) | |
| Probit Model | |||
| 1 | 0.516 | 0.520 | 1.895 |
| (0.024) | (0.163) | (0.387) | |
In a partially linear model, ![]() is partitioned into two
non-overlapping subvectors,
is partitioned into two
non-overlapping subvectors, ![]() and
and ![]() . The model has the
form
. The model has the
form
An estimator of ![]() can be obtained by observing that
(10.3) implies
can be obtained by observing that
(10.3) implies
Let ![]() have
have ![]() continuously distributed components that are denoted
continuously distributed components that are denoted
![]() . In a nonparametric additive model of the
conditional mean function,
. In a nonparametric additive model of the
conditional mean function,
An estimator of
![]() can be obtained by observing
that (10.5) and (10.6) imply
can be obtained by observing
that (10.5) and (10.6) imply
Linton and Härdle (1996) describe a generalized additive model whose form is
The use of the nonparametric additive specification (10.5)
can be illustrated by estimating the model
![]() EDUC
EDUC![]() , where
, where ![]() and
EXP are defined as in Sect. 10.1, and
EDUC denotes years of education. The data are taken from the
1993 CPS and are for white males with
and
EXP are defined as in Sect. 10.1, and
EDUC denotes years of education. The data are taken from the
1993 CPS and are for white males with ![]() or fewer years of education
who work full time and live in urban areas of the North Central
U.S. The results are shown in Fig 10.3. The unknown
functions
or fewer years of education
who work full time and live in urban areas of the North Central
U.S. The results are shown in Fig 10.3. The unknown
functions ![]() and
and
![]() are estimated by
the method of Linton and Nielsen (1995) and are normalized so that
are estimated by
the method of Linton and Nielsen (1995) and are normalized so that
![]() . The estimates of
. The estimates of
![]() (Fig 10.3a) and
(Fig 10.3a) and
![]() (Fig 10.3b) are nonlinear and differently
shaped. Functions
(Fig 10.3b) are nonlinear and differently
shaped. Functions ![]() and
and
![]() with
different shapes cannot be produced by a single index model, and
a lengthy specification search might be needed to find a parametric
model that produces the shapes shown in Fig 10.3. Some of
the fluctuations of the estimates of
with
different shapes cannot be produced by a single index model, and
a lengthy specification search might be needed to find a parametric
model that produces the shapes shown in Fig 10.3. Some of
the fluctuations of the estimates of ![]() and
and
![]() may be artifacts of random sampling error rather
than features of
may be artifacts of random sampling error rather
than features of
![]() EDUC
EDUC![]() . However,
a more elaborate analysis that takes account of the effects of random
sampling error rejects the hypothesis that either function is linear.
. However,
a more elaborate analysis that takes account of the effects of random
sampling error rejects the hypothesis that either function is linear.
A transformation model has the form
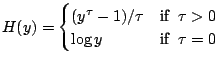 |
Another possibility is to assume that ![]() is unknown but that the
distribution of
is unknown but that the
distribution of ![]() is known. Cheng, Wei, and Ying (1995, 1997) have
developed estimators for this version of (10.9). Consider,
first, the problem of estimating
is known. Cheng, Wei, and Ying (1995, 1997) have
developed estimators for this version of (10.9). Consider,
first, the problem of estimating ![]() . Let
. Let ![]() denote the (known)
cumulative distribution function (CDF) of
denote the (known)
cumulative distribution function (CDF) of ![]() . Let
. Let
![]() and
and
![]()
![]() be two distinct, independent observations of
be two distinct, independent observations of
![]() . Then it follows from (10.9) that
. Then it follows from (10.9) that
![$\displaystyle G(z)=\int\limits_{-\infty }^\infty \left[1-F(u+z)\right]{\text{d}} F(u) \;.$](img5935.gif) |
The problem of estimating the transformation function is addressed
by Cheng, Wei, and Ying (1997). Equation (10.11) implies that for
any real ![]() and vector
and vector ![]() that is conformable with
that is conformable with ![]() ,
,
![]() . Cheng, Wei, and
Ying (1997) propose estimating
. Cheng, Wei, and
Ying (1997) propose estimating ![]() by the solution to the
sample analog of this equation. That is, the estimator
by the solution to the
sample analog of this equation. That is, the estimator ![]() solves
solves
![$\displaystyle n^{-1}\sum\limits_{i=1}^n \left\{ I\left(Y_i \le y\right)-F\left[H_n (y)-{b}'_n X_i \right]\right\} =0\;,$](img5946.gif) |
A third possibility is to assume that ![]() and
and ![]() are both nonparametric
in (10.9). In this case, certain normalizations are needed
to make identification of (10.9) possible. First, observe
that (10.9) continues to hold if
are both nonparametric
in (10.9). In this case, certain normalizations are needed
to make identification of (10.9) possible. First, observe
that (10.9) continues to hold if ![]() is replaced by
is replaced by ![]() ,
,
![]() is replaced by
is replaced by ![]() , and
, and ![]() is replaced by
is replaced by ![]() for any
positive constant
for any
positive constant ![]() . Therefore, a scale normalization is needed to
make identification possible. This will be done here by setting
. Therefore, a scale normalization is needed to
make identification possible. This will be done here by setting
![]() , where
, where ![]() is the first component
of
is the first component
of ![]() . Observe, also, that when
. Observe, also, that when ![]() and
and ![]() are nonparametric,
(10.9) is a semiparametric single-index model. Therefore,
identification of
are nonparametric,
(10.9) is a semiparametric single-index model. Therefore,
identification of ![]() requires
requires ![]() to have at least one component
whose distribution conditional on the others is continuous and whose
to have at least one component
whose distribution conditional on the others is continuous and whose
![]() coefficient is non-zero. Assume without loss of generality
that the components of
coefficient is non-zero. Assume without loss of generality
that the components of ![]() are ordered so that the first satisfies
this condition.
are ordered so that the first satisfies
this condition.
It can also be seen that (10.9) is unchanged if ![]() is
replaced by
is
replaced by ![]() and
and ![]() is replaced by
is replaced by ![]() for any positive or
negative constant
for any positive or
negative constant ![]() . Therefore, a location normalization is also
needed to achieve identification when and
. Therefore, a location normalization is also
needed to achieve identification when and ![]() are
nonparametric. Location normalization will be carried out here by
assuming that
are
nonparametric. Location normalization will be carried out here by
assuming that ![]() for some finite
for some finite ![]() With this location
normalization, there is no centering assumption on
With this location
normalization, there is no centering assumption on ![]() and no
intercept term in
and no
intercept term in ![]() .
.
Now consider the problem of estimating ![]() ,
, ![]() , and
, and ![]() . Because
(10.9) is a single-index model in this case,
. Because
(10.9) is a single-index model in this case, ![]() can
be estimated using the methods described in
Sect. 10.2.1. Let
can
be estimated using the methods described in
Sect. 10.2.1. Let ![]() denote the estimator
of
denote the estimator
of ![]() . One approach to estimating
. One approach to estimating ![]() and
and ![]() is given by Horowitz
(1996). To describe this approach, define
is given by Horowitz
(1996). To describe this approach, define
![]() . Let
. Let
![]() denote the CDF of
denote the CDF of ![]() conditional on
conditional on ![]() . Set
. Set
![]() and
and
![]() . Then it follows from (10.9) that
. Then it follows from (10.9) that
![]() and that
and that
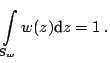 |
Other estimators of ![]() when and
when and ![]() are both nonparametric have been
proposed by Ye and Duan (1997) and Chen (2002). Chen uses a rank-based
approach that is in some ways simpler than that of Horowitz (1996) and
may have better finite-sample performance. To describe this approach,
define
are both nonparametric have been
proposed by Ye and Duan (1997) and Chen (2002). Chen uses a rank-based
approach that is in some ways simpler than that of Horowitz (1996) and
may have better finite-sample performance. To describe this approach,
define
![]() and
and
![]() . Let
. Let ![]() . Then
. Then
![]() whenever
whenever
![]() . This suggests that if
. This suggests that if ![]() were known, then
were known, then ![]() could be estimated by
could be estimated by
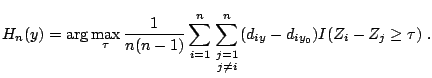 |
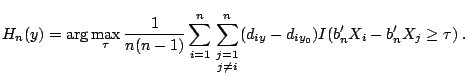 |
![\includegraphics[width=9cm]{text/3-10/abb/32}](img5898.gif)
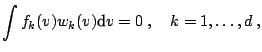
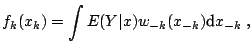
![\includegraphics[width=9.3cm]{text/3-10/abb/33}](img5921.gif)
![$\displaystyle \sum\limits_{i=1}^n \sum\limits_{j=1}^n \left\{w\left({b}'X_{ij} ...
...} \left[I\left(Y_i >Y_j \right)-G\left(-{b}'X_{ij} \right)\right]\right\} =0\;.$](img5939.gif)
![$\displaystyle H(y)=-\int\limits_{y_0 }^y \left[G_y (v\vert z)/G_z (v\vert z)\right]{\text{d}} v$](img5964.gif)
![$\displaystyle H(y)=-\int\limits_{y_0 }^y \int\limits_{S_w } w(z)\left[G_y (v\vert z)/G_z (v\vert z)\right]{\text{d}} z\,{\text{d}} v\;.$](img5971.gif)
![$\displaystyle H_n (y)=-\int\limits_{y_0 }^y \int\limits_{S_w } w(z)\left[G_{ny} (v\vert z)/G_{nz} (v\vert z)\right]{\text{d}} z\,{\text{d}} v\;.$](img5977.gif)