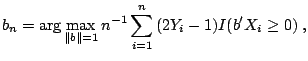The general binary response model has the form
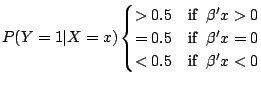 |
The maximum score estimator has a slow rate of convergence and
a complicated asymptotic distribution because it is obtained by
maximizing a step function. Horowitz (1992) proposed replacing the
indicator function in (10.21) by a smooth function. The
resulting estimator of ![]() is called the smoothed maximum
score estimator.
Specifically, let
is called the smoothed maximum
score estimator.
Specifically, let ![]() be a smooth function, possibly
but not necessarily a distribution function, that satisfies
be a smooth function, possibly
but not necessarily a distribution function, that satisfies
![]() and
and
![]() . Let
. Let
![]() be a sequence
of strictly positive constants (bandwidths) that satisfies
be a sequence
of strictly positive constants (bandwidths) that satisfies ![]() as
as
![]() . The smoothed maximum score estimator,
. The smoothed maximum score estimator, ![]() , is
, is
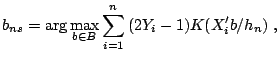 |
Horowitz (1993c) used the smoothed
maximum score method to estimate the parameters of a model of the
choice between automobile and transit for work trips in the
Washington, D.C., area. The explanatory variables are defined in
Table 10.2. Scale normalization is achieved by setting
the coefficient of DCOST equal to ![]() . The data consist of 842
observations sampled randomly from the Washington, D.C., area
transportation study. Each record contains information about a single
trip to work, including the chosen mode (automobile or transit) and
the values of the explanatory variables. Column 2 of
Table 10.2 shows the smoothed maximum score estimates of
the model's parameters. Column 3 shows the half-widths of nominal
. The data consist of 842
observations sampled randomly from the Washington, D.C., area
transportation study. Each record contains information about a single
trip to work, including the chosen mode (automobile or transit) and
the values of the explanatory variables. Column 2 of
Table 10.2 shows the smoothed maximum score estimates of
the model's parameters. Column 3 shows the half-widths of nominal
![]() symmetrical confidence intervals based on the asymptotic
normal approximation (half width equals
symmetrical confidence intervals based on the asymptotic
normal approximation (half width equals ![]() times the standard
error of the estimate). Column 4 shows half-widths obtained from the
bootstrap. The bootstrap confidence intervals are
times the standard
error of the estimate). Column 4 shows half-widths obtained from the
bootstrap. The bootstrap confidence intervals are ![]() -
-![]() times
wider than the intervals based on the asymptotic normal
approximation. The bootstrap confidence interval for the coefficient
of DOVTT contains 0, but the confidence interval based on the
asymptotic normal approximation does not. Therefore, the hypothesis
that the coefficient of DOVTT is zero is not rejected at the
times
wider than the intervals based on the asymptotic normal
approximation. The bootstrap confidence interval for the coefficient
of DOVTT contains 0, but the confidence interval based on the
asymptotic normal approximation does not. Therefore, the hypothesis
that the coefficient of DOVTT is zero is not rejected at the ![]() level based on the bootstrap but is rejected based on the asymptotic
normal approximation.
level based on the bootstrap but is rejected based on the asymptotic
normal approximation.
| Half-Width of Nominal |
|||
| Conf. Interval Based on | |||
| Estimated | Asymp. Normal | ||
| Variable
|
Coefficient | Approximation | Bootstrap |
| INTRCPT | -1.5761 | 0.2812 | 0.7664 |
| AUTOS | 2.2418 | 0.2989 | 0.7488 |
| DOVTT | 0.0269 | 0.0124 | 0.0310 |
| DIVTT | 0.0143 | 0.0033 | 0.0087 |
| DCOST | 1.0
|
||
Acknowledgements. Research supported in part by NSF Grant SES-9910925.