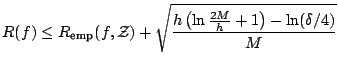The main objective of statistical learning is to find a description of an unknown dependency between measurements of objects and certain properties of these objects. The measurements, to be also called ''input variables'', are assumed to be observable in all objects of interest. On the contrary, the objects' properties, or ''output variables'', are in general available only for a small subset of objects known as examples. The purpose of estimating the dependency between the input and output variables is to be able to determine the values of output variables for any object of interest.
The problem of estimating an unknown dependency occurs in various practical applications. For example, the input variables can be the prices for a set of stocks and the output variable the direction of change in a certain stock price. As another example, the input can be some medical parameters and the output the probability of a patient having a certain disease. An essential feature of statistical learning is that the information is assumed to be contained in a limited set of examples (the sample), and the estimated dependency should be as accurate as possible for all objects of interest.
To proceed with a formal description of main properties of statistical
learning, let us fix some notation. Let
![]() denote the space of input
variables representing the objects, and let
denote the space of input
variables representing the objects, and let
![]() be the space of
output variables. The structure of
be the space of
output variables. The structure of
![]() defines the learning task.
For example, if
defines the learning task.
For example, if
![]() , the learning amounts to a regression problem,
for
, the learning amounts to a regression problem,
for
![]() , the task is a classification problem with three
classes, etc.
, the task is a classification problem with three
classes, etc.
Let
![]() be a given sample.
We assume that there exists some unknown but fixed probability
distribution
be a given sample.
We assume that there exists some unknown but fixed probability
distribution ![]() over the space
over the space
![]() generating our data;
that is,
generating our data;
that is,
![]() are drawn identically and independently
from
are drawn identically and independently
from ![]() .
.
The dependency to be estimated takes the form of a function
![]() . To decide which of many possible functions best
describes the dependency observed in the training sample, we introduce
the concept of a loss function:
. To decide which of many possible functions best
describes the dependency observed in the training sample, we introduce
the concept of a loss function:
Notice that, if we would know the joint distribution ![]() , the
learning problem can be easily solved. For example, in the
classification case one could calculate the conditional probability
, the
learning problem can be easily solved. For example, in the
classification case one could calculate the conditional probability
![]() and compute the so called ''Bayes-optimal solution'':
and compute the so called ''Bayes-optimal solution'':
The most commonly used induction principle is the one of minimizing the empirical risk
![\includegraphics[width=6cm]{text/3-15/fct_no_emp_error.eps}](img6838.gif)
|
The other two phenomena arising in relation with the minimization of
the empirical risk (15.4) are over- and
under-fittung. An overly complex function ![]() might describe the
training data well but does not generalize to unseen examples. The
converse could also happen. Assume the function class
might describe the
training data well but does not generalize to unseen examples. The
converse could also happen. Assume the function class
![]() we can
choose from is very small, e.g. it contains only a single, fixed
function. Then our learning machine would trivially be consistent,
since
we can
choose from is very small, e.g. it contains only a single, fixed
function. Then our learning machine would trivially be consistent,
since
![]() const for all
const for all
![]() . But if this single
. But if this single
![]() is not by accident the rule that generates our data, the
decisions are unrelated to the concept generating our data. This
phenomenon is called under-fitting
(cf. Fig. 15.2). Apparently we need some way of
controlling how large the class of functions
is not by accident the rule that generates our data, the
decisions are unrelated to the concept generating our data. This
phenomenon is called under-fitting
(cf. Fig. 15.2). Apparently we need some way of
controlling how large the class of functions
![]() is, such that we
avoid over- and under-fitting and obtain solutions that generalize
well (i.e. with reasonable complexity). The questions of consistency,
over- and under-fitting are closely related and will lead us to
a concept known as regularization (e.g. [68,43]) and to
the principle of structural risk minimization ([71]).
is, such that we
avoid over- and under-fitting and obtain solutions that generalize
well (i.e. with reasonable complexity). The questions of consistency,
over- and under-fitting are closely related and will lead us to
a concept known as regularization (e.g. [68,43]) and to
the principle of structural risk minimization ([71]).
![\includegraphics[width=6cm]{text/3-15/overfitting.eps}](img6840.gif)
|
In the previous paragraphs we have shown that for successful learning it is not enough to find a function with minimal empirical risk. If we are interested in a good estimation of the true risk on all possible datapoints, we need to introduce a complexity control and choose our solution by minimizing the following objective function:
There are several possibilities to choose ![]() and
and ![]() in
order to derive a consistent inductive principle. In the following
sections we will describe the choice inspired by the work of Vapnik.
Other possible choices are for example
Akaike information criterion ([2]) or Mallows Cp
([39]), used in classical statistics, as well as
spline-regularization ([74]),
wavelet regularization ([21]),
CART ([14]) and many other modern approaches.
A general foundation for regularization in model selection is given in
([4]). [7] investigate regularization in
the context of SVM.
in
order to derive a consistent inductive principle. In the following
sections we will describe the choice inspired by the work of Vapnik.
Other possible choices are for example
Akaike information criterion ([2]) or Mallows Cp
([39]), used in classical statistics, as well as
spline-regularization ([74]),
wavelet regularization ([21]),
CART ([14]) and many other modern approaches.
A general foundation for regularization in model selection is given in
([4]). [7] investigate regularization in
the context of SVM.
Let us define more closely what consistency means and how it can be
characterized. Let us denote by ![]() the function
the function
![]() that
minimizes (15.4) for a given training
sample
that
minimizes (15.4) for a given training
sample
![]() of size
of size ![]() . The notion of consistency implies that, as
. The notion of consistency implies that, as
![]() ,
,
![]() in
probability. We have already seen in a previous example that such
convergence may not be the case in general, the reason being that
in
probability. We have already seen in a previous example that such
convergence may not be the case in general, the reason being that
![]() now depends on the sample
now depends on the sample
![]() . One can show that a necessary
and sufficient condition for consistency is uniform
convergence, over all functions in
. One can show that a necessary
and sufficient condition for consistency is uniform
convergence, over all functions in
![]() , of the difference between the
expected and the empirical risk to zero. This insight is summarized
in the following theorem:
, of the difference between the
expected and the empirical risk to zero. This insight is summarized
in the following theorem:
One-sided uniform convergence in probability, i.e.
Consequently, the question arises how one can choose function
classes that satisfy Theorem 1 in
practice? It will turn out that this is possible and it
crucially depends on the question how complex the functions in
the class
![]() are, a question we have already seen to be
equally important when talking about over- and
under-fitting. But what does complexity mean and how can one
control the size of a function class?
are, a question we have already seen to be
equally important when talking about over- and
under-fitting. But what does complexity mean and how can one
control the size of a function class?
The complexity of a function class can be measured by the number of different possible combinations of outcome assignments when choosing functions from this class. This quantity is usually difficult to obtain theoretically for useful classes of functions. Popular approximations of this measure are covering numbers ([61]), annealed entropy and fat-shattering dimension ([6]), VC-entropy and VC dimension ([71]), or Rademacher and Gaussian complexity ([7]). We will not go into detail about these quantities here.
A specific way of controlling the complexity
of a function class is given by the VC-theory
and the structural risk minimization (SRM)
principle ([71]). Here the concept of complexity is captured
by the VC-dimension ![]() of the function class
of the function class
![]() . Roughly speaking,
the VC-dimension measures how many (training) points can be shattered
(i.e. separated for all possible labellings) using functions of the
class. This quantity can be used to bound the probability that the
expected error deviates much from the empirical error for any function
from the class, i.e. VC-style bounds usually take the form
. Roughly speaking,
the VC-dimension measures how many (training) points can be shattered
(i.e. separated for all possible labellings) using functions of the
class. This quantity can be used to bound the probability that the
expected error deviates much from the empirical error for any function
from the class, i.e. VC-style bounds usually take the form
![\includegraphics[width=6cm]{text/3-15/illurisknew.eps}](img6854.gif)
|
One of the most famous learning bounds is due to Vapnik and Chervonenkis:
Let ![]() denote the VC-dimension of the function class
denote the VC-dimension of the function class
![]() and let
and let
![]() be defined by (15.4) using the
be defined by (15.4) using the
![]() -loss. For all
-loss. For all ![]() and
and
![]() the inequality bounding
the risk
the inequality bounding
the risk
As a consequence of Theorem 2 the so called
''Structural Risk Minimization principle'' (SRM) is suggested
(i.e. [17,71]). According to this principle a nested
family of function classes
![]() with
non-decreasing VC-dimension
with
non-decreasing VC-dimension
![]() , is constructed.
After the solutions
, is constructed.
After the solutions
![]() of the empirical risk
minimization (15.4) in the function classes
of the empirical risk
minimization (15.4) in the function classes
![]() have been found, the SRM principle chooses the function class
have been found, the SRM principle chooses the function class
![]() (and the function
(and the function ![]() ) such that an upper bound on the
generalization error like (15.9) is minimized.
) such that an upper bound on the
generalization error like (15.9) is minimized.
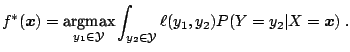
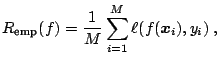
![$\displaystyle \lim_{M\rightarrow\infty} {\mathbb{P}}\left[\sup_{f\in{\mathcal{F...
...th{R}(\kern.5pt f)-{R_{\text{emp}}}(\kern.5pt f)\right)> \epsilon\right] = 0\;,$](img6844.gif)
![$\displaystyle \left[\sup_{f\in{\mathcal{F}}}\left(\ensuremath{R}(\kern.5pt f)-{...
...pt f,{\mathcal{Z}})\right)>\epsilon\right]\leq H({\mathcal{F}}, M, \epsilon)\;,$](img6845.gif)