Having summarized the prerequisites from statistical learning theory, we now give an example of a particular learning machine that builds upon these insights. The Support Vector Machine algorithm (SVM) developed by Vapnik and others (e.g. [12,17,71,18,44,59], and numerous others) is one of the most successful classification techniques over the last decade, especially after being combined with the kernel idea which we shall discuss in Sect. 15.4.
We are now going to discuss how one could possibly control the size of a function class and how to select the empirical risk minimizer in this class.
In the following, let us assume that we are dealing with a two class
classification problem (i.e.
![]() ) in a real-valued vector
space, e.g.
) in a real-valued vector
space, e.g.
![]() . Further, we assume that the distribution of
these two classes is such that they are linearly separable, i.e. one
can find a linear function of the inputs
. Further, we assume that the distribution of
these two classes is such that they are linearly separable, i.e. one
can find a linear function of the inputs
![]() such that
such that
![]() whenever the label
whenever the label ![]() and
and
![]() otherwise. This can be
conveniently expressed by a hyperplane in the space
otherwise. This can be
conveniently expressed by a hyperplane in the space
![]() , i.e. we are
looking for a function
, i.e. we are
looking for a function ![]() of the form
of the form
To apply the SRM principle in practice the VC-dimension of the class of hyperplanes must be finite, and a nested structure of function classes must be defined. To this end we define the function classes
The crucial ingredient in making the function classes
![]() nested is to define a unique representation for each hyperplane. We
introduce the concept of canonical hyperplanes and the notion of
margins. If the data are separable by
nested is to define a unique representation for each hyperplane. We
introduce the concept of canonical hyperplanes and the notion of
margins. If the data are separable by
![]() then they are also
separable by any (positive) multiple of
then they are also
separable by any (positive) multiple of
![]() and hence there exist
an infinite number of representations for the same separating
hyperplane. In particular, all function classes
and hence there exist
an infinite number of representations for the same separating
hyperplane. In particular, all function classes
![]() would
have the same VC-dimension as they would contain the same functions in
different representations.
would
have the same VC-dimension as they would contain the same functions in
different representations.
![\includegraphics[width=0.4\textwidth]{text/3-15/illumargin.eps}](img6880.gif)
|
A canonical hyperplane with respect to an ![]() -sample
-sample
![]() is defined
as a function
is defined
as a function
The margin
is defined to be the minimal Euclidean distance between any training
example
![]() and the separating hyperplane. Intuitively, the margin
measures how good the separation between the two classes by
a hyperplane is. If this hyperplane is in the canonical form, the
margin can be measured by the length of the weight vector
and the separating hyperplane. Intuitively, the margin
measures how good the separation between the two classes by
a hyperplane is. If this hyperplane is in the canonical form, the
margin can be measured by the length of the weight vector
![]() .
Consider two support vectors
.
Consider two support vectors
![]() and
and
![]() from different classes.
The margin is given by the projection of the distance between these
two points on the direction perpendicular to the hyperplane. This
distance can be computed as (e.g. [71])
from different classes.
The margin is given by the projection of the distance between these
two points on the direction perpendicular to the hyperplane. This
distance can be computed as (e.g. [71])
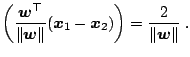 |
More generally, it was shown (e.g. [71]) that if the
hyperplane is constructed under the constraint
![]() then the VC-dimension of the class
then the VC-dimension of the class
![]() is bounded by
is bounded by
![\includegraphics[height=0.4\textwidth]{text/3-15/margin1.eps}](img6890.gif)
![\includegraphics[height=0.4\textwidth]{text/3-15/margin2.eps}](img6891.gif)
|
A particularly important insight is that the complexity only indirectly depends on the dimensionality of the data. This is very much in contrast to e.g. density estimation, where the problems become more difficult as the dimensionality of the data increases. For SVM classification, if we can achieve a large margin the problem remains simple.