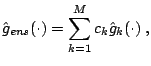Ensemble methods aim at improving the predictive performance of a given statistical learning or model fitting technique. The general principle of ensemble methods is to construct a linear combination of some model fitting method, instead of using a single fit of the method.
More precisely, consider for simplicity the framework of function estimation. We are interested in estimating a real-valued function
Ensemble methods became popular as a relatively simple device to improve the predictive performance of a base procedure. There are different reasons for this: the bagging procedure turns out to be a variance reduction scheme, at least for some base procedures. On the other hand, boosting methods are primarily reducing the (model) bias of the base procedure. This already indicates that bagging and boosting are very different ensemble methods. We will argue in Sects. 16.3.1 and 16.3.6 that boosting may be even viewed as a non-ensemble method which has tremendous advantages over ensemble (or multiple prediction) methods in terms of interpretation.
Random forests ([13]) is a very different ensemble method than bagging or boosting. The earliest random forest proposal is from Amit and Geman ([2]). From the perspective of prediction, random forests is about as good as boosting, and often better than bagging. For further details about random forests we refer to ([13]).
Some rather different exposition about bagging and boosting which describes these methods in the much broader context of many other modern statistical methods can be found in ([36]).