Bagging ([9]), a sobriquet for bootstrap
aggregating, is an ensemble method for improving
unstable estimation or classification schemes. Breiman ([9])
motivated bagging as a variance reduction technique for a given base
procedure, such as decision trees or methods that do variable
selection and fitting in a linear model. It has attracted much
attention, probably due to its implementational simplicity and the
popularity of the bootstrap methodology. At the time of its invention,
only heuristic arguments were presented why bagging would work. Later,
it has been shown in ([18]) that bagging is a smoothing operation
which turns out to be advantageous when aiming to improve the
predictive performance of regression or classification trees. In case
of decision trees, the theory in ([18]) confirms Breiman's
intuition that bagging is a variance reduction technique, reducing
also the mean squared error (MSE). The same also holds for subagging
(subsample aggregating), defined in
Sect. 16.2.3, which is a computationally cheaper version
than bagging. However, for other (even ''complex'') base procedures,
the variance and MSE reduction effect of bagging is not necessarily
true; this has also been shown in ([20]) for the simple case
where the estimator is a ![]() -statistics.
-statistics.
Consider the regression or classification setting. The data is given
as in Sect. 16.1: we have pairs
![]() ,
where
,
where
![]() denotes the
denotes the ![]() -dimensional predictor variable
and the response
-dimensional predictor variable
and the response
![]() (regression) or
(regression) or
![]() (classification with
(classification with ![]() classes). The target function of
interest is usually
classes). The target function of
interest is usually
![]() for regression or the multivariate
function
for regression or the multivariate
function
![]() for classification. The
function estimator, which is the result from a given base procedure,
is
for classification. The
function estimator, which is the result from a given base procedure,
is
Bagging is defined as follows.
Step 1. Construct a bootstrap sample
![]() by randomly drawing
by randomly drawing ![]() times with replacement from
the data
times with replacement from
the data
![]() .
.
Step 2. Compute the bootstrapped estimator
![]() by the plug-in principle:
by the plug-in principle:
![]() .
.
Step 3. Repeat steps 1 and 2 ![]() times, where
times, where ![]() is
often chosen as
is
often chosen as ![]() or
or ![]() , yielding
, yielding
![]() . The bagged estimator is
. The bagged estimator is
![]() .
.
In theory, the bagged estimator is
This is exactly Breiman's ([9]) definition for bagging
regression estimators. For classification, we propose to average the
bootstrapped probabilities
![]() yielding an estimator for
yielding an estimator for
![]() , whereas
Breiman ([9]) proposed to vote among classifiers for
constructing the bagged classifier.
, whereas
Breiman ([9]) proposed to vote among classifiers for
constructing the bagged classifier.
The empirical fact that bagging improves the predictive performance of
regression and classification trees is nowadays widely documented
([9], [10], [18],
[26], [20,37]). To give an idea about the
gain in performance, we cite some of the results of Breiman's
pioneering paper ([9]): for ![]() classification problems,
bagging a classification tree improved over a single classification
tree (in terms of cross-validated misclassification error) by
classification problems,
bagging a classification tree improved over a single classification
tree (in terms of cross-validated misclassification error) by
A trivial equality indicates the somewhat unusual approach of using the bootstrap methodology:
Instability often occurs when hard decisions with indicator functions are involved as in regression or classification trees. One of the main underlying ideas why bagging works can be demonstrated by a simple example.
Consider the estimator
We can compute the first two asymptotic moments in the unstable region
with ![]() . Numerical evaluations of these first two moments and
the mean squared error (MSE) are given in Fig. 16.2. We see
that in the approximate range where
. Numerical evaluations of these first two moments and
the mean squared error (MSE) are given in Fig. 16.2. We see
that in the approximate range where
![]() , bagging
improves the asymptotic MSE. The biggest gain, by a factor
, bagging
improves the asymptotic MSE. The biggest gain, by a factor ![]() , is at
the most unstable point
, is at
the most unstable point
![]() , corresponding to
, corresponding to
![]() . The squared bias with bagging has only a negligible effect on
the MSE (note the different scales in Fig. 16.2). Note that we
always give an a-priori advantage to the original estimator which is
asymptotically unbiased for the target as defined.
. The squared bias with bagging has only a negligible effect on
the MSE (note the different scales in Fig. 16.2). Note that we
always give an a-priori advantage to the original estimator which is
asymptotically unbiased for the target as defined.
In ([18]), this kind of analysis has been given for more general
estimators than
![]() in (16.3) and also for
estimation in linear models after testing. Hard decision indicator
functions are involved there as well and bagging reduces variance due
to its smoothing effect. The key to derive this property is always the
fact that the bootstrap is asymptotically consistent as
in (16.8).
in (16.3) and also for
estimation in linear models after testing. Hard decision indicator
functions are involved there as well and bagging reduces variance due
to its smoothing effect. The key to derive this property is always the
fact that the bootstrap is asymptotically consistent as
in (16.8).
![\includegraphics[width=6.5cm,clip]{text/3-16/abb/indic-est.eps}](img7162.gif)
|
![\includegraphics[height=6.5cm,clip]{text/3-16/abb/indic-mse.eps}](img7166.gif)
|
We address here the effect of bagging in the case of decision trees which are most often used in practice in conjunction with bagging. Decision trees consist of piecewise constant fitted functions whose supports (for the piecewise constants) are given by indicator functions similar to (16.3). Hence we expect bagging to bring a significant variance reduction as in the toy example above.
For simplicity of exposition, we consider first a one-dimensional predictor space and a so-called regression stump which is a regression tree with one split and two terminal nodes. The stump estimator (or algorithm) is then defined as the decision tree,
![$\displaystyle (\hat{\beta}_\ell,\hat{\beta}_u,\hat{d}) = \mathop{\text{arg}}\ma...
...}}_{[X_i < d]} - \beta_u {\large {\text{\textbf{1}}}}_{[X_i \ge d]}\right)^2\;.$](img7168.gif) |
The main mathematical difference of the stump in (16.9) to
the toy estimator in (16.3) is the behavior of ![]() in
comparison to the behavior of
in
comparison to the behavior of
![]() (and not the constants
(and not the constants
![]() and
and
![]() involved in the stump). It
is shown in ([18]) that
involved in the stump). It
is shown in ([18]) that ![]() has convergence rate
has convergence rate ![]() (in case of a smooth regression function) and a limiting distribution
which is non-Gaussian. This also explains that the bootstrap is not
consistent, but consistency as in (16.8) turned out to be
crucial in our analysis above. Bagging is still doing some kind of
smoothing, but it is not known how this behaves
quantitatively. However, a computationally attractive version of
bagging, which has been found to perform often as good as bagging,
turns out to be more tractable from a theoretical point of view.
(in case of a smooth regression function) and a limiting distribution
which is non-Gaussian. This also explains that the bootstrap is not
consistent, but consistency as in (16.8) turned out to be
crucial in our analysis above. Bagging is still doing some kind of
smoothing, but it is not known how this behaves
quantitatively. However, a computationally attractive version of
bagging, which has been found to perform often as good as bagging,
turns out to be more tractable from a theoretical point of view.
Subagging is a sobriquet for subsample
aggregating where subsampling is used instead of the
bootstrap for the aggregation. An estimator
![]() is aggregated as follows:
is aggregated as follows:
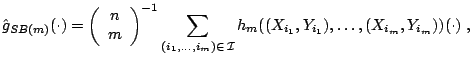 |
Step 1. For
![]() (e.g.
(e.g. ![]() or
or ![]() ) do:
) do:
Step 2. Average the subsampled estimators to approximate
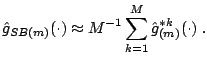 |
As indicated in the notation, subagging depends on the
subsample size ![]() which is a tuning parameter (in contrast to
which is a tuning parameter (in contrast to ![]() ).
).
An interesting case is half subagging with ![]() . More
generally, we could also use
. More
generally, we could also use ![]() with
with ![]() (i.e.
(i.e. ![]() a fraction of
a fraction of ![]() ) and we will argue why the usual choice
) and we will argue why the usual choice ![]() in subsampling for distribution estimation ([44]) is a bad
choice. Half subagging with
in subsampling for distribution estimation ([44]) is a bad
choice. Half subagging with ![]() has been studied also
in ([20]): in case where
has been studied also
in ([20]): in case where ![]() is a
is a ![]() -statistic, half
subagging is exactly equivalent to bagging, and subagging yields very
similar empirical results to bagging when the estimator
-statistic, half
subagging is exactly equivalent to bagging, and subagging yields very
similar empirical results to bagging when the estimator
![]() is a decision tree. Thus, if we don't want to
optimize over the tuning parameter
is a decision tree. Thus, if we don't want to
optimize over the tuning parameter ![]() , a good choice in practice is
very often
, a good choice in practice is
very often ![]() . Consequently, half subagging typically saves
more than half of the computing time because the computational order
of an estimator
. Consequently, half subagging typically saves
more than half of the computing time because the computational order
of an estimator
![]() is usually at least linear
in
is usually at least linear
in ![]() .
.
We describe here in a non-technical way the main mathematical result from ([18]) about subagging regression trees.
The underlying assumptions for some mathematical theory are as follows. The data generating regression model is
It is then shown in ([18]) that for
![]() ,
,
![$\displaystyle \limsup_{n \to \infty} \frac{\mathbb{E}\left[(\hat{g}_{SB(m)}(x) - g(x))^2\right]}{\mathbb{E}\left[(\hat{g}_{n}(x) - g(x))^2\right]} < 1\;,$](img7191.gif) |
For subagging with small order ![]() , such a result is no longer
true: the reason is that small order subagging will then be dominated
by a large bias (while variance reduction is even better than for
fraction subagging with
, such a result is no longer
true: the reason is that small order subagging will then be dominated
by a large bias (while variance reduction is even better than for
fraction subagging with
![]() ).
).
Similarly as for the toy example in Sect. 16.2.2, subagging smoothes the hard decisions in a regression tree resulting in reduced variance and MSE.
As discussed in Sects. 16.2.2 and 16.2.3, (su-)bagging smoothes out indicator functions which are inherent in some base procedures such as decision trees. For base procedures which are ''smoother'', e.g. which do not involve hard decision indicators, the smoothing effect of bagging is expected to cause only small effects.
For example, in ([20]) it is proved that the effect of bagging on
the MSE is only in the second order term if the base procedure is
a ![]() -statistic. Similarly, citing ([23]): ''
-statistic. Similarly, citing ([23]): ''![]() when
bagging is applied to relatively conventional statistical problems, it
cannot reliably be expected to improve performance''. On the other
hand, we routinely use nowadays ''non-conventional'' methods:
a simple example is variable selection and fitting in a linear model
where bagging has been demonstrated to improve predictive performance
([9]).
when
bagging is applied to relatively conventional statistical problems, it
cannot reliably be expected to improve performance''. On the other
hand, we routinely use nowadays ''non-conventional'' methods:
a simple example is variable selection and fitting in a linear model
where bagging has been demonstrated to improve predictive performance
([9]).
In ([26]), the performance of bagging has been studied for MARS, projection pursuit regression and regression tree base procedures: most improvements of bagging are reported for decision trees. In ([18]), it is shown that bagging the basis function in MARS essentially doesn't change the asymptotic MSE. In ([15]) it is empirically demonstrated in greater detail that for finite samples, bagging MARS is by far less effective - and sometimes very destructive - than bagging decision trees.
(Su-)bagging may also have a positive effect due to averaging over different selected predictor variables; this is an additional effect besides smoothing out indicator functions. In case of MARS, we could also envision that such an averaging over different selected predictor variables would have a positive effect: in the empirical analysis in ([15]), this has been found to be only true when using a robust version of aggregation, see below.
Bragging stands for bootstrap robust
aggregating ([15]): it uses the sample
median over the ![]() bootstrap estimates
bootstrap estimates
![]() ,
instead of the sample mean in Step 3 of the bagging algorithm.
,
instead of the sample mean in Step 3 of the bagging algorithm.
While bragging regression trees was often found to be slightly less improving than bagging, bragging MARS seems better than the original MARS and much better than bagging MARS.
Bagging ''automatically'' yields an estimate of the out-of-sample
error, sometimes referred to as the generalization error. Consider
a loss
![]() , measuring the discrepancy between an
estimated function
, measuring the discrepancy between an
estimated function ![]() , evaluated at
, evaluated at ![]() , and the corresponding
response
, and the corresponding
response ![]() , e.g.
, e.g.
![]() . The
generalization error is then
. The
generalization error is then
In a bootstrap sample (in the bagging procedure), roughly
![]() of the original observations are left out: they are
called ''out-of-bag'' observations ([10]). Denote by
of the original observations are left out: they are
called ''out-of-bag'' observations ([10]). Denote by
![]() the original sample indices which were resampled in
the
the original sample indices which were resampled in
the ![]() th bootstrap sample; note that the out-of-bag sample
observations (in the
th bootstrap sample; note that the out-of-bag sample
observations (in the ![]() th bootstrap resampling stage) are then given
by
th bootstrap resampling stage) are then given
by
![]() which can be used as
test sets. The out-of-bag error estimate of bagging is then defined as
which can be used as
test sets. The out-of-bag error estimate of bagging is then defined as
![$\displaystyle \widehat{err}_{OB} = n^{-1} \sum_{i=1}^n N_M^{-1} \sum_{k=1}^M {\...
...) \notin \mathcal{B}oot^k\right]} \ell\left(Y_i,\hat{g}^{\ast k}(X_i)\right)\;,$](img7204.gif) |
||
![$\displaystyle N_M = \sum_{k=1}^M {\large {\text{\textbf{1}}}}_{\left[(X_i,Y_i) \notin \mathcal{B}oot^k\right]}\;.$](img7205.gif) |
The main disadvantage of bagging, and other ensemble algorithms, is the lack of interpretation. A linear combination of decision trees is much harder to interpret than a single tree. Likewise: bagging a variable selection - fitting algorithm for linear models (e.g. selecting the variables using the AIC criterion within the least-squares estimation framework) gives little clues which of the predictor variables are actually important.
One way out of this lack of interpretation is sometimes given within the framework of bagging. In ([28]), the bootstrap has been justified to judge the importance of automatically selected variables by looking at relative appearance-frequencies in the bootstrap runs. The bagging estimator is the average of the fitted bootstrap functions, while the appearance frequencies of selected variables or interactions may serve for interpretation.
Bagging may also be useful as a ''module'' in other algorithms: BagBoosting ([17]) is a boosting algorithm (see Sect. 16.3) with a bagged base-procedure, often a bagged regression tree. The theory about bagging supports the finding that BagBoosting using bagged regression trees, which have smaller asymptotic MSEs than trees, is often better than boosting with regression trees. This is empirically demonstrated for a problem about tumor classification using microarray gene expression predictors ([24]).
Bundling classifiers ([37]), which is a more complicated aggregation algorithm but related to bagging, seems to perform better than bagging for classification. In ([45]), bagging is used in conjunction with boosting (namely for stopping boosting iterations) for density estimation. In ([27]), bagging is used in the unsupervised context of cluster analysis, reporting improvements when using bagged clusters instead of original cluster-outputs.