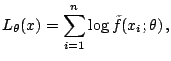It is often argued that financial asset returns are the cumulative outcome of a vast number of pieces of information and individual decisions arriving almost continuously in time ([71,87]). As such, since the pioneering work of Louis Bachelier in 1900, they have been modeled by the Gaussian distribution. The strongest statistical argument for it is based on the Central Limit Theorem, which states that the sum of a large number of independent, identically distributed variables from a finite-variance distribution will tend to be normally distributed. However, financial asset returns usually have heavier tails.
In response to the empirical evidence [64] and [36] proposed the stable distribution as an alternative model. There are at least two good reasons for modeling financial variables using stable distributions. Firstly, they are supported by the generalized Central Limit Theorem, which states that stable laws are the only possible limit distributions for properly normalized and centered sums of independent, identically distributed random variables ([58]). Secondly, stable distributions are leptokurtic. Since they can accommodate the fat tails and asymmetry, they fit empirical distributions much better.
Stable laws - also called ![]() -stable, stable Paretian or Lévy
stable - were
introduced by [61] during his investigations of the behavior
of sums of independent random variables. A sum of two independent
random variables having an
-stable, stable Paretian or Lévy
stable - were
introduced by [61] during his investigations of the behavior
of sums of independent random variables. A sum of two independent
random variables having an ![]() -stable distribution with
index
-stable distribution with
index ![]() is again
is again ![]() -stable with the same
index
-stable with the same
index ![]() . This invariance property, however, does not hold for
different
. This invariance property, however, does not hold for
different ![]() 's.
's.
![\includegraphics[width=10.2cm]{text/4-1/STFstab0102.eps}](img7378.gif)
|
The ![]() -stable distribution requires four parameters for complete
description: an index of stability
-stable distribution requires four parameters for complete
description: an index of stability
![]() also called the
tail index, tail exponent or characteristic exponent, a skewness
parameter
also called the
tail index, tail exponent or characteristic exponent, a skewness
parameter
![]() , a scale parameter
, a scale parameter ![]() and
a location parameter
and
a location parameter
![]() . The tail exponent
. The tail exponent ![]() determines the rate at which the tails of the distribution taper off,
see the left panel of Fig. 1.3.
When
determines the rate at which the tails of the distribution taper off,
see the left panel of Fig. 1.3.
When ![]() , a Gaussian distribution results. When
, a Gaussian distribution results. When ![]() , the
variance is infinite and the tails are asymptotically equivalent to
a Pareto law, i.e. they exhibit a power-law behavior. More precisely,
using a central limit theorem type argument it can be shown that
([48,90]):
, the
variance is infinite and the tails are asymptotically equivalent to
a Pareto law, i.e. they exhibit a power-law behavior. More precisely,
using a central limit theorem type argument it can be shown that
([48,90]):
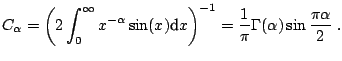 |
From a practitioner's point of view the crucial drawback of the stable
distribution is that, with the exception of three special cases, its
probability density function (PDF) and cumulative distribution
function (CDF) do not have closed form expressions. These exceptions
include the well known Gaussian (![]() ) law, whose density
function is given by:
) law, whose density
function is given by:
Hence, the ![]() -stable distribution can be most conveniently
described by its characteristic function
-stable distribution can be most conveniently
described by its characteristic function ![]() - the inverse
Fourier transform of the PDF. However, there are multiple
parameterizations for
- the inverse
Fourier transform of the PDF. However, there are multiple
parameterizations for ![]() -stable laws and much confusion has been
caused by these different representations. The variety of formulas is
caused by a combination of historical evolution and the numerous
problems that have been analyzed using specialized forms of the stable
distributions. The most popular parameterization of the characteristic
function of
-stable laws and much confusion has been
caused by these different representations. The variety of formulas is
caused by a combination of historical evolution and the numerous
problems that have been analyzed using specialized forms of the stable
distributions. The most popular parameterization of the characteristic
function of
![]() , i.e. an
, i.e. an
![]() -stable random variable with parameters
-stable random variable with parameters ![]() ,
, ![]() ,
,
![]() and
and ![]() , is given by ([90,98]):
, is given by ([90,98]):
![\includegraphics[width=10.2cm]{text/4-1/STFstab04.eps}](img7393.gif)
|
For numerical purposes, it is often useful to use Nolan's (1997) parameterization:
The lack of closed form formulas for most stable densities and
distribution functions has negative consequences. Numerical
approximation or direct numerical integration have to be used, leading
to a drastic increase in computational time and loss of accuracy. Of
all the attempts to be found in the literature a few are worth
mentioning. [29] developed a procedure for approximating the
stable distribution function using Bergström's (1952)
series expansion. Depending on the particular range of ![]() and
and ![]() , [46] combined four alternative
approximations to compute the stable density function. Both algorithms
are computationally intensive and time consuming, making maximum
likelihood estimation a nontrivial task, even for modern
computers. Recently, two other techniques have been proposed.
, [46] combined four alternative
approximations to compute the stable density function. Both algorithms
are computationally intensive and time consuming, making maximum
likelihood estimation a nontrivial task, even for modern
computers. Recently, two other techniques have been proposed.
[75] exploited the density function - characteristic
function relationship and applied the fast Fourier transform
(FFT). However, for data points falling between the equally spaced FFT
grid nodes an interpolation technique has to be used. The authors
suggested that linear interpolation suffices in most practical
applications, see also [87]. Taking a larger number of
grid points increases accuracy, however, at the expense of higher
computational burden. Setting the number of grid points to ![]() and the grid spacing to
and the grid spacing to ![]() allows to achieve comparable
accuracy to the direct integration method (see below), at least for
a range of
allows to achieve comparable
accuracy to the direct integration method (see below), at least for
a range of ![]() 's typically found for financial data (
's typically found for financial data (
![]() ). As for the computational speed, the FFT based
approach is faster for large samples, whereas the direct integration
method favors small data sets since it can be computed at any
arbitrarily chosen point. [75] report that for
). As for the computational speed, the FFT based
approach is faster for large samples, whereas the direct integration
method favors small data sets since it can be computed at any
arbitrarily chosen point. [75] report that for
![]() the FFT based method is faster for samples exceeding
the FFT based method is faster for samples exceeding
![]() observations and slower for smaller data sets.
observations and slower for smaller data sets.
We must stress, however, that the FFT based approach is not as universal as the direct integration method - it is efficient only for large alpha's and only as far as the probability density function calculations are concerned. When computing the cumulative distribution function the former method must numerically integrate the density, whereas the latter takes the same amount of time in both cases.
The direct integration method, proposed by Nolan 1997, 1999) consists of a numerical integration of Zolotarev's (1986) formulas for the density or the distribution function. To save space we state only the formulas for the probability density function. Complete formulas can be also found in [12].
Set
![]() . Then the density
. Then the density
![]() of a standard
of a standard ![]() -stable random variable in
representation
-stable random variable in
representation ![]() , i.e.
, i.e.
![]() , can be
expressed as (note, that Zolotarev 1986, Sect. 2.2) used
yet another parametrization):
, can be
expressed as (note, that Zolotarev 1986, Sect. 2.2) used
yet another parametrization):
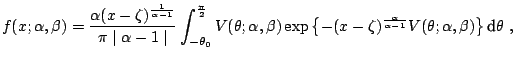 |
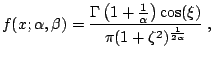 |
![$\displaystyle f(x;1,\beta)= \begin{cases}\displaystyle \frac{1}{2\mid\beta\mid}...
...ne 0\;, \\ [4mm] \displaystyle \frac{1}{\pi(1+x^2)}\;, & \beta=0\;, \end{cases}$](img7411.gif) |
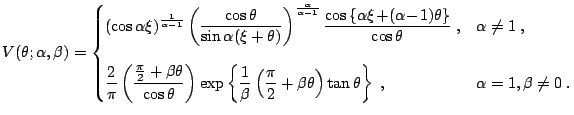 |
It is interesting to note, that currently no other statistical
computing environment offers the computation of stable density and
distribution functions in its standard release. Users have to rely on
third-party libraries or commercial products. A few are worth
mentioning. John Nolan offers the STABLE program in library form
through Robust Analysis Inc., see
http://www.robustanalysis.com. This library (in C, Visual Basic or
Fortran) provides interfaces to Matlab, S-plus (or its GNU
version - R) and Mathematica. Diethelm Würtz has developed Rmetrics,
an open source collection of software packages for S-plus/R, which
may be useful for teaching computational finance, see
http://www.itp.phys.ethz.ch/econophysics/R/. Stable PDF and
CDF calculations are performed using the direct integration method,
with the integrals being computed by R's function
integrate. Interestingly, for symmetric stable distributions
Rmetrics utilizes McCulloch's (1998) approximation, which
was obtained by interpolating between the complements of the Cauchy
and Gaussian CDFs in a transformed space. For
![]() the
absolute precision of the stable PDF and CDF approximation is
the
absolute precision of the stable PDF and CDF approximation is
![]() . The FFT based approach is utilized in Cognity, a commercial
risk management platform that offers derivatives pricing and portfolio
optimization based on the assumption of stably distributed returns,
see http://www.finanalytica.com.
. The FFT based approach is utilized in Cognity, a commercial
risk management platform that offers derivatives pricing and portfolio
optimization based on the assumption of stably distributed returns,
see http://www.finanalytica.com.
The complexity of the problem of simulating sequences of
![]() -stable random variables stems from the fact that there are no
analytic expressions for the inverse
-stable random variables stems from the fact that there are no
analytic expressions for the inverse ![]() nor the cumulative
distribution function
nor the cumulative
distribution function ![]() . All standard approaches like the
rejection or the inversion methods would require tedious
computations. See Chap. II.2 for
a review of non-uniform random number generation techniques.
. All standard approaches like the
rejection or the inversion methods would require tedious
computations. See Chap. II.2 for
a review of non-uniform random number generation techniques.
A much more elegant and efficient solution was proposed by [21]. They noticed that a certain integral formula derived by [100] yielded the following algorithm:
Given the formulas for simulation of a standard ![]() -stable random
variable, we can easily simulate a stable random variable for all
admissible values of the parameters
-stable random
variable, we can easily simulate a stable random variable for all
admissible values of the parameters ![]() ,
, ![]() ,
, ![]() and
and ![]() using the following property: if
using the following property: if
![]() then
then
![$\displaystyle Y=\begin{cases}\sigma X+\mu\;, & \alpha \ne 1\;, \\ [2mm] \displa...
... \sigma X+\frac{2}{\pi}\beta\sigma\log\sigma + \mu\;, & \alpha=1\;, \end{cases}$](img7423.gif) |
Many other approaches have been proposed in the literature, including
application of [8] and LePage ([60]) series
expansions, see [65] and [47],
respectively. However, this method is regarded as the fastest and the
most accurate. In XploRe the algorithm is implemented in the
rndstab
quantlet. On a PC equipped with a Centrino
![]() GHz
processor one million variables are generated in about
GHz
processor one million variables are generated in about ![]() seconds,
compared to about
seconds,
compared to about ![]() seconds for one million standard normal
random variables obtained via the Box-Muller algorithm
(normal2).
Because of its unquestioned superiority and relative simplicity, the
Chambers-Mallows-Stuck method is implemented in some statistical
computing environments (e.g. the rstable function in
S-plus/R) even if no other routines related to stable distributions
are provided.
seconds for one million standard normal
random variables obtained via the Box-Muller algorithm
(normal2).
Because of its unquestioned superiority and relative simplicity, the
Chambers-Mallows-Stuck method is implemented in some statistical
computing environments (e.g. the rstable function in
S-plus/R) even if no other routines related to stable distributions
are provided.
The estimation of stable law parameters is in general severely hampered by the lack of known closed-form density functions for all but a few members of the stable family. Numerical approximation or direct numerical integration are nontrivial and burdensome from a computational point of view. As a consequence, the maximum likelihood (ML) estimation algorithm based on such approximations is difficult to implement and time consuming for samples encountered in modern finance. However, there are also other numerical methods that have been found useful in practice and are discussed in this section.
All presented methods work quite well assuming that the sample under
consideration is indeed ![]() -stable. Since there are no formal
tests for assessing the
-stable. Since there are no formal
tests for assessing the ![]() -stability of a data set we suggest to
first apply the ''visual inspection'' and tail exponent estimators
to see whether the empirical densities resemble those of
-stability of a data set we suggest to
first apply the ''visual inspection'' and tail exponent estimators
to see whether the empirical densities resemble those of
![]() -stable laws ([12,99]).
-stable laws ([12,99]).
Given a sample
![]() of independent and identically
distributed (i.i.d.)
of independent and identically
distributed (i.i.d.)
![]() observations, in
what follows, we provide estimates
observations, in
what follows, we provide estimates
![]() ,
,
![]() ,
,
![]() and
and ![]() of all four stable law parameters. We
start the discussion with the simplest, fastest and
of all four stable law parameters. We
start the discussion with the simplest, fastest and ![]() least
accurate quantile methods, then develop the slower, yet much more
accurate sample characteristic function methods and, finally, conclude
with the slowest but most accurate maximum likelihood approach.
least
accurate quantile methods, then develop the slower, yet much more
accurate sample characteristic function methods and, finally, conclude
with the slowest but most accurate maximum likelihood approach.
[37] provided very simple estimates for parameters of
symmetric (
![]() ) stable laws with
) stable laws with ![]() . They
proposed to estimate
. They
proposed to estimate ![]() by:
by:
The characteristic exponent ![]() , on the other hand, can be
estimated from the tail behavior of the distribution. Fama and Roll
suggested to take
, on the other hand, can be
estimated from the tail behavior of the distribution. Fama and Roll
suggested to take
![]() satisfying:
satisfying:
For
![]() , the stable distribution has finite mean. Hence,
the sample mean is a consistent estimate of the location
parameter
, the stable distribution has finite mean. Hence,
the sample mean is a consistent estimate of the location
parameter ![]() . However, a more robust estimate is the
. However, a more robust estimate is the ![]() truncated sample mean - the arithmetic mean of the middle
truncated sample mean - the arithmetic mean of the middle ![]() percent
of the ranked observations. The
percent
of the ranked observations. The ![]() truncated mean is often
suggested in the literature when the range of
truncated mean is often
suggested in the literature when the range of ![]() is unknown.
is unknown.
Fama and Roll's (1971) method is simple but suffers
from a small asymptotic bias in
![]() and
and
![]() and
restrictions on
and
restrictions on ![]() and
and ![]() . [70] generalized and
improved the quantile method. He analyzed stable law quantiles and
provided consistent estimators of all four stable parameters, with the
restriction
. [70] generalized and
improved the quantile method. He analyzed stable law quantiles and
provided consistent estimators of all four stable parameters, with the
restriction
![]() , while retaining the computational
simplicity of Fama and Roll's method. After McCulloch define:
, while retaining the computational
simplicity of Fama and Roll's method. After McCulloch define:
Scale and location parameters, ![]() and
and ![]() , can be estimated in
a similar way. However, due to the discontinuity of the characteristic
function for
, can be estimated in
a similar way. However, due to the discontinuity of the characteristic
function for ![]() and
and
![]() in representation
(1.3), this procedure is more complicated. We refer
the interested reader to the original work of [70]. This
estimation technique is implemented in XploRe in the stabcull
quantlet.
in representation
(1.3), this procedure is more complicated. We refer
the interested reader to the original work of [70]. This
estimation technique is implemented in XploRe in the stabcull
quantlet.
Given an i.i.d. random sample
![]() of size
of size ![]() , define the
sample characteristic function by:
, define the
sample characteristic function by:
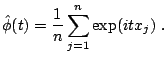 |
[85] proposed a simple estimation method, called the method
of moments, based on transformations of the characteristic
function. From (1.3) we have for all ![]() :
:
| (1.11) |
In the same paper Koutrouvelis presented a much more accurate
regression-type method which starts with an initial estimate of the
parameters and proceeds iteratively until some prespecified
convergence criterion is satisfied. Each iteration consists of two
weighted regression runs. The number of points to be used in these
regressions depends on the sample size and starting values
of ![]() . Typically no more than two or three iterations are
needed. The speed of the convergence, however, depends on the initial
estimates and the convergence criterion.
. Typically no more than two or three iterations are
needed. The speed of the convergence, however, depends on the initial
estimates and the convergence criterion.
The regression method is based on the following observations
concerning the characteristic function ![]() . First,
from (1.3) we can easily derive:
. First,
from (1.3) we can easily derive:
Once
![]() and
and
![]() have been obtained and
have been obtained and ![]() and
and ![]() have been fixed at these values, estimates of
have been fixed at these values, estimates of ![]() and
and ![]() can be obtained using (1.16). Next, the
regressions are repeated with
can be obtained using (1.16). Next, the
regressions are repeated with
![]() ,
,
![]() ,
,
![]() and
and ![]() as the initial parameters. The
iterations continue until a prespecified convergence criterion is
satisfied. Koutrouvelis proposed to use the Fama-Roll
estimator (1.8) and the
as the initial parameters. The
iterations continue until a prespecified convergence criterion is
satisfied. Koutrouvelis proposed to use the Fama-Roll
estimator (1.8) and the ![]() truncated mean for
initial estimates of
truncated mean for
initial estimates of ![]() and
and ![]() , respectively.
, respectively.
[54] eliminated this iteration procedure and simplified
the regression method. For initial estimation they applied McCulloch's
method, worked with the continuous representation (1.4)
of the characteristic function instead of the classical
one (1.3) and used a fixed set of only 10 equally spaced
frequency points ![]() .
In terms of computational speed their method compares favorably to the
original method of Koutrouvelis, see Table 1.1. It has
a significantly better performance near
.
In terms of computational speed their method compares favorably to the
original method of Koutrouvelis, see Table 1.1. It has
a significantly better performance near ![]() and
and
![]() due to the elimination of discontinuity of the characteristic
function. However, it returns slightly worse results for other values
of
due to the elimination of discontinuity of the characteristic
function. However, it returns slightly worse results for other values
of ![]() . In XploRe both regression algorithms are implemented in
the stabreg
quantlet. An optional parameter lets the user choose between the
original Koutrouvelis code and the Kogon-Williams modification.
. In XploRe both regression algorithms are implemented in
the stabreg
quantlet. An optional parameter lets the user choose between the
original Koutrouvelis code and the Kogon-Williams modification.
| Method |
|
|
|
CPU time | |
| McCulloch |
|
||||
| (
|
(
|
(
|
(
|
||
| Moments |
|
||||
| (
|
(
|
(
|
(
|
||
| Koutrouvelis |
|
||||
| (
|
(
|
(
|
(
|
||
| Kogon-Williams |
|
||||
| (
|
(
|
(
|
(
|
A typical performance of the described estimators is summarized in
Table 1.1, see also
Fig. 1.5. McCulloch's quantile technique, the method of
moments, the regression approach of Koutrouvelis and the method of
Kogon and Williams were applied to 100 simulated samples of two
thousand
![]() random numbers each. The method of
moments yielded the worst estimates, clearly outside any admissible
error range. McCulloch's method came in next with acceptable results
and computational time significantly lower than the regression
approaches. On the other hand, both the Koutrouvelis and the
Kogon-Williams implementations yielded good estimators with the
latter performing considerably faster, but slightly less accurate. We
have to say, though, that all methods had problems with
estimating
random numbers each. The method of
moments yielded the worst estimates, clearly outside any admissible
error range. McCulloch's method came in next with acceptable results
and computational time significantly lower than the regression
approaches. On the other hand, both the Koutrouvelis and the
Kogon-Williams implementations yielded good estimators with the
latter performing considerably faster, but slightly less accurate. We
have to say, though, that all methods had problems with
estimating ![]() . Like it or not, our search for the optimal
estimation technique is not over yet. We have no other choice but turn
to the last resort - the maximum likelihood method.
. Like it or not, our search for the optimal
estimation technique is not over yet. We have no other choice but turn
to the last resort - the maximum likelihood method.
![\includegraphics[width=10.2cm]{text/4-1/CSAfin04.eps}](img7512.gif)
|
The maximum likelihood (ML) estimation scheme for ![]() -stable
distributions does not differ from that for other laws, at least as
far as the theory is concerned. For a vector of observations
-stable
distributions does not differ from that for other laws, at least as
far as the theory is concerned. For a vector of observations
![]() , the ML estimate of the parameter vector
, the ML estimate of the parameter vector
![]() is obtained by maximizing the
log-likelihood function:
is obtained by maximizing the
log-likelihood function:
Because of computational complexity there are only a few documented
attempts of estimating stable law parameters via maximum likelihood.
[29] developed an approximate ML method, which was based on
grouping the data set into bins and using a combination of means to
compute the density (FFT for the central values of ![]() and series
expansions for the tails) to compute an approximate log-likelihood
function. This function was then numerically maximized.
and series
expansions for the tails) to compute an approximate log-likelihood
function. This function was then numerically maximized.
Applying Zolotarev's (1964) integral formulas,
[17] formulated another approximate ML method, however,
only for symmetric stable random variables. To avoid the discontinuity
and nondifferentiability of the symmetric stable density function at
![]() , the tail index
, the tail index ![]() was restricted to be greater than
one.
was restricted to be greater than
one.
Much better, in terms of accuracy and computational time, are more recent maximum likelihood estimation techniques. [76] utilized the FFT approach for approximating the stable density function, whereas [81] used the direct integration method. Both approaches are comparable in terms of efficiency. The differences in performance are the result of different approximation algorithms, see Sect. 1.2.2.
As [83] observes, the ML estimates are almost always the most
accurate, closely followed by the regression-type estimates,
McCulloch's quantile method, and finally the method of
moments. However, as we have already said in the introduction to this
section, maximum likelihood estimation techniques are certainly the
slowest of all the discussed methods. For example, ML estimation for
a sample of ![]() observations using a gradient search routine which
utilizes the direct integration method needs
observations using a gradient search routine which
utilizes the direct integration method needs ![]() seconds or about
seconds or about
![]() minutes! The calculations were performed on a PC equipped
with a Centrino
minutes! The calculations were performed on a PC equipped
with a Centrino
![]() GHz processor and running STABLE
ver.
GHz processor and running STABLE
ver. ![]() (see also Sect. 1.2.2 where the program
was briefly described).
For comparison, the STABLE implementation of the Kogon-Williams
algorithm performs the same calculations in only
(see also Sect. 1.2.2 where the program
was briefly described).
For comparison, the STABLE implementation of the Kogon-Williams
algorithm performs the same calculations in only ![]() seconds
(the XploRe quantlet stabreg
needs roughly four times more time, see
Table 1.1). Clearly, the higher accuracy does not
justify the application of ML estimation in many real life problems,
especially when calculations are to be performed on-line. For this
reason the program STABLE also offers an alternative - a fast quasi
ML technique. It quickly approximates stable densities using
a
seconds
(the XploRe quantlet stabreg
needs roughly four times more time, see
Table 1.1). Clearly, the higher accuracy does not
justify the application of ML estimation in many real life problems,
especially when calculations are to be performed on-line. For this
reason the program STABLE also offers an alternative - a fast quasi
ML technique. It quickly approximates stable densities using
a ![]() -dimensional spline interpolation based on pre-computed values of
the standardized stable density on a grid of
-dimensional spline interpolation based on pre-computed values of
the standardized stable density on a grid of
![]() values. At the cost of a large array of coefficients, the
interpolation is highly accurate over most values of the parameter
space and relatively fast -
values. At the cost of a large array of coefficients, the
interpolation is highly accurate over most values of the parameter
space and relatively fast - ![]() seconds for a sample of
seconds for a sample of
![]() observations.
observations.
| Parameters | ||||
| Gaussian fit | ||||
| Test values | Anderson-Darling | Kolmogorov | ||
| Gaussian fit | ||||
| VaR estimates (
|
||||
| Empirical | ||||
| (
|
(
|
|||
| Gaussian fit | (
|
(
|
||
![\includegraphics[width=10.2cm]{text/4-1/CSAfin05.eps}](img7543.gif)
|
In this paragraph we want to apply the discussed techniques to
financial data. Due to limited space we have chosen only one estimation
method - the regression approach of [56], as it offers high
accuracy at moderate computational time. We start the empirical
analysis with the most prominent example - the Dow Jones Industrial
Average (DJIA) index. The data set covers the period January 2,
1985 - November 30, 1992 and comprises ![]() returns. Recall, that
this period includes the largest crash in Wall Street history - the
Black Monday of October 19, 1987. Clearly the
returns. Recall, that
this period includes the largest crash in Wall Street history - the
Black Monday of October 19, 1987. Clearly the ![]() -stable law
offers a much better fit to the DJIA returns than the Gaussian
distribution, see Table 1.2. Its superiority,
especially in the tails of the distribution, is even better visible in
Fig. 1.6.
In this figure we also plotted vertical lines representing the
-stable law
offers a much better fit to the DJIA returns than the Gaussian
distribution, see Table 1.2. Its superiority,
especially in the tails of the distribution, is even better visible in
Fig. 1.6.
In this figure we also plotted vertical lines representing the
![]() -stable, Gaussian and empirical daily VaR estimates at the
-stable, Gaussian and empirical daily VaR estimates at the
![]() and
and ![]() confidence levels. These
estimates correspond to a one day VaR of a virtual portfolio consiting
of one long position in the DJIA index. The stable VaR estimates are
almost twice closer to the empirical estimates than the Gaussian ones,
see Table 1.2.
confidence levels. These
estimates correspond to a one day VaR of a virtual portfolio consiting
of one long position in the DJIA index. The stable VaR estimates are
almost twice closer to the empirical estimates than the Gaussian ones,
see Table 1.2.
Recall that calculating the VaR number reduces to finding the ![]() quantile of a given distribution or equivalently to evaluating the
inverse
quantile of a given distribution or equivalently to evaluating the
inverse ![]() of the distribution function at
of the distribution function at
![]() . Unfortunately no simple algorithms for inverting the stable
CDF are known. The qfstab
quantlet of XploRe utilizes a simple binary search routine for
large
. Unfortunately no simple algorithms for inverting the stable
CDF are known. The qfstab
quantlet of XploRe utilizes a simple binary search routine for
large ![]() 's and values near the mode of the distribution. In the
extreme tails the approximate range of the quantile values is first
estimated via the power law formula (1.1), then a binary
search is conducted.
's and values near the mode of the distribution. In the
extreme tails the approximate range of the quantile values is first
estimated via the power law formula (1.1), then a binary
search is conducted.
To make our statistical analysis more sound, we also compare both fits through Anderson-Darling and Kolmogorov test statistics ([24]). The former may be treated as a weighted Kolmogorov statistics which puts more weight to the differences in the tails of the distributions. Although no asymptotic results are known for the stable laws, approximate critical values for these goodness-of-fit tests can be obtained via the bootstrap technique ([12,94]). In this chapter, though, we will not perform hypothesis testing and just compare the test values. Naturally, the lower the values the better the fit. The stable law seems to be tailor-cut for the DJIA index returns. But does it fit other asset returns as well?
The second analyzed data set comprises ![]() returns of the Deutsche
Aktienindex (DAX) index from the period January 2, 1995 - December 5,
2002. Also in this case the
returns of the Deutsche
Aktienindex (DAX) index from the period January 2, 1995 - December 5,
2002. Also in this case the ![]() -stable law offers a much better
fit than the Gaussian, see Table 1.3. However, the test
statistics suggest that the fit is not as good as for the DJIA returns
(observe that both data sets are of the same size and the test values
in both cases can be compared). This can be also seen in
Fig. 1.7. The left tail seems to drop off at some point
and the very tail is largely overestimated by the stable
distribution. At the same time it is better approximated by the
Gaussian law.
This results in a surprisingly good fit of the daily
-stable law offers a much better
fit than the Gaussian, see Table 1.3. However, the test
statistics suggest that the fit is not as good as for the DJIA returns
(observe that both data sets are of the same size and the test values
in both cases can be compared). This can be also seen in
Fig. 1.7. The left tail seems to drop off at some point
and the very tail is largely overestimated by the stable
distribution. At the same time it is better approximated by the
Gaussian law.
This results in a surprisingly good fit of the daily ![]() VaR
by the Gaussian distribtion, see Table 1.3, and an
overestimation of the daily VaR estimate at the
VaR
by the Gaussian distribtion, see Table 1.3, and an
overestimation of the daily VaR estimate at the
![]() confidence level by the
confidence level by the ![]() -stable distribtion. In fact, the
latter is a rather typical situation. For a risk manager who likes to
play safe this may not be a bad idea, as the stable law overestimates
the risks and thus provides an upper limit of losses.
-stable distribtion. In fact, the
latter is a rather typical situation. For a risk manager who likes to
play safe this may not be a bad idea, as the stable law overestimates
the risks and thus provides an upper limit of losses.
| Parameters | ||||
| Gaussian fit | ||||
| Test values | Anderson-Darling | Kolmogorov | ||
| Gaussian fit | ||||
| VaR estimates (
|
||||
| Empirical | ||||
| (
|
(
|
|||
| Gaussian fit | (
|
(
|
||
![\includegraphics[width=10.2cm]{text/4-1/CSAfin06.eps}](img7565.gif)
|
This example clearly shows that the ![]() -stable distribution is
not a panacea. Although it gives a very good fit to a number of
empirical data sets, there surely are distributions that recover the
characteristics of other data sets better. We devote the rest of this
chapter to such alternative heavy tailed distributions. We start with
a modification of the stable law and in Sect. 1.3
concentrate on the class of generalized hyperbolic distributions.
-stable distribution is
not a panacea. Although it gives a very good fit to a number of
empirical data sets, there surely are distributions that recover the
characteristics of other data sets better. We devote the rest of this
chapter to such alternative heavy tailed distributions. We start with
a modification of the stable law and in Sect. 1.3
concentrate on the class of generalized hyperbolic distributions.
Mandelbrot's (1963) pioneering work on applying
![]() -stable distributions to asset returns gained support in the
first few years after its publication
([36,82,95]). Subsequent works, however, have
questioned the stable distribution hypothesis
([1,11]). By the definition of the stability
property, the sum of i.i.d. stable random variables is also
stable. Thus, if short term asset returns are distributed according to
a stable law, longer term returns should retain the same functional
form. However, from the empirical data it is evident that as the time
interval between price observations grows longer, the distribution of
returns deviates from the short term heavy tailed distribution, and
converges to the Gaussian law. This indicates that the returns
probably are not
-stable distributions to asset returns gained support in the
first few years after its publication
([36,82,95]). Subsequent works, however, have
questioned the stable distribution hypothesis
([1,11]). By the definition of the stability
property, the sum of i.i.d. stable random variables is also
stable. Thus, if short term asset returns are distributed according to
a stable law, longer term returns should retain the same functional
form. However, from the empirical data it is evident that as the time
interval between price observations grows longer, the distribution of
returns deviates from the short term heavy tailed distribution, and
converges to the Gaussian law. This indicates that the returns
probably are not ![]() -stable (but it could mean as well that the
returns are just not independent). Over the next few years, the stable
distribution temporarily lost favor and alternative processes were
suggested as mechanisms generating stock returns.
-stable (but it could mean as well that the
returns are just not independent). Over the next few years, the stable
distribution temporarily lost favor and alternative processes were
suggested as mechanisms generating stock returns.
In mid 1990s the stable distribution hypothesis has made a dramatic
comeback. Several authors have found a very good agreement of
high-frequency returns with a stable distribution up to six standard
deviations away from the mean ([23,67]). For
more extreme observations, however, the distribution they have found
falls off approximately exponentially. To cope with such observations
the truncated Lévy distributions (TLD) were introduced by
[66]. The original definition postulated a sharp
truncation of the ![]() -stable probability density function at some
arbitrary point. However, later an exponential smoothing was proposed
by [55].
-stable probability density function at some
arbitrary point. However, later an exponential smoothing was proposed
by [55].
For
![]() the characteristic function of a symmetric TLD
random variable is given by:
the characteristic function of a symmetric TLD
random variable is given by:
![$\displaystyle \log\phi(t) = -\frac{\sigma^{\alpha}}{\cos\frac{\pi\alpha}{2}} \l...
...pha \arctan \frac{\vert t\vert}{\lambda} \right\} - \lambda^{\alpha} \right]\;,$](img7566.gif) |
Despite these interesting features the truncated Lévy distributions
have not been applied extensively to date. The most probable reason
for this being the complicated definition of the TLD law. Like for
![]() -stable distributions, only the characteristic function is
known. No closed form formulas exist for the density or the
distribution function. Since no integral formulas, like Zolotarev's
(1986) for the
-stable distributions, only the characteristic function is
known. No closed form formulas exist for the density or the
distribution function. Since no integral formulas, like Zolotarev's
(1986) for the ![]() -stable laws, have been discovered
as yet, statistical inference is, in general, limited to maximum
likelihood utilizing the FFT technique for approximating the
PDF. Moreover, compared to the stable distribution, the TLD introduces
one more parameter (asymmetric TLD laws have also been considered in
the literature, see e.g. [15] and [55]) making
the estimation procedure even more complicated. Other parameter
fitting techniques proposed so far comprise a combination of ad hoc
approaches and moment matching ([15,69]). Better
techniques have to be discovered before TLDs become a common tool in
finance.
-stable laws, have been discovered
as yet, statistical inference is, in general, limited to maximum
likelihood utilizing the FFT technique for approximating the
PDF. Moreover, compared to the stable distribution, the TLD introduces
one more parameter (asymmetric TLD laws have also been considered in
the literature, see e.g. [15] and [55]) making
the estimation procedure even more complicated. Other parameter
fitting techniques proposed so far comprise a combination of ad hoc
approaches and moment matching ([15,69]). Better
techniques have to be discovered before TLDs become a common tool in
finance.
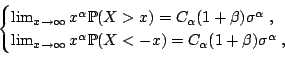
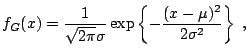
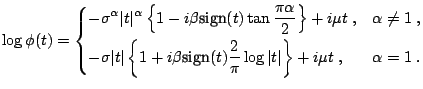
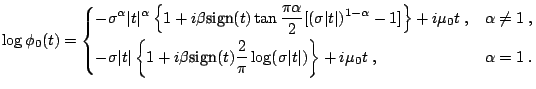
![$\displaystyle \xi =\begin{cases}\displaystyle \frac{1}{\alpha} \arctan(-\zeta)\...
...lpha \ne 1\;, \\ [4mm] \displaystyle \frac{\pi}{2}\;, & \alpha=1\;, \end{cases}$](img7412.gif)
![$\displaystyle X = (1+\zeta^2)^{\frac{1}{2\alpha}} \frac{\sin\{ \alpha(U+\xi)\}}...
...\left[\frac{\cos\{U - \alpha(U+\xi) \}}{W} \right]^{\frac{1-\alpha}{\alpha}}\;,$](img7420.gif)
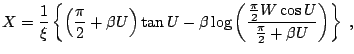
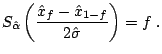
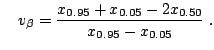
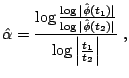
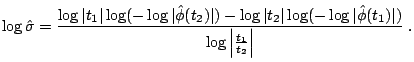
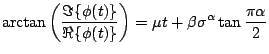 sign
sign