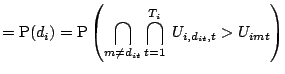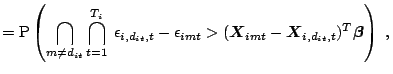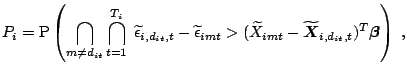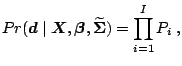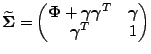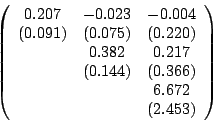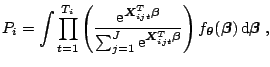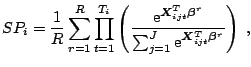This section deals with models in which the dependent variable is discrete. Many interesting problems like labour force participation, presidential voting, transport mode choice and brand choice are discrete in nature. In particular, we consider discrete choice models in the case where panel data are available. This allows, for example, to follow individuals with their choices over time, so that richer behavioural models can be constructed. Although the number of parameters in these models does not necessarily increase, the likelihood function, and therefore estimation, becomes more complex. In this section we describe the multinomial multiperiod probit, the multivariate probit and the mixed multinomial logit model. Examples are given.
We refer to [37] for a general introduction to limited dependent and qualitative variables in econometrics and to [22] for a basic introduction motivating such models in relation to marketing.
Denote by ![]() the unobserved utility
perceived by individual
the unobserved utility
perceived by individual ![]() who chooses alternative
who chooses alternative ![]() at
time
at
time ![]() . This utility may be modelled as follows
. This utility may be modelled as follows
| (2.2) |
| (2.3) |
| (2.6) |
As an identification restriction, one usually imposes a unit variance for the last alternative expressed in utility differences. Define
| (2.7) |
This section briefly explains how the multinomial multiperiod probit model can be estimated in the classical or Bayesian framework. More details can be found in [25].
Since we assume independent observations on individuals the likelihood is
Alternative estimation methods are based on simulations of the choice probabilities. The simulated maximum likelihood (SML) method maximizes the simulated likelihood which is obtained by substituting the simulated choice probabilities in (2.9). The method of simulated moments is a simulation based substitute for the generalized method of moments. For further information on these estimation methods we refer to [27].
It is possible to extend the model in (2.5) in
various ways, such as alternative specific
![]() 's,
individual heterogeneity
or a dynamic specification.
's,
individual heterogeneity
or a dynamic specification.
[41] propose a dynamic specification
The model parameters are
![]() and
and
![]() and are augmented by the latent
utilities
and are augmented by the latent
utilities
![]() . Bayesian inference
may be done by Gibbs sampling
as described in the estimation part above. Table 2.1
describes for each of the nine blocks which posterior distribution is
used. For example,
. Bayesian inference
may be done by Gibbs sampling
as described in the estimation part above. Table 2.1
describes for each of the nine blocks which posterior distribution is
used. For example, ![]() has a conditional (on all other parameters)
posterior density
that is normal.
has a conditional (on all other parameters)
posterior density
that is normal.
| Parameter | Conditional posterior |
|
|
Multivariate normal distributions |
|
|
Inverted Wishart distributions |
|
|
Matrix normal distribution |
|
|
Truncated multivariate normal |
As an illustration we reproduce the results of
[41], who provided their Gauss code (which we slightly
modified). They use optical scanner data
on purchases of four brands of saltine
crackers. [13] use the same data set to estimate
a static multinomial probit
model. The data set contains all purchases (choices) of crackers of
![]() households over a period of two years, yielding
households over a period of two years, yielding
![]() observations. Variables such as prices of the brands and
whether there was a display and/or newspaper feature of the
considered brands at the time of purchase are also observed and used
as the explanatory variables forming
observations. Variables such as prices of the brands and
whether there was a display and/or newspaper feature of the
considered brands at the time of purchase are also observed and used
as the explanatory variables forming
![]() (and then
transformed into
(and then
transformed into
![]() ). Table 2.2 gives the
means of these variables. Display and Feature are dummy variables,
e.g. Sunshine was displayed
). Table 2.2 gives the
means of these variables. Display and Feature are dummy variables,
e.g. Sunshine was displayed ![]() and was featured
and was featured ![]() of the purchase occasions. The average market shares reflect the
observed individual choices, with e.g.
of the purchase occasions. The average market shares reflect the
observed individual choices, with e.g. ![]() of the choices on
Sunshine.
of the choices on
Sunshine.
| Sunshine | Keebler | Nabisco | Private Label | |
| Market share | ||||
| Display | ||||
| Feature | ||||
| Price |
Table 2.3 shows
posterior means and standard deviations for the
![]() and
and
![]() parameters. They are computed from
parameters. They are computed from ![]() draws
after dropping
draws
after dropping ![]() initial draws. The prior
on
initial draws. The prior
on
![]() is
inverted Wishart, denoted by
is
inverted Wishart, denoted by
![]() , with
, with ![]() and
and
![]() chosen such that
chosen such that
![]() . Note that
[41] use a prior
such that
. Note that
[41] use a prior
such that
![]() . For the
other parameters we put
uninformative priors. As expected, Display and Feature have positive
effects on the choice probabilities
and price has a negative effect. This holds both in the short run and
the long run. With respect to the private label (which serves as
reference category), the
posterior means of the intercepts are positive except for the first
label whose intercept is imprecisely estimated.
. For the
other parameters we put
uninformative priors. As expected, Display and Feature have positive
effects on the choice probabilities
and price has a negative effect. This holds both in the short run and
the long run. With respect to the private label (which serves as
reference category), the
posterior means of the intercepts are positive except for the first
label whose intercept is imprecisely estimated.
|
|
|
Intercepts | |||||
| mean | st. dev. | mean | st. dev. | mean | st. dev. | ||
| Display | ( |
( |
Sunshine | ( |
|||
| Feature | ( |
( |
Keebler | ( |
|||
| Price | ( |
( |
Nabisco | ( |
|||
Table 2.4 gives the
posterior means and standard deviations of
![]() ,
,
![]() ,
,
![]() and
and
![]() . Note that the reported
last element of
. Note that the reported
last element of
![]() is equal to
is equal to ![]() in order to
identify the model. This is done, after running the Gibbs sampler
with
in order to
identify the model. This is done, after running the Gibbs sampler
with
![]() unrestricted, by dividing the variance
related parameter draws by
unrestricted, by dividing the variance
related parameter draws by
![]() . The
other parameter draws are divided by the square root of the same
quantity. [39] propose an alternative
approach where
. The
other parameter draws are divided by the square root of the same
quantity. [39] propose an alternative
approach where
![]() is fixed to
is fixed to ![]() by
construction, i.e. a fully identified parameter approach. They write
by
construction, i.e. a fully identified parameter approach. They write
The relatively large
posterior means of the diagonal elements of
![]() show that
there is persistence in brand choice.
The matrices
show that
there is persistence in brand choice.
The matrices
![]() and
and
![]() measure the unobserved
heterogeneity. There seems to be substantial heterogeneity
across the individuals, especially for the price of the products (see
the third diagonal elements of both matrices). The last three elements
in
measure the unobserved
heterogeneity. There seems to be substantial heterogeneity
across the individuals, especially for the price of the products (see
the third diagonal elements of both matrices). The last three elements
in
![]() are related to the
intercepts.
are related to the
intercepts.
The multinomial probit model is frequently used for marketing purposes. For example, [1] use ketchup purchase data to emphasize the importance of a detailed understanding of the distribution of consumer heterogeneity and identification of preferences at the customer level. In fact, the disaggregate nature of many marketing decisions creates the need for models of consumer heterogeneity which pool data across individuals while allowing for the analysis of individual model parameters. The Bayesian approach is particularly suited for that, contrary to classical approaches that yields only aggregate summaries of heterogeneity.
The multivariate probit
model relaxes the assumption that choices are mutually exclusive, as
in the multinomial model discussed before. In that case, ![]() may
contain several
may
contain several ![]() 's. [10] discuss classical and
Bayesian inference
for this model. They also provide examples on
voting behavior, on health effects of air pollution and on labour
force participation.
's. [10] discuss classical and
Bayesian inference
for this model. They also provide examples on
voting behavior, on health effects of air pollution and on labour
force participation.
The multinomial logit model
is defined as in (2.1), except that the random
shock
![]() is extreme value (or Gumbel)
distributed. This gives rise to the
independence from irrelevant alternatives (IIA)
property which essentially means that
is extreme value (or Gumbel)
distributed. This gives rise to the
independence from irrelevant alternatives (IIA)
property which essentially means that
![]() . Like
the probit
model, the
mixed multinomial logit (MMNL)
model alleviates this restrictive
IIA
property by treating the
. Like
the probit
model, the
mixed multinomial logit (MMNL)
model alleviates this restrictive
IIA
property by treating the
![]() parameter as a random vector
with density
parameter as a random vector
with density
![]() . The latter
density is called the mixing density
and is usually assumed to be a
normal,
lognormal,
triangular or
uniform distribution. To make clear why this model does not suffer
from
the IIA
property, consider the following example. Suppose that there is only
explanatory variable and that
. The latter
density is called the mixing density
and is usually assumed to be a
normal,
lognormal,
triangular or
uniform distribution. To make clear why this model does not suffer
from
the IIA
property, consider the following example. Suppose that there is only
explanatory variable and that
![]() . We can then write (2.1)
as
. We can then write (2.1)
as
| (2.14) | ||
The mixed logit probability is given by
Estimation of the MMNL model can be done by SML or the method of simulated moments or simulated scores. To do this, the logit probability in (2.15) is replaced by its simulated counterpart
According to [27] the SML estimator
is asymptotically equivalent to the ML estimator if ![]() (the total
number of observations) and
(the total
number of observations) and ![]() both tend to infinity and
both tend to infinity and
![]() . In practice, it is sufficient to fix
. In practice, it is sufficient to fix ![]() at
a moderate value.
at
a moderate value.
The approximation of an integral like in (2.15) by the use of pseudo-random numbers may be questioned. [6] implements an alternative quasi-random SML method which uses quasi-random numbers. Like pseudo-random sequences, quasi-random sequences, such as Halton sequences, are deterministic, but they are more uniformly distributed in the domain of integration than pseudo-random ones. The numerical experiments indicate that the quasi-random method provides considerably better accuracy with much fewer draws and computational time than does the usual random method.
Let us suppose that the
mixing distribution is
Gaussian, that is, the vector
![]() is normally distributed
with mean
is normally distributed
with mean
![]() and variance matrix
and variance matrix
![]() . The posterior
density
for
. The posterior
density
for ![]() individuals can be written as
individuals can be written as
For the first two blocks the conditional posterior densities are known and are easy to sample from. The last block is more difficult. To sample from this density, a Metropolis Hastings (MH) algorithm is set up. Note that only one iteration is necessary such that simulation within the Gibbs sampler is avoided. See [50], Chap. 12, for a detailed description of the MH algorithm for the mixed logit model and for guidelines about how to deal with other mixing densities. More general information on the MH algorithm can be found in Chap. II.3.
Bayesian inference
in the
mixed logit model is called
hierarchical Bayes because of the hierarchy of parameters. At the
first level, there are the individual parameters
![]() which are distributed with mean
which are distributed with mean
![]() and variance
matrix
and variance
matrix
![]() . The latter are called hyper-parameters, on which
we have also
prior densities. They form the second level of the hierarchy.
. The latter are called hyper-parameters, on which
we have also
prior densities. They form the second level of the hierarchy.
We reproduce the results of [40] using their Gauss
code available on the web site
elsa.berkeley.edu/![]() train/software.html. They analyse the demand
for alternative vehicles. There are
train/software.html. They analyse the demand
for alternative vehicles. There are ![]() respondents who choose
among six alternatives (two alternatives run on electricity
only). There are
respondents who choose
among six alternatives (two alternatives run on electricity
only). There are ![]() explanatory variables among which
explanatory variables among which ![]() are
considered to have a random effect. The mixing distributions
for these random coefficients are independent
normal distributions. The model is estimated by SML
and uses
are
considered to have a random effect. The mixing distributions
for these random coefficients are independent
normal distributions. The model is estimated by SML
and uses ![]() replications per
observation. Table 2.6 includes partly the
estimation results of the
MMNL
model. We report the estimates and standard errors of the parameters
of the
normal
mixing distributions, but we do not report the estimates of the fixed
effect parameters corresponding to the
replications per
observation. Table 2.6 includes partly the
estimation results of the
MMNL
model. We report the estimates and standard errors of the parameters
of the
normal
mixing distributions, but we do not report the estimates of the fixed
effect parameters corresponding to the ![]() other explanatory
variables. For example, the luggage space error component induces
greater covariance in the stochastic part of
utility for pairs of vehicles with greater luggage space. We refer to
[40] or [8] for more
interpretations of the results.
other explanatory
variables. For example, the luggage space error component induces
greater covariance in the stochastic part of
utility for pairs of vehicles with greater luggage space. We refer to
[40] or [8] for more
interpretations of the results.
[50] provides more information and pedagogical examples on the mixed multinomial model.
| Variable | Mean | Standard deviation | ||
| Electric vehicle (EV) dummy | ( |
( |
||
| Compressed natural gass (CNG) dummy | ( |
( |
||
| Size | ( |
( |
||
| Luggage space | ( |
( |
||