Numerical problems arising in some applications, such as seemingly unrelated regressions, spatial statistics, or support vector machines (Chap. III.15), are sparse: they often involve large matrices, which have only a small number of nonzero elements. (It is difficult to specify what exactly ''small number'' is.) From the practical point of view, a matrix is sparse if it has so many zero elements that it is worth to inspect their structure and use appropriate methods to save storage and the number of operations. Some sparse matrices show a regular pattern of nonzero elements (e.g., band matrices), while some exhibit a rather irregular pattern. In both cases, solving the respective problem efficiently means to store and operate on only nonzero elements and to keep the ''fill,'' the number of newly generated nonzero elements, as small as possible.
In this section, we first discuss some of storage schemes for sparse matrices, which could indicate what types of problems can be effectively treated as sparse ones (Sect. 4.5.1). Later, we give examples of classical algorithms adopted for sparse matrices (Sect. 4.5.2). Monographs introducing a range of methods for sparse matrices include [12,27] and [54].
To save storage, only nonzero elements of a sparse vector or matrix should be stored. There are various storage schemes, which require approximately from two to five times the number of nonzero elements to store a vector or a matrix. Unfortunately, there is no standard scheme. We discuss here the widely used and sufficiently general compressed (row) storage for vectors and for general and banded matrices.
The compressed form of a vector
![]() consists of a triplet
consists of a triplet
![]() , where
, where
![]() is a vector containing nonzero elements
of
is a vector containing nonzero elements
of
![]() ,
,
![]() is an integer vector containing the indices of
elements stored in
is an integer vector containing the indices of
elements stored in
![]() and
and ![]() specifies the number of nonzero
elements. The stored elements are related to the original vector by
formula
specifies the number of nonzero
elements. The stored elements are related to the original vector by
formula
![]() for
for
![]() . To give an
example, the vector
. To give an
example, the vector
![]() could be
stored as
could be
stored as
The compressed row storage for matrices is a generalization of the
vector concept. We store the nonzero elements of
![]() as a set of
sparse row (or column) vectors in the compressed form. The main
difference is that, instead of a single number
as a set of
sparse row (or column) vectors in the compressed form. The main
difference is that, instead of a single number ![]() , we need to store
a whole vector
, we need to store
a whole vector
![]() specifying the positions of the first row
elements of
specifying the positions of the first row
elements of
![]() in
in
![]() . For example, the matrix
. For example, the matrix
 |
A special type of sparse matrices are matrices with a banded structure.
A banded matrix
![]() is considered to be sparse if
is considered to be sparse if
![]() . Contrary to the general case, vector
. Contrary to the general case, vector
![]() of a banded matrix
typically contains for each row all elements between the first and
last nonzero ones. Thus, the storage scheme does not have to include
in
of a banded matrix
typically contains for each row all elements between the first and
last nonzero ones. Thus, the storage scheme does not have to include
in
![]() all column indices, only one index for the first nonzero
element in a row. On the other hand, zeros within the band have to be
stored as well. For example, the matrix
all column indices, only one index for the first nonzero
element in a row. On the other hand, zeros within the band have to be
stored as well. For example, the matrix
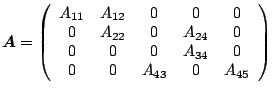 |
 |
Details on some other storage schemes can be found in [12] and [52].
Methods for sparse matrices are still subject to intensive research. Moreover, the choice of a suitable method for a given problem (and even the choice of an algorithm for elementary operations such as matrix-vector multiplication) depends on many factors, including dimension, matrix type storage scheme, and computational environment (e.g., storage in virtual memory vs. auxiliary storage; vector vs. parallel computing, etc.). Therefore, we provide only a general overview and references to most general results. More details can be found in [7,11,12,27] and [54].
First, many discussed algorithms can be relatively easily adopted for banded matrices. For example, having a row-based storage scheme, one just needs to modify the summation limits in the row version of Cholesky decomposition. Moreover, the positions of nonzero elements can be determined in advance ([49]).
Second, the algorithms for general sparse matrices are more
complicated. A graph representation may be used to capture the nonzero
pattern of a matrix as well as to predict the pattern of the result
(e.g., the nonzero pattern of
![]() , the Cholesky factor
, the Cholesky factor
![]() , etc.). To give an overview, methods adopted for sparse matrices
include, but are not limited to, usually used decompositions (e.g.,
Cholesky, [49]; LU and LDU, [48]; QR,
[18], and [32]), solving systems of equations
by direct ([26,61]) and iterative methods
([43,68]) and searching eigenvalues
([4,25]).
, etc.). To give an overview, methods adopted for sparse matrices
include, but are not limited to, usually used decompositions (e.g.,
Cholesky, [49]; LU and LDU, [48]; QR,
[18], and [32]), solving systems of equations
by direct ([26,61]) and iterative methods
([43,68]) and searching eigenvalues
([4,25]).