 gkalarray
. The quantlet adjusts the measurement
matrices for missing observations.
gkalarray
. The quantlet adjusts the measurement
matrices for missing observations.
The procedure for Kalman filtering in
XploRe
is as follows: first, one has to set up
the system matrices using
gkalarray
. The quantlet adjusts the measurement
matrices for missing observations.
After the set up of the system matrices, we calculate the Kalman filter with
gkalfilter
. This quantlet also calculates the value of the log likelihood
function given in equation (13.9). That value will be used to estimate
the unknown parameters of the system matrices with numerical maximization (Hamilton; 1994, Chapter
5). The first and second derivatives of the log likelihood function will also be calculated
numerically. To estimate the unknown state vectors--given the estimated parameters--we use the
Kalman smoother
gkalsmoother
. For diagnostic checking, we use the standardized
residuals (13.11). The quantlet
gkalresiduals
calculates
these residuals.
|
The Kalman filter quantlets need as arguments arrays consisting of the system matrices.
The quantlet
gkalarray
sets these arrays in a user-friendly way. The routine is
especially convenient if one works with time varying system matrices. In our SSF
(13.4), only the system matrix ![]() is time varying. As one can see
immediately from the general SSF (13.3), possibly every system matrix can be time
varying.
is time varying. As one can see
immediately from the general SSF (13.3), possibly every system matrix can be time
varying.
The quantlet uses a three step procedure to set up the system matrices.
gkalarray
uses the following notation: ![]() denotes the matrix of all
observations
denotes the matrix of all
observations
![]() ,
, ![]() denotes the system matrix,
denotes the system matrix, ![]() denotes the
corresponding index matrix and
denotes the
corresponding index matrix and ![]() the data matrix.
the data matrix.
If all entries of a system matrix are constant over time, then the parameters have already been put directly into the system matrix. In this case, one should set the index and the data matrix to 0.
For every time varying system matrix, only constant parameters--if there are any--have already been specified with the system matrix. The time-varying coefficients have to be specified in the index and the data matrix.
In our example, only the matrices ![]() are time varying. We have
are time varying. We have
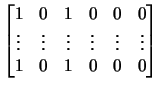 |
|||
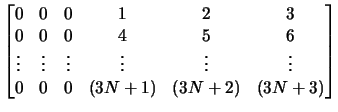 |
|||
The system matrix ![]() has the dimension
has the dimension
![]() . The non-zero entries in the index
matrix
. The non-zero entries in the index
matrix ![]() prescribe the rows of
XFGhousequality
, which contain the time
varying elements.
prescribe the rows of
XFGhousequality
, which contain the time
varying elements.
The output of the quantlet is an array that stacks the system matrices one after the
other. For example, the first two rows of the system matrix ![]() are
are
[1,] 1 0 1 6.1048 4.7707 53 [2,] 1 0 1 6.5596 5.1475 13
It is easy to check that the entries in the last three columns are just the
characteristics of the first two houses that were sold in 1990:1 (see
p. ![]() ).
).
|
We assume that the initial state vector at ![]() has mean
has mean ![]() and covariance matrix
and covariance matrix
![]() . Recall, that
. Recall, that ![]() and
and ![]() denote the covariance matrix of the state noise
and--respectively--of the measurement noise. The general filter recursions are as
follows:
denote the covariance matrix of the state noise
and--respectively--of the measurement noise. The general filter recursions are as
follows:
Start at ![]() : use the initial guess for
: use the initial guess for ![]() and
and ![]() to calculate
to calculate
and
Step at
![]() : using
: using ![]() and
and ![]() from the previous step,
calculate
from the previous step,
calculate
The implementation for our model is as follows: The arguments of
gkalfilter
are
the data matrix Y, the starting values mu (![]() ), Sig (
), Sig (![]() ) and
the array for every system matrix (see section 13.5.2). The output is a
) and
the array for every system matrix (see section 13.5.2). The output is a
![]() dimensional array of
dimensional array of
![]() matrices. If one
chooses
matrices. If one
chooses ![]() the value of the log likelihood function (13.9) is
calculated.
the value of the log likelihood function (13.9) is
calculated.
Once again, the ![]() matrices are stacked ``behind each other", with the
matrices are stacked ``behind each other", with the ![]() matrix at
the front and the
matrix at
the front and the ![]() matrix at the end of the array. The first entry is
matrix at the end of the array. The first entry is
![]() .
.
How can we provide initial values for the filtering procedure? If the state matrices are
non time-varying and the transition matrix ![]() satisfies some stability condition, we
should set the initial values to the unconditional mean and variance of the state vector.
satisfies some stability condition, we
should set the initial values to the unconditional mean and variance of the state vector.
![]() is given implicitly by
is given implicitly by
| vec |
Here, vec denotes the vec-operator that places the columns of a matrix below each other
and ![]() denotes the Kronecker product. Our model is time-invariant. But does our
transition matrix fulfill the stability condition? The necessary and sufficient condition
for stability is that the characteristic roots of the transition matrix
denotes the Kronecker product. Our model is time-invariant. But does our
transition matrix fulfill the stability condition? The necessary and sufficient condition
for stability is that the characteristic roots of the transition matrix ![]() should have
modulus less than one (Harvey; 1989, p. 114). It is easy to check that the
characteristic roots
should have
modulus less than one (Harvey; 1989, p. 114). It is easy to check that the
characteristic roots ![]() of our transition matrix (13.4a) are
given as
of our transition matrix (13.4a) are
given as
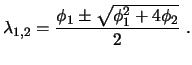 |
For example, if ![]() and
and ![]() are both positive, then
are both positive, then
![]() guarantees real characteristic roots that are smaller than one (Baumol; 1959, p. 221).
However, when the AR(2) process of the common price component
guarantees real characteristic roots that are smaller than one (Baumol; 1959, p. 221).
However, when the AR(2) process of the common price component ![]() has a unit root, the
stability conditions are not fulfilled. If we inspect Figure 13.1, a unit
root seems quite plausible. Thus we can not use this method to derive the initial values.
has a unit root, the
stability conditions are not fulfilled. If we inspect Figure 13.1, a unit
root seems quite plausible. Thus we can not use this method to derive the initial values.
If we have some preliminary estimates of ![]() , along with preliminary measures of
uncertainty--that is a estimate of
, along with preliminary measures of
uncertainty--that is a estimate of ![]() --we can use these preliminary estimates as
initial values. A standard way to derive such preliminary estimates is to use OLS.
If we have no information at all, we must take diffuse priors about the initial
conditions. A method adopted by Koopman, Shephard and Doornik (1999) is setting
--we can use these preliminary estimates as
initial values. A standard way to derive such preliminary estimates is to use OLS.
If we have no information at all, we must take diffuse priors about the initial
conditions. A method adopted by Koopman, Shephard and Doornik (1999) is setting ![]() and
and
![]() where
where ![]() is an large number. The large variances on the diagonal
of
is an large number. The large variances on the diagonal
of ![]() reflect our uncertainty about the true
reflect our uncertainty about the true ![]() .
.
|
| ||||||||||||||||||||||||||||||||
We will use the second approach for providing some preliminary estimates as initial
values. Given the hedonic equation (13.1), we use OLS to estimate ![]() ,
,
![]() , and
, and
![]() by regressing log prices on lot size, floor space, age and quarterly time dummies. The estimated coefficients of lot size, floor space and age are
reported in Table 13.1. They are highly significant and reasonable in sign and magnitude. Whereas lot size and floor space increase the price on average, age has the opposite effect.
According to (13.1), the common price component
by regressing log prices on lot size, floor space, age and quarterly time dummies. The estimated coefficients of lot size, floor space and age are
reported in Table 13.1. They are highly significant and reasonable in sign and magnitude. Whereas lot size and floor space increase the price on average, age has the opposite effect.
According to (13.1), the common price component ![]() is a time-varying constant term and is therefore estimated by the coefficients of the quarterly time dummies, denoted by
is a time-varying constant term and is therefore estimated by the coefficients of the quarterly time dummies, denoted by
![]() . As suggested by (13.2), these estimates are regressed on their lagged values to obtain estimates of the unknown parameters
. As suggested by (13.2), these estimates are regressed on their lagged values to obtain estimates of the unknown parameters ![]() ,
, ![]() , and
, and
![]() .
Table 13.2 presents the results for an AR(2) for the
.
Table 13.2 presents the results for an AR(2) for the ![]() series.
series.
| ||||||||||||||||||||||||||||||||
The residuals of this regression behave like white noise. We should remark that
and thus the process of the common price component seems to have a unit root.
Given our initial values we maximize the log likelihood (13.9) numerically with respect to the elements of
![]() Note that
Note that ![]() differs from
differs from ![]() by using the logarithm of the variances
by using the logarithm of the variances
![]() and
and
![]() This transformation is known to improve the numerical stability of the maximization algorithm, which employs
nmBFGS
of
XploRe
's
nummath
library. Standard errors are computed from inverting the Hessian matrix provided by
nmhessian
. The output of the maximum likelihood estimation procedure is summarized in Table 13.3, where we report the estimates of
This transformation is known to improve the numerical stability of the maximization algorithm, which employs
nmBFGS
of
XploRe
's
nummath
library. Standard errors are computed from inverting the Hessian matrix provided by
nmhessian
. The output of the maximum likelihood estimation procedure is summarized in Table 13.3, where we report the estimates of
![]() and
and
![]() obtained by retransforming the estimates of
obtained by retransforming the estimates of
![]() and
and
![]()
| ||||||||||||||||||||||||||||||
|
The quantlet gkalresiduals checks internally for the positive definiteness of
![]() . An error message will be displayed when
. An error message will be displayed when ![]() is not positive definite. In such a
case, the standardized residuals are not calculated.
is not positive definite. In such a
case, the standardized residuals are not calculated.
The output of the quantlet are two ![]() matrices V and Vs. V
contains the innovations (13.10) and Vs contains the standardized
residuals (13.11).
matrices V and Vs. V
contains the innovations (13.10) and Vs contains the standardized
residuals (13.11).
The Q-Q plot of the standardized residuals in Figure 13.2 shows deviations from normality at both tails of the distribution.
![\includegraphics[width=1.5\defpicwidth]{XFGsssmdisplay3.ps}](xfghtmlimg2392.gif)
|
This is evidence, that the true error distribution might be a unimodal distribution with heavier tails than the normal, such as the ![]() -distribution. In this case the projections calculated by the Kalman filter no longer provide the conditional expectations of the state vector but rather its best linear prediction. Moreover the estimates of
-distribution. In this case the projections calculated by the Kalman filter no longer provide the conditional expectations of the state vector but rather its best linear prediction. Moreover the estimates of ![]() calculated from the likelihood (13.9) can be interpreted as pseudo-likelihood estimates.
calculated from the likelihood (13.9) can be interpreted as pseudo-likelihood estimates.
|
The Kalman filter is a convenient tool for calculating the conditional expectations and
covariances of our SSF (13.4). We have used the innovations of this filtering
technique and its covariance matrix for calculating the log likelihood. However, for
estimating the unknown state vectors, we should use in every step the whole sample
information up to period ![]() . For this task, we use the Kalman smoother.
. For this task, we use the Kalman smoother.
The quantlet
gkalsmoother
needs as argument the output of
gkalfilter
. The
output of the smoother is an array with
![]() matrices. This array of dimension
matrices. This array of dimension ![]() starts with the
starts with the ![]() matrix and ends with the
matrix for
matrix and ends with the
matrix for ![]() .
For the smoother recursions, one needs
.
For the smoother recursions, one needs ![]() ,
, ![]() and
and ![]() for
for
![]() .
Then the calculation procedure is as follows:
.
Then the calculation procedure is as follows:
Start at ![]() :
:
Step at ![]() :
:
The next program calculates the smoothed state vectors for our SSF form, given the
estimated parameters
![]() . The smoothed series of the common price component is
given in Figure 13.3. The confidence intervals are calculated using the
variance of the first element of the state vector.
. The smoothed series of the common price component is
given in Figure 13.3. The confidence intervals are calculated using the
variance of the first element of the state vector.
![\includegraphics[width=1.5\defpicwidth]{XFGsssmdisplay4.ps}](xfghtmlimg2407.gif)
|
Comparison with the average prices given in Figure 13.1 reveals that the
common price component is less volatile than the simple average.
Furthermore, a table for the estimated hedonic coefficients--that is ![]() --is
generated, Table 13.4.
--is
generated, Table 13.4.
Recall that these coefficients are just the last three entries in the state vector
![]() . According to our state space model, the variances for these state variables are
zero. Thus, it is not surprising that the Kalman smoother produces constant estimates
through time for these coefficients. In the Appendix 13.6.2 we give a
formal proof of this intuitive result.
. According to our state space model, the variances for these state variables are
zero. Thus, it is not surprising that the Kalman smoother produces constant estimates
through time for these coefficients. In the Appendix 13.6.2 we give a
formal proof of this intuitive result.
The estimated coefficient of log lot size implies that, as expected, the size of the lot has an positive influence on the price. The estimated relative price increase for an one percent increase in the lot size is about 0.27%. The estimated effect of an increase in the floor space is even larger. Here, a one percent increase in the floor space lets the price soar by about 0.48%. Finally, note that the price of a houses is estimated to decrease with age.
![\begin{table}\begin{verbatim}[1,]''===========================================''...
...''
[9,] ''===========================================''\end{verbatim}\end{table}](xfghtmlimg2408.gif)