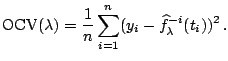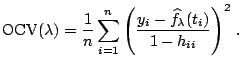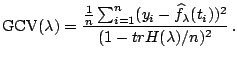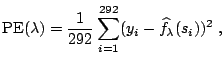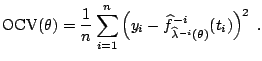The reason one cannot use the
![]() for model selection is that it
generally under-estimates the generalization error of a model
([16,25]). For example, (1.21) shows
that the RSS under-estimates the
for model selection is that it
generally under-estimates the generalization error of a model
([16,25]). For example, (1.21) shows
that the RSS under-estimates the
![]() by
by
![]() . Thus, similar to the correction term in the
. Thus, similar to the correction term in the
![]() , the
second term in the
, the
second term in the
![]() criterion
corrects this bias. The bias in RSS is a result of using the same data
for model fitting and model evaluation. Ideally, these two tasks
should be separated using independent samples. This can be achieved by
splitting the whole data into two subsamples, a training (calibration)
sample for model fitting and a test (validation) sample for model
evaluation. This approach, however, is not efficient unless the
sample size is large. The idea behind the cross-validation
is to recycle data by switching the roles of
training and test samples.
criterion
corrects this bias. The bias in RSS is a result of using the same data
for model fitting and model evaluation. Ideally, these two tasks
should be separated using independent samples. This can be achieved by
splitting the whole data into two subsamples, a training (calibration)
sample for model fitting and a test (validation) sample for model
evaluation. This approach, however, is not efficient unless the
sample size is large. The idea behind the cross-validation
is to recycle data by switching the roles of
training and test samples.
Suppose that one has decided on a measure of discrepancy for
model evaluation, for example the prediction error.
A ![]() -fold cross-validation selects a model as follows.
-fold cross-validation selects a model as follows.
The cross-validation is a general
procedure that can be applied to estimate tuning parameters in
a wide variety of problems. To be specific, we now consider
the regression model (1.2). For notational
simplicity, we consider the delete-1 (leave-one-out)
cross-validation with ![]() . Suppose our objective is
prediction. Let
. Suppose our objective is
prediction. Let
![]() be the
be the ![]() vector with the
vector with the
![]() th observation,
th observation, ![]() , removed from the original response
vector
, removed from the original response
vector
![]() . Let
. Let
![]() be the
estimate based on
be the
estimate based on ![]() observations
observations
![]() . The
ordinary cross-validation (OCV) estimate of the prediction
error is
. The
ordinary cross-validation (OCV) estimate of the prediction
error is
![$\displaystyle \notag \tilde{y}_{ij} = \left\{ \begin{array}{ll} y_j, & j \ne i , \\ [2mm] \widehat{f}_{\lambda}^{-i}(t_i), & j=i , \end{array}\right.$](img3444.gif) |
See [50] and [24] for proofs. Note that even though it is called the leaving-out-one lemma, similar results hold for the leaving-out-of-cluster cross-validation ([55]). See also [56], [59] and [33] for the leaving-out-one lemma for more complicated problems.
For trigonometric regression and periodic spline models,
![]() for
any
for
any
![]() . Thus when
. Thus when
![]() is replaced by
is replaced by
![]() , we have
, we have
![]() . Denote the elements of
. Denote the elements of
![]() as
as
![]() . Then
. Then
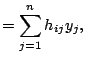 |
||
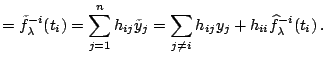 |
Replacing ![]() in (1.25) by the average of
all diagonal elements, [13] proposed the
following generalized cross-validation (GCV)
criterion
in (1.25) by the average of
all diagonal elements, [13] proposed the
following generalized cross-validation (GCV)
criterion
![$\displaystyle \notag \mathrm{GCV}(\lambda) \approx \frac{1}{n} \sum_{i=1}^n ( y...
...a) \left[ \frac{1}{n} \sum_{i=1}^n ( y_i-\widehat{f}_{\lambda}(t_i))^2 \right].$](img3467.gif) |
For the trigonometric regression,
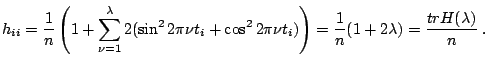 |
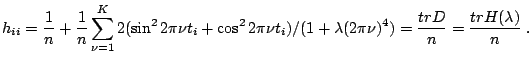 |
Instead of deleting one observation at a time, one may delete
![]() observations at a time as described in the V-fold
cross-validation. We will call such a method as delete-d CV.
[47] classified various model selection
criteria into the following three classes:
observations at a time as described in the V-fold
cross-validation. We will call such a method as delete-d CV.
[47] classified various model selection
criteria into the following three classes:
| Class 1: |
|
| Class 2: | Criterion (1.20) with
|
| Class 3: | Criterion (1.20) with a fixed |
![]() is a special case of the Class 2.
[47] showed that the criteria in Class 1 are
asymptotically valid if there is no fixed-dimensional correct
model and the criteria in Class 2 are asymptotically valid
when the opposite is true. Methods in Class 3 are compromises
of those in Classes 1 and 2. Roughly speaking, criteria in the
first class would perform better if the true model is
''complex'' and the criteria in the second class would do
better if the true model is ''simple''. See also
[60] and
[46].
is a special case of the Class 2.
[47] showed that the criteria in Class 1 are
asymptotically valid if there is no fixed-dimensional correct
model and the criteria in Class 2 are asymptotically valid
when the opposite is true. Methods in Class 3 are compromises
of those in Classes 1 and 2. Roughly speaking, criteria in the
first class would perform better if the true model is
''complex'' and the criteria in the second class would do
better if the true model is ''simple''. See also
[60] and
[46].
The climate data subset was selected by first dividing ![]() days in the year 1990 into
days in the year 1990 into ![]() five-day periods, and then
selecting measurements on the third day in each period as
observations. This is our training sample. Measurements
excluding these selected
five-day periods, and then
selecting measurements on the third day in each period as
observations. This is our training sample. Measurements
excluding these selected ![]() days may be used as the test
sample. This test sample consists
days may be used as the test
sample. This test sample consists
![]() observations. For the trigonometric model with fixed frequency
observations. For the trigonometric model with fixed frequency
![]() , we calculate the prediction error using the test
sample
, we calculate the prediction error using the test
sample
![\includegraphics[width=11.7cm]{text/3-1/cv.eps}](img3478.gif) |
As a general methodology, the cross-validation may also be
used to select ![]() in (1.20)
([43]). Let
in (1.20)
([43]). Let
![]() be the estimate
based on the delete-one data
be the estimate
based on the delete-one data
![]() where
where
![]() is selected
using (1.20), also based on
is selected
using (1.20), also based on
![]() . Then the OCV estimate of prediction error is
. Then the OCV estimate of prediction error is