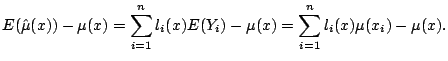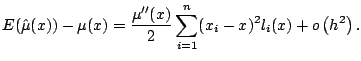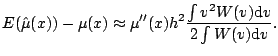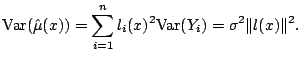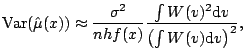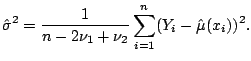Each of the smoothing methods discussed in the previous section has
one or more `smoothing parameters'
that control the amount of smoothing being performed. For example, the
bandwidth ![]() in the kernel smoother or local regression methods, and the
parameter
in the kernel smoother or local regression methods, and the
parameter ![]() in the penalized likelihood criterion. In
implementing the smoothers, the first question to be asked is how
should the smoothing parameters be chosen? More generally, how can the
performance of a smoother with given smoothing parameters be assessed?
A deeper question is in comparing fits from different smoothers. For
example, we have seen for the fuel economy dataset that a local linear
fit with
in the penalized likelihood criterion. In
implementing the smoothers, the first question to be asked is how
should the smoothing parameters be chosen? More generally, how can the
performance of a smoother with given smoothing parameters be assessed?
A deeper question is in comparing fits from different smoothers. For
example, we have seen for the fuel economy dataset that a local linear
fit with ![]() (Fig. 5.2) produces a fit similar to
a smoothing spline with
(Fig. 5.2) produces a fit similar to
a smoothing spline with
![]() (Fig. 5.3). Somehow, we want to be able to say these two
smoothing parameters are equivalent.
(Fig. 5.3). Somehow, we want to be able to say these two
smoothing parameters are equivalent.
As a prelude to studying methods for bandwidth selection and other statistical inference procedures, we must first study some of the properties of linear smoothers. We can consider measures of goodness-of-fit, such as the mean squared error,
Intuitively, as the bandwidth ![]() increases, more data is used to
construct the estimate
increases, more data is used to
construct the estimate
![]() , and so the variance
, and so the variance
![]() decreases. On the other hand, the local
polynomial approximation
is best over small intervals, so we expect the bias to increase as the
bandwidth increases. Choosing
decreases. On the other hand, the local
polynomial approximation
is best over small intervals, so we expect the bias to increase as the
bandwidth increases. Choosing ![]() is a tradeoff between small bias and
small variance,
but we need more precise characterizations to derive and study
selection procedures.
is a tradeoff between small bias and
small variance,
but we need more precise characterizations to derive and study
selection procedures.
The bias of a linear smoother is given by
For illustration, consider the bias of the local linear regression estimate defined by (5.6). A three-term Taylor series gives
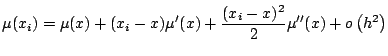 |
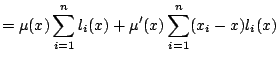 |
||
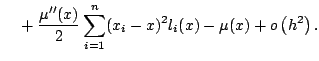 |
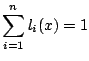 |
|
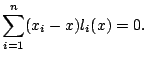 |
The next step is to approximate summations by integrals, both
in (5.12) and in the matrix equation (5.9) defining
![]() . This leads to
. This leads to
Bias expansions like (5.13) are derived much more generally
by [25]; their results cover arbitrary degree local
polynomials and multidimensional fits also. Their results imply that
when ![]() , the degree of the local polynomial, is odd, the dominant
term of the bias is proportional to
, the degree of the local polynomial, is odd, the dominant
term of the bias is proportional to
![]() . When
. When ![]() is even, the first-order term can disappear, leading to bias of
order
is even, the first-order term can disappear, leading to bias of
order ![]() .
.
To derive the variance of a linear smoother, we need to make
assumptions about the random errors
![]() in (5.1).
The most common assumption is that the errors are independent and
identically distributed, with variance
in (5.1).
The most common assumption is that the errors are independent and
identically distributed, with variance
![]() .
The variance of a linear smoother (5.3) is
.
The variance of a linear smoother (5.3) is
As with bias, informative approximations to the variance can be derived by replacing sums by integrals. For local linear regression, this leads to
Under the model (5.1) the observation ![]() has
variance
has
variance ![]() , while the estimate
, while the estimate
![]() has variance
has variance
![]() . The quantity
. The quantity
![]() measures the
variance reduction of the smoother at a data point
measures the
variance reduction of the smoother at a data point ![]() . At one
extreme, if the `smoother' interpolates the data, then
. At one
extreme, if the `smoother' interpolates the data, then
![]() and
and
![]() . At the other extreme, if
. At the other extreme, if
![]() ,
,
![]() . Under mild conditions on the weight
function, a local polynomial smoother satisfies
. Under mild conditions on the weight
function, a local polynomial smoother satisfies
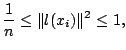 |
A global measure of the amount of smoothing is provided by
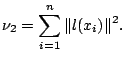 |
An alternative representation of ![]() is as follows. Let
is as follows. Let
![]() be the `hat matrix',
which maps the data to fitted values:
be the `hat matrix',
which maps the data to fitted values:
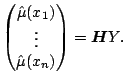 |
The diagonal elements of
![]() ,
, ![]() provide another
measure of the amount of smoothing at
provide another
measure of the amount of smoothing at ![]() . If the smooth
interpolates the data, then
. If the smooth
interpolates the data, then ![]() is the corresponding unit vector
with
is the corresponding unit vector
with
![]() . If the smooth is simply the global average,
. If the smooth is simply the global average,
![]() . The corresponding definition of degrees of freedom
is
. The corresponding definition of degrees of freedom
is
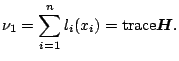 |
For the local linear regression in Fig. 5.2, the degrees
of freedom are
![]() and
and
![]() . For the
smoothing spline smoother in Fig. 5.3,
. For the
smoothing spline smoother in Fig. 5.3,
![]() and
and
![]() . By either measure the degrees of
freedom are similar for the two fits. The degrees of freedom provides
a mechanism by which different smoothers, with different smoothing
parameters, can be compared: we simply choose smoothing parameters
producing the same number of degrees of freedom. More extensive
discussion of the degrees of freedom of a smoother can be found in
[5] and [14].
. By either measure the degrees of
freedom are similar for the two fits. The degrees of freedom provides
a mechanism by which different smoothers, with different smoothing
parameters, can be compared: we simply choose smoothing parameters
producing the same number of degrees of freedom. More extensive
discussion of the degrees of freedom of a smoother can be found in
[5] and [14].
The final component needed for many statistical procedures is an
estimate of the error variance ![]() . One such estimate is
. One such estimate is