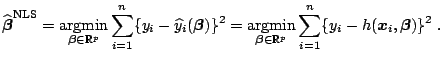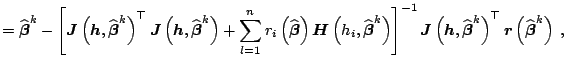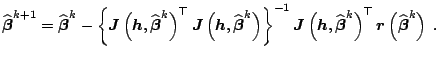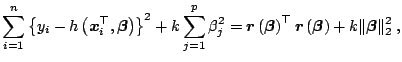In this section, we study the nonlinear regression model
We first discuss the fitting and inference in the nonlinear regression (Sects. 8.2.1 and 8.2.2), whereby we again concentrate on the least square estimation. For an extensive discussion of theory and practice of nonlinear least squares regression see monographs [3], [8] and [80]. Second, similarly to the linear modeling section, methods for ill-conditioned nonlinear systems are briefly reviewed in Sect. 8.2.3.
In this section, we concentrate on estimating the vector
![]() of unknown parameters in (8.16) by
nonlinear least squares.
of unknown parameters in (8.16) by
nonlinear least squares.
Contrary to the linear model fitting, we cannot express analytically
the solution of this optimization problem for a general
function ![]() . On the other hand, we can try to approximate the
nonlinear objective function using the Taylor expansion because the
existence of the first two derivatives of
. On the other hand, we can try to approximate the
nonlinear objective function using the Taylor expansion because the
existence of the first two derivatives of ![]() is an often used
condition for the asymptotic normality of
is an often used
condition for the asymptotic normality of
![]() , and thus, could be
readily assumed. Denoting
, and thus, could be
readily assumed. Denoting
![]() and
and
![]() , we
can state the following theorem from [4].
, we
can state the following theorem from [4].
Hence, although there is no general explicit solution
to (8.17), we can assume without loss of much generality
that the objective function
![]() is twice differentiable in
order to devise a numerical optimization algorithm. The second-order
Taylor expansion provides then a quadratic approximation of the
minimized function, which can be used for obtaining an approximate
minimum of the function, see [3]. As a result, one
should search in the direction of the steepest descent of a function,
which is given by its gradient, to get a better approximation of the
minimum. We discuss here the incarnations of these methods
specifically for the case of quadratic loss function
in (8.17).
is twice differentiable in
order to devise a numerical optimization algorithm. The second-order
Taylor expansion provides then a quadratic approximation of the
minimized function, which can be used for obtaining an approximate
minimum of the function, see [3]. As a result, one
should search in the direction of the steepest descent of a function,
which is given by its gradient, to get a better approximation of the
minimum. We discuss here the incarnations of these methods
specifically for the case of quadratic loss function
in (8.17).
The classical method based on the gradient approach is Newton's
method, see [54] and [3] for detailed
discussion. Starting from an initial point
![]() , a better
approximation is found by taking
, a better
approximation is found by taking
To find
![]() , (8.19) is iterated until convergence is
achieved. This is often verified by checking whether the relative
change from
, (8.19) is iterated until convergence is
achieved. This is often verified by checking whether the relative
change from
![]() to
to
![]() is sufficiently
small. Unfortunately, this criterion can indicate a lack of progress
rather than convergence. Instead, [8] proposed to check
convergence by looking at some measure of orthogonality of residuals
is sufficiently
small. Unfortunately, this criterion can indicate a lack of progress
rather than convergence. Instead, [8] proposed to check
convergence by looking at some measure of orthogonality of residuals
![]() towards the regression surface given by
towards the regression surface given by
![]() ,
since the identification assumption of model (8.16) is
,
since the identification assumption of model (8.16) is
![]() . See [13],
[54] and [92] for more details and further
modifications.
. See [13],
[54] and [92] for more details and further
modifications.
To evaluate iteration (8.19), it is necessary to invert the
Hessian matrix
![]() . From the computational point of
view, all issues discussed in Sect. 8.1 apply here too and
one should use a numerically stable procedure, such as QR or SVD
decompositions, to perform the inversion. Moreover, to guarantee
that (8.19) leads to a better approximation of the minimum,
that is
. From the computational point of
view, all issues discussed in Sect. 8.1 apply here too and
one should use a numerically stable procedure, such as QR or SVD
decompositions, to perform the inversion. Moreover, to guarantee
that (8.19) leads to a better approximation of the minimum,
that is
![]() , the Hessian matrix
, the Hessian matrix
![]() needs to be positive definite, which in
general holds only in a neighborhood of
needs to be positive definite, which in
general holds only in a neighborhood of
![]() (see the
Levenberg-Marquardt
method for a remedy). Even if it is so, the step in the gradient
direction should not be too long, otherwise we ''overshoot.''
Modified Newton's method addresses this by using some fraction
(see the
Levenberg-Marquardt
method for a remedy). Even if it is so, the step in the gradient
direction should not be too long, otherwise we ''overshoot.''
Modified Newton's method addresses this by using some fraction
![]() of iteration step
of iteration step
![]() . See [12],
[31] and [54] for some choices of
. See [12],
[31] and [54] for some choices of
![]() .
.
The Gauss-Newton method is designed specifically for
![]() by replacing
the regression function
by replacing
the regression function
![]() in (8.17) by its
first-order Taylor expansion. The resulting iteration step is
in (8.17) by its
first-order Taylor expansion. The resulting iteration step is
Depending on data and the current approximation
![]() of
of
![]() , the Hessian matrix
, the Hessian matrix
![]() or its approximations
such as
or its approximations
such as
![]() can be
badly conditioned or not positive definite, which could even result in
divergence of Newton's method (or a very slow convergence in the case
of modified Newton's method). The Levenberg-Marquardt method addresses
the ill-conditioning by choosing the search direction
can be
badly conditioned or not positive definite, which could even result in
divergence of Newton's method (or a very slow convergence in the case
of modified Newton's method). The Levenberg-Marquardt method addresses
the ill-conditioning by choosing the search direction
![]() as a solution of
as a solution of
Although Newton's method and its modifications are most frequently used in applications, the fact that they find local minima gives rise to various improvements and alternative methods. They range from simple starting the minimization algorithm from several (randomly chosen) initial points to general global-search optimization methods such as genetic algorithms mentioned in Sect. 8.1.3 and discussed in more details in Chaps. II.5 and II.6.
Similarly to linear modeling, the inference in nonlinear regression
models is mainly based, besides the estimate
![]() itself, on two quantities: the residual
sum of squares
itself, on two quantities: the residual
sum of squares
![]() and the
(asymptotic) variance of the estimate
and the
(asymptotic) variance of the estimate
![]() , see (8.18). Here we discuss how to compute
these quantities for
, see (8.18). Here we discuss how to compute
these quantities for
![]() and its functions.
and its functions.
![]() will be typically a by-product of a numerical computation
procedure, since it constitutes the minimized function.
will be typically a by-product of a numerical computation
procedure, since it constitutes the minimized function.
![]() also
provides an estimate of
also
provides an estimate of ![]() :
:
![]() . The same also
holds for the matrix
. The same also
holds for the matrix
![]() , which can be consistently estimated
by
, which can be consistently estimated
by
![]() ,
that is, by the asymptotic representation of the Hessian matrix
,
that is, by the asymptotic representation of the Hessian matrix
![]() . This matrix or its approximations are
computed at every step of (quasi-)Newton methods for
. This matrix or its approximations are
computed at every step of (quasi-)Newton methods for
![]() , and thus, it
will be readily available after the estimation.
, and thus, it
will be readily available after the estimation.
Furthermore, the inference in nonlinear regression models may often
involve a nonlinear (vector) function of the estimate
![]() ;
for example, when we test a hypothesis (see [3], for
a discussion of
;
for example, when we test a hypothesis (see [3], for
a discussion of
![]() hypothesis testing). Contrary to linear functions
of estimates, where
hypothesis testing). Contrary to linear functions
of estimates, where
![]() , there is no exact expression
for
, there is no exact expression
for
![]() in a general case. Thus, we usually assume
the first-order differentiability of
in a general case. Thus, we usually assume
the first-order differentiability of
![]() and use the Taylor
expansion to approximate this variance. Since
and use the Taylor
expansion to approximate this variance. Since
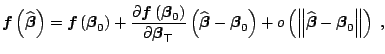 |
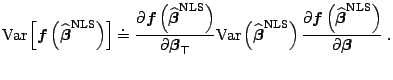 |
Similarly to linear modeling, the nonlinear models can also be
ill-conditioned when the Hessian matrix
![]() is nearly
singular or does not even have a full rank, see
Sect. 8.1.2. This can be caused either by the nonlinear
regression function
is nearly
singular or does not even have a full rank, see
Sect. 8.1.2. This can be caused either by the nonlinear
regression function ![]() itself or by too many explanatory variables
relative to sample size
itself or by too many explanatory variables
relative to sample size ![]() . Here we mention extensions of methods
dealing with ill-conditioned problems in the case of linear models
(discussed in Sects. 8.1.5-8.1.9) to nonlinear
modeling: ridge regression, Stein-rule estimator, Lasso, and partial
least squares.
. Here we mention extensions of methods
dealing with ill-conditioned problems in the case of linear models
(discussed in Sects. 8.1.5-8.1.9) to nonlinear
modeling: ridge regression, Stein-rule estimator, Lasso, and partial
least squares.
First, one of early nonlinear
![]() was proposed by [21], who
simply added a diagonal matrix to
was proposed by [21], who
simply added a diagonal matrix to
![]() in (8.19). Since the nonlinear modeling is done by
minimizing of an objective function, a more straightforward way is to
use the alternative formulation (8.11) of
in (8.19). Since the nonlinear modeling is done by
minimizing of an objective function, a more straightforward way is to
use the alternative formulation (8.11) of
![]() and to
minimize
and to
minimize
Next, equally straightforward is an application of Stein-rule
estimator (8.8) in nonlinear regression, see
[56] for a recent study of positive-part Stein-rule
estimator within the Box-Cox model. The same could possibly apply to
Lasso-type estimators discussed in Sect. 8.1.8 as well: the
Euclidian norm
![]() in (8.22) would just have
to be replaced by another
in (8.22) would just have
to be replaced by another ![]() norm. Nevertheless, the behavior of
Lasso within linear regression has only recently been studied in more
details, and to my best knowledge, there are no results on Lasso in
nonlinear models yet.
norm. Nevertheless, the behavior of
Lasso within linear regression has only recently been studied in more
details, and to my best knowledge, there are no results on Lasso in
nonlinear models yet.
Finally, there is a range of modifications of
![]() designed for
nonlinear regression
modeling, which either try to make the relationship between dependent
and expl variables linear in unknown parameters or deploy an
intrinsically nonlinear model. First, the methods using linearization
are typically based on approximating a nonlinear relationship by
higher-order polynomials (see quadratic
designed for
nonlinear regression
modeling, which either try to make the relationship between dependent
and expl variables linear in unknown parameters or deploy an
intrinsically nonlinear model. First, the methods using linearization
are typically based on approximating a nonlinear relationship by
higher-order polynomials (see quadratic
![]() by [107], and INLR
approach by [10]) or a piecewise constant approximation
(GIFI approach, see [11]). [108] present an
overview of these methods. Second, several recent works introduced
intrinsic nonlinearity into
by [107], and INLR
approach by [10]) or a piecewise constant approximation
(GIFI approach, see [11]). [108] present an
overview of these methods. Second, several recent works introduced
intrinsic nonlinearity into
![]() modeling. Among most important
contributions, there are [77] and [64] modeling the
nonlinear relationship using a forward-feed neural network,
[106] and [25] transforming predictors by
spline functions, and [5] using fuzzy-clustering
regression approach.
modeling. Among most important
contributions, there are [77] and [64] modeling the
nonlinear relationship using a forward-feed neural network,
[106] and [25] transforming predictors by
spline functions, and [5] using fuzzy-clustering
regression approach.