Direct methods for solving linear systems theoretically give the exact solution in a finite number of steps, see Sect. 4.2. Unfortunately, this is rarely true in applications because of rounding errors: an error made in one step spreads further in all following steps! Contrary to direct methods, iterative methods construct a series of solution approximations such that it converges to the exact solution of a system. Their main advantage is that they are self-correcting, see Sect. 4.3.1.
In this section, we first discuss general principles of iterative
methods that solve linear system (4.6),
![]() ,
whereby we assume that
,
whereby we assume that
![]() and the system has
exactly one solution
and the system has
exactly one solution
![]() (see Sect. 4.2 for more
details on other cases). Later, we describe most common iterative
methods: the Jacobi, Gauss-Seidel, successive overrelaxation, and
gradient methods (Sects. 4.3.2-4.3.5).
Monographs containing detailed discussion of these methods include
[7,24] and [27]. Although we
treat these methods separately from the direct methods, let us mention
here that iterative methods can usually benefit from a combination
with the Gauss elimination, see [46] and
[1], for instance.
(see Sect. 4.2 for more
details on other cases). Later, we describe most common iterative
methods: the Jacobi, Gauss-Seidel, successive overrelaxation, and
gradient methods (Sects. 4.3.2-4.3.5).
Monographs containing detailed discussion of these methods include
[7,24] and [27]. Although we
treat these methods separately from the direct methods, let us mention
here that iterative methods can usually benefit from a combination
with the Gauss elimination, see [46] and
[1], for instance.
To unify the presentation of all methods, let
![]() ,
,
![]() , and
, and
![]() denote the diagonal, lower triangular and upper triangular parts of
a matrix
denote the diagonal, lower triangular and upper triangular parts of
a matrix
![]() throughout this section:
throughout this section:
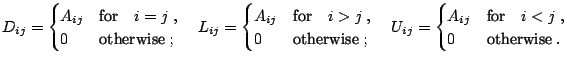 |
An iterative method for solving a linear system
![]() constructs an iteration series
constructs an iteration series
![]() ,
,
![]() , that under
some conditions converges to the exact solution
, that under
some conditions converges to the exact solution
![]() of the system
(
of the system
(
![]() ). Thus, it is necessary to choose a starting
point
). Thus, it is necessary to choose a starting
point
![]() and iteratively apply a rule that computes
and iteratively apply a rule that computes
![]() from an already known
from an already known
![]() .
.
A starting vector
![]() is usually chosen as some approximation
of
is usually chosen as some approximation
of
![]() . (Luckily, its choice cannot cause divergence of
a convergent method.) Next, given
. (Luckily, its choice cannot cause divergence of
a convergent method.) Next, given
![]() , the subsequent
element of the series is computed using a rule of the form
, the subsequent
element of the series is computed using a rule of the form
Let us discuss now a minimal set of conditions on
![]() and
and
![]() in (4.8) that guarantee the convergence of an
iterative method. First of all, it has to hold that
in (4.8) that guarantee the convergence of an
iterative method. First of all, it has to hold that
![]() for all
for all
![]() , or equivalently,
, or equivalently,
In praxis, stationary iterative methods are used, that is, methods
with constant
![]() and
and
![]() ,
,
![]() . Consequently, an iteration series is then constructed using
. Consequently, an iteration series is then constructed using
Note that the convergence condition
![]() holds, for
example, if
holds, for
example, if
![]() in any matrix norm. Moreover,
Theorem 7 guarantees the self-correcting property
of iterative methods since convergence takes place independent of the
starting value
in any matrix norm. Moreover,
Theorem 7 guarantees the self-correcting property
of iterative methods since convergence takes place independent of the
starting value
![]() . Thus, if computational errors adversely affect
. Thus, if computational errors adversely affect
![]() during the
during the ![]() th iteration,
th iteration,
![]() can be considered as a new
starting vector and the iterative method will further
converge. Consequently, the iterative methods are in general more
robust than the direct ones.
can be considered as a new
starting vector and the iterative method will further
converge. Consequently, the iterative methods are in general more
robust than the direct ones.
Apparently, such an iterative process can continue arbitrarily long
unless
![]() at some point. This is impractical and usually
unnecessary. Therefore, one uses stopping (or convergence) criteria
that stop the iterative process when a pre-specified condition is
met. Commonly used stopping criteria are based on the change of the
solution or residual vector achieved during one
iteration. Specifically, given a small
at some point. This is impractical and usually
unnecessary. Therefore, one uses stopping (or convergence) criteria
that stop the iterative process when a pre-specified condition is
met. Commonly used stopping criteria are based on the change of the
solution or residual vector achieved during one
iteration. Specifically, given a small
![]() , the
iterative process is stopped after the
, the
iterative process is stopped after the ![]() th iteration when
th iteration when
![]() ,
,
![]() , or
, or
![]() , where
, where
![]() is a residual vector. Additionally, a maximum acceptable
number of iterations is usually specified.
is a residual vector. Additionally, a maximum acceptable
number of iterations is usually specified.
The Jacobi method is motivated by the following observation. Let
![]() have nonzero diagonal elements (the rows of any nonsingular
matrix can be reorganized to achieve this). Then the diagonal part
have nonzero diagonal elements (the rows of any nonsingular
matrix can be reorganized to achieve this). Then the diagonal part
![]() of
of
![]() is nonsingular and the system (4.6) can be
rewritten as
is nonsingular and the system (4.6) can be
rewritten as
![]() . Consequently,
. Consequently,
The intuition of the Jacobi method is very simple: given an
approximation
![]() of the solution, let us express the
of the solution, let us express the
![]() th component
th component ![]() of
of
![]() as a function of the other components
from the
as a function of the other components
from the ![]() th equation and compute
th equation and compute ![]() given
given
![]() :
:
The Jacobi method converges for any starting vector
![]() as long as
as long as
![]() , see
Theorem 7. This condition is satisfied for
a relatively big class of matrices including diagonally dominant
matrices (matrices
, see
Theorem 7. This condition is satisfied for
a relatively big class of matrices including diagonally dominant
matrices (matrices
![]() such that
such that
![]() for
for
![]() ), and symmetric matrices
), and symmetric matrices
![]() such that
such that
![]() ,
,
![]() , and
, and
![]() are all positive
definite. Although there are many improvements to the basic principle
of the Jacobi method in terms of convergence to
are all positive
definite. Although there are many improvements to the basic principle
of the Jacobi method in terms of convergence to
![]() , see
Sects. 4.3.3 and 4.3.4, its advantage is an
easy and fast implementation (elements of a new iteration
, see
Sects. 4.3.3 and 4.3.4, its advantage is an
easy and fast implementation (elements of a new iteration
![]() can
be computed independently of each other).
can
be computed independently of each other).
Analogously to the Jacobi method, we can rewrite
system (4.6) as
![]() , which
further implies
, which
further implies
![]() . This leads to
the iteration formula of the Gauss-Seidel method:
. This leads to
the iteration formula of the Gauss-Seidel method:
Following the Theorem 7, the Gauss-Seidel method
converges for any starting vector
![]() if
if
![]() . This condition holds, for example, for diagonally dominant
matrices as well as for positive definite ones.
. This condition holds, for example, for diagonally dominant
matrices as well as for positive definite ones.
The successive overrelaxation (SOR) method aims to further refine the Gauss-Seidel method. The Gauss-Seidel formula (4.12) can be rewritten as
A good choice of parameter ![]() can speed up convergence, as
measured by the spectral radius of the corresponding iteration matrix
can speed up convergence, as
measured by the spectral radius of the corresponding iteration matrix
![]() (see Theorem 7; a lower spectral radius
(see Theorem 7; a lower spectral radius
![]() means faster convergence). There is a choice of literature
devoted to the optimal setting of relaxation parameter: see
[28] for a recent overview of the main results concerning
SOR. We just present one important result, which is due to
[66].
means faster convergence). There is a choice of literature
devoted to the optimal setting of relaxation parameter: see
[28] for a recent overview of the main results concerning
SOR. We just present one important result, which is due to
[66].
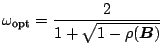 |
Using SOR with the optimal relaxation parameter significantly
increases the rate of convergence. Note however that the convergence
acceleration is obtained only for ![]() very close to
very close to
![]() . If
. If
![]() cannot be computed
exactly, it is better to take
cannot be computed
exactly, it is better to take ![]() slightly larger rather than
smaller. [24] describe an approximation algorithm
for
slightly larger rather than
smaller. [24] describe an approximation algorithm
for
![]() .
.
On the other hand, if the assumptions of Theorem 8 are not
satisfied, one can employ the symmetric SOR (SSOR), which performs the
SOR iteration twice: once as usual, see (4.13), and once
with interchanged
![]() and
and
![]() . SSOR requires more computations
per iteration and usually converges slower, but it works for any
positive definite matrix and can be combined with various acceleration
techniques. See [7] and [28] for details.
. SSOR requires more computations
per iteration and usually converges slower, but it works for any
positive definite matrix and can be combined with various acceleration
techniques. See [7] and [28] for details.
Gradient iterative methods are based on the assumption that
![]() is
a symmetric positive definite matrix
is
a symmetric positive definite matrix
![]() . They use this assumption
to reformulate (4.6) as a minimization problem:
. They use this assumption
to reformulate (4.6) as a minimization problem:
![]() is
the only minimum of the quadratic form
is
the only minimum of the quadratic form
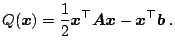 |
Given this minimization problem, gradient methods construct an
iteration series of vectors converging to
![]() using the following
principle. Having the
using the following
principle. Having the ![]() th approximation
th approximation
![]() , choose a direction
, choose a direction
![]() and find a number
and find a number ![]() such that the new vector
such that the new vector
Interestingly, the Gauss-Seidel method can be seen as a gradient method for the choice
The steepest descent method is based on the direction
![]() given by
the gradient of
given by
the gradient of
![]() at
at
![]() . Denoting the residuum of the
. Denoting the residuum of the
![]() th approximation
th approximation
![]() , the iteration formula is
, the iteration formula is
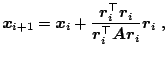 |
In the conjugate gradient (CG) method proposed by [33],
the directions
![]() are generated by the
are generated by the
![]() -orthogonalization of
residuum vectors. Given a symmetric positive definite matrix
-orthogonalization of
residuum vectors. Given a symmetric positive definite matrix
![]() ,
,
![]() -orthogonalization is a procedure that constructs a series of
linearly independent vectors
-orthogonalization is a procedure that constructs a series of
linearly independent vectors
![]() such that
such that
![]() for
for ![]() (conjugacy or
(conjugacy or
![]() -orthogonality condition). It
can be used to solve the system (4.6) as follows (
-orthogonality condition). It
can be used to solve the system (4.6) as follows (
![]() represents residuals).
represents residuals).
do
until a stop criterion holds
An interesting theoretic property of CG is that it reaches the exact
solution in at most ![]() steps because there are not more than
steps because there are not more than ![]() (
(
![]() -)orthogonal vectors. Thus, CG is not a truly iterative
method. (This does not have to be the case if
-)orthogonal vectors. Thus, CG is not a truly iterative
method. (This does not have to be the case if
![]() is a singular or
non-square matrix, see [42].) On the other hand, it is
usually used as an iterative method, because it can give a solution
within the given accuracy much earlier than after
is a singular or
non-square matrix, see [42].) On the other hand, it is
usually used as an iterative method, because it can give a solution
within the given accuracy much earlier than after ![]() iterations. Moreover, if the approximate solution
iterations. Moreover, if the approximate solution
![]() after
after ![]() iterations is not accurate enough (due to computational errors), the
algorithm can be restarted with
iterations is not accurate enough (due to computational errors), the
algorithm can be restarted with
![]() set to
set to
![]() . Finally, let
us note that CG is attractive for use with large sparse matrices
because it addresses
. Finally, let
us note that CG is attractive for use with large sparse matrices
because it addresses
![]() only by its multiplication by
a vector. This operation can be done very efficiently for a properly
stored sparse matrix, see Sect. 4.5.
only by its multiplication by
a vector. This operation can be done very efficiently for a properly
stored sparse matrix, see Sect. 4.5.
The principle of CG has many extensions that are applicable also for nonsymmetric nonsingular matrices: for example, generalized minimal residual, [55]; (stabilized) biconjugate gradients, [64]; or quasi-minimal residual, [13].
![\includegraphics[width=6cm]{text/2-4/jacobi}](img1680.gif)
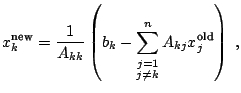
![\includegraphics[width=6cm]{text/2-4/gs}](img1696.gif)