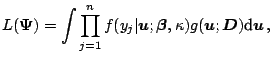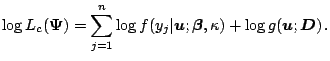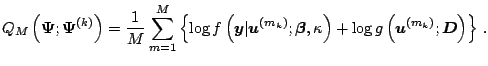In this section, further modifications and extensions to the EM algorithm are considered. In general, there are extensions of the EM algorithm
In some applications of the EM algorithm, the E-step is complex and
does not admit a close-form solution to the ![]() -function. In
this case, the E-step at the
-function. In
this case, the E-step at the ![]() th iteration may be executed
by a Monte Carlo (MC) process:
th iteration may be executed
by a Monte Carlo (MC) process:
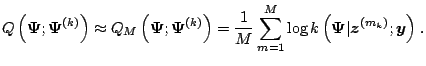 |
Generalized linear mixed models (GLMM) are extensions of generalized
linear models (GLM) (McCullagh and Nelder, 1989) that incorporate
random effects in the linear predictor of the GLM (more material on
the GLM can be found in Chap. III.7). We let
![]() denote the observed data
vector. Conditional on the unobservable random effects vector,
denote the observed data
vector. Conditional on the unobservable random effects vector,
![]() , we assume that
, we assume that
![]() arise from a GLM. The conditional mean
arise from a GLM. The conditional mean
![]() is
related to the linear predictor
is
related to the linear predictor
![]() by the link function
by the link function
![]() , where
, where
![]() is a
is a
![]() -vector of fixed effects and
-vector of fixed effects and
![]() and
and
![]() are,
respectively,
are,
respectively, ![]() -vector and
-vector and ![]() -vector of explanatory variables
associated with the fixed and random effects. This formulation
encompasses the modeling of data involving multiple sources of random
error, such as repeated measures within subjects and clustered data
collected from some experimental units (Breslow and Clayton, 1993).
-vector of explanatory variables
associated with the fixed and random effects. This formulation
encompasses the modeling of data involving multiple sources of random
error, such as repeated measures within subjects and clustered data
collected from some experimental units (Breslow and Clayton, 1993).
We let the distribution for
![]() be
be
![]() that depends on parameters
that depends on parameters
![]() . The observed data
. The observed data
![]() are conditionally independent with density functions of
the form
are conditionally independent with density functions of
the form
Within the EM framework, the random effects are considered as missing
data. The complete data is then
![]() and the
complete-data log likelihood is given by
and the
complete-data log likelihood is given by
From (5.26), it can be seen that the first term of the
approximated ![]() -function involves only parameters
-function involves only parameters
![]() and
and
![]() , while the second term involves only
, while the second term involves only
![]() . Thus, the
maximization in the MC M-step is usually relatively simple within the
GLMM context (McCulloch, 1997).
. Thus, the
maximization in the MC M-step is usually relatively simple within the
GLMM context (McCulloch, 1997).
Alternative simulation schemes for
![]() can be used for
(5.26). For example, Booth and Hobert (1999) proposed
the rejection sampling and a multivariate
can be used for
(5.26). For example, Booth and Hobert (1999) proposed
the rejection sampling and a multivariate ![]() importance sampling
approximations. McCulloch (1997) considered dependent MC samples using
MC Newton-Raphson (MCNR) algorithm.
importance sampling
approximations. McCulloch (1997) considered dependent MC samples using
MC Newton-Raphson (MCNR) algorithm.
One of major reasons for the popularity of the EM algorithm is that the M-step involves only complete-data ML estimation, which is often computationally simple. But if the complete-data ML estimation is rather complicated, then the EM algorithm is less attractive. In many cases, however, complete-data ML estimation is relatively simple if maximization process on the M-step is undertaken conditional on some functions of the parameters under estimation. To this end, Meng and Rubin (1993) introduce a class of GEM algorithms, which they call the Expectation-Conditional Maximization (ECM) algorithm.
A CM-step might be in closed form or it might itself require iteration, but because the CM maximizations are over smaller dimensional spaces, often they are simpler, faster, and more stable than the corresponding full maximizations called for on the M-step of the EM algorithm, especially when iteration is required. The ECM algorithm typically converges more slowly than the EM in terms of number of iterations, but can be faster in total computer time. More importantly, the ECM algorithm preserves the appealing convergence properties of the EM algorithm, such as its monotone convergence.
We suppose that the M-step is
replaced by ![]() steps and let
steps and let
![]() denote the value of
denote the value of
![]() on the
on the ![]() th CM-step of the
th CM-step of the ![]() th iteration.
In many applications of the ECM algorithm, the
th iteration.
In many applications of the ECM algorithm, the ![]() CM-steps correspond to
the situation where the parameter vector
CM-steps correspond to
the situation where the parameter vector
![]() is
partitioned into
is
partitioned into ![]() subvectors,
subvectors,
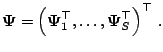 |
In many cases, the computation of an E-step may be much cheaper than
the computation of the CM-steps. Hence one might wish to perform one
E-step before each CM-step.
A cycle is defined to be one E-step
followed by one CM-step.
The corresponding algorithm is called the multicycle ECM
(Meng and Rubin, 1993).
A multicycle ECM may not necessarily be a GEM algorithm;
that is, the inequality (5.27) may not be hold.
However, it is not difficult to show that
the multicycle ECM algorithm monotonically increases the likelihood
function
![]() after each cycle, and hence, after each iteration.
The convergence results of the ECM algorithm apply to a multicycle version
of it. An obvious disadvantage of using a multicycle ECM algorithm is the extra
computation at each iteration. Intuitively, as a tradeoff, one might
expect it to result in larger increases in the log likelihood function per
iteration since the
after each cycle, and hence, after each iteration.
The convergence results of the ECM algorithm apply to a multicycle version
of it. An obvious disadvantage of using a multicycle ECM algorithm is the extra
computation at each iteration. Intuitively, as a tradeoff, one might
expect it to result in larger increases in the log likelihood function per
iteration since the ![]() -function is being updated more often
(Meng, 1994; Meng and Rubin, 1993).
-function is being updated more often
(Meng, 1994; Meng and Rubin, 1993).
The factor analysis model (5.29) can be fitted by the
EM algorithm and its variants. The MLE of the mean
![]() is
obviously the sample mean
is
obviously the sample mean
![]() of the
of the ![]() observed values
observed values
![]() corresponding to the random
sample
corresponding to the random
sample
![]() . Hence in the sequel,
. Hence in the sequel,
![]() can be set equal to
can be set equal to
![]() without loss of
generality. The log likelihood for
without loss of
generality. The log likelihood for
![]() that can be formed
from the observed data
that can be formed
from the observed data
![]() is, apart from an additive constant,
is, apart from an additive constant,
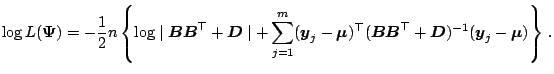 |
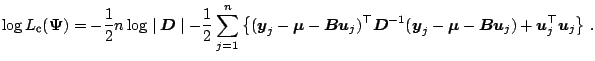 |
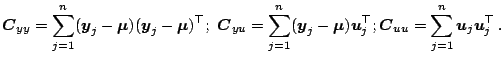 |
E-Step: Compute the conditional
expectation of the sufficient statistics given
![]() and the
current fit
and the
current fit
![]() for
for
![]() :
:
and
where
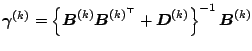 and and |
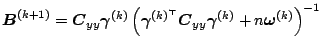 and
and
It is noted that direct differentiation of
![]() shows that
the ML estimate of the diagonal matrix
shows that
the ML estimate of the diagonal matrix
![]() satisfies
satisfies
The single-factor analysis model provides only a global linear model for
the representation of the data in a lower-dimensional subspace, the
scope of its application is limited. A global nonlinear approach can be
obtained by postulating a mixture of linear submodels for the
distribution of the full observation vector
![]() given the
(unobservable) factors
given the
(unobservable) factors
![]() (McLachlan et al., 2003). This mixture of
factor analyzers has been adopted both (a) for model-based density
estimation from high-dimensional data, and hence for the clutering of
such data, and (b) for local dimensionality reduction; see for example
McLachlan and Peel (2000, Chap. 8).
Some more material on dimension reduction
methods can be found in Chap. III.6 of this handbook.
(McLachlan et al., 2003). This mixture of
factor analyzers has been adopted both (a) for model-based density
estimation from high-dimensional data, and hence for the clutering of
such data, and (b) for local dimensionality reduction; see for example
McLachlan and Peel (2000, Chap. 8).
Some more material on dimension reduction
methods can be found in Chap. III.6 of this handbook.
Several suggestions are available in the literature for speeding up convergence, some of a general kind and some problem-specific; see for example McLachlan and Krishnan (1997, Chap. 4). Most of them are based on standard numerical analytic methods and suggest a hybrid of EM with methods based on Aitken acceleration, over-relaxation, line searches, Newton methods, conjugate gradients, etc. Unfortunately, the general behaviour of these hybrids is not always clear and they may not yield monotonic increases in the log likelihood over iterations. There are also methods that approach the problem of speeding up convergence in terms of ''efficient'' data augmentation scheme (Meng and van Dyk, 1997). Since the convergence rate of the EM algorithm increases with the proportion of observed information in the prescribed EM framework (Sect. 5.2.4), the basic idea of the scheme is to search for an efficient way of augmenting the observed data. By efficient, they mean less augmentation of the observed data (greater speed of convergence) while maintaining the simplicity and stability of the EM algorithm. A common trade-off is that the resulting E- and/or M-steps may be made appreciably more difficult to implement. To this end, Meng and van Dyk (1997) introduce a working parameter in their specification of the complete data to index a class of possible schemes to facilitate the search.
A further extension of the EM algorithm, called the Space-Alternating Generalized EM (SAGE), has been proposed by Fessler and Hero (1994), where they update sequentially small subsets of parameters using appropriately smaller complete data spaces. This approach is eminently suitable for situations like image reconstruction where the parameters are large in number. Meng and van Dyk (1997) combined the ECME and SAGE algorithms. The so-called Alternating ECM (AECM) algorithm allows the data augmentation scheme to vary where necessary over the CM-steps, within and between iterations. With this flexible data augmentation and model reduction schemes, the amount of data augmentation decreases and hence efficient computations are achieved.
In contrast to the AECM algorithm where the optimal value of the working parameter is determined before EM iterations, a variant is considered by Liu et al. (1998) which maximizes the complete-data log likelihood as a function of the working parameter within each EM iteration. The so-called parameter-expanded EM (PX-EM) algorithm has been used for fast stable computation of MLE in a wide range of models. This variant has been further developed, known as the one-step-late PX-EM algorithm, to compute MAP or maximum penalized likelihood (MPL) estimates (van Dyk and Tang, 2003). Analogous convergence results hold for the ECME, AECM, and PX-EM algorithms as for the EM and ECM algorithms. More importantly, these algorithms preserve the monotone convergence of the EM algorithm as stated in (5.28).
Neal and Hinton (1998) proposed the incremental EM (IEM) algorithm to
improve the convergence rate of the EM algorithm. With this algorithm,
the available ![]() observations are divided into
observations are divided into
![]() blocks and the E-step is implemented for only a block of data at
a time before performing a M-step. A ''scan'' of the IEM algorithm
thus consists of
blocks and the E-step is implemented for only a block of data at
a time before performing a M-step. A ''scan'' of the IEM algorithm
thus consists of ![]() partial E-steps and
partial E-steps and ![]() M-steps. The argument for
improved rate of convergence is that the algorithm exploits new
information more quickly rather than waiting for a complete scan of
the data before parameters are updated by an M-step. Another method
suggested by Neal and Hinton (1998) is the sparse EM (SPEM)
algorithm. In fitting a mixture model to a data set by ML via the EM
algorithm,
the current estimates of some posterior probabilities
M-steps. The argument for
improved rate of convergence is that the algorithm exploits new
information more quickly rather than waiting for a complete scan of
the data before parameters are updated by an M-step. Another method
suggested by Neal and Hinton (1998) is the sparse EM (SPEM)
algorithm. In fitting a mixture model to a data set by ML via the EM
algorithm,
the current estimates of some posterior probabilities
![]() for a given data point
for a given data point
![]() are often
close to zero. For example, if
are often
close to zero. For example, if
![]() for the
first two components of a four-component mixture being fitted, then
with the SPEM algorithm we would fix
for the
first two components of a four-component mixture being fitted, then
with the SPEM algorithm we would fix
![]() (
(![]() ) for
membership of
) for
membership of
![]() with respect to the first two components
at their current values and only update
with respect to the first two components
at their current values and only update
![]() (
(![]() )
for the last two components. This sparse E-step will take time
proportional to the number of components that needed to be
updated. A sparse version of the IEM algorithm (SPIEM) can be
formulated by combining the partial E-step and the sparse E-step.
With these versions, the likelihood is
still increased after each scan.
Ng and McLachlan (2003a) study the
relative performances of these algorithms with various number of
blocks
)
for the last two components. This sparse E-step will take time
proportional to the number of components that needed to be
updated. A sparse version of the IEM algorithm (SPIEM) can be
formulated by combining the partial E-step and the sparse E-step.
With these versions, the likelihood is
still increased after each scan.
Ng and McLachlan (2003a) study the
relative performances of these algorithms with various number of
blocks ![]() for the fitting of normal mixtures.
They propose to choose
for the fitting of normal mixtures.
They propose to choose ![]() to be that factor of
to be that factor of ![]() that is the closest to
that is the closest to
![]() round
round![]() for
unrestricted component-covariance matrices, where round
for
unrestricted component-covariance matrices, where round![]() rounds
rounds
![]() to the nearest integer.
to the nearest integer.
Other approaches for speeding up the EM algorithm for mixtures have been
considered in Bradley et al. (1998) and Moore (1999). The
former developed a scalable version of the EM algorithm to handle very
large databases with a limited memory buffer. It is based on identifying
regions of the data that are compressible and regions that must be
maintained in memory.
Moore (1999) has made use of multiresolution
![]() d-trees
d-trees ![]() d-trees) to speed up the fitting process of the EM
algorithm on normal mixtures.
Here
d-trees) to speed up the fitting process of the EM
algorithm on normal mixtures.
Here ![]() d stands for
d stands for ![]() -dimensional where, in our notation,
-dimensional where, in our notation,
![]() , the dimension of an observation
, the dimension of an observation
![]() . His approach builds
a multiresolution data structure to summarize the database
at all resolutions of interest simultaneously.
The
. His approach builds
a multiresolution data structure to summarize the database
at all resolutions of interest simultaneously.
The ![]() d-tree is
a binary tree that recursively splits the whole set of data points into
partitions. The contribution of all the data points in a tree node to
the sufficient statistics is simplified by calculating at the mean of
these data points to save time.
Ng and McLachlan (2003b) combined the IEM
algorithm with the
d-tree is
a binary tree that recursively splits the whole set of data points into
partitions. The contribution of all the data points in a tree node to
the sufficient statistics is simplified by calculating at the mean of
these data points to save time.
Ng and McLachlan (2003b) combined the IEM
algorithm with the ![]() d-tree approach to further speed
up the EM algorithm.
They also studied the convergence properties of this modified version
and the relative performance with some other variants of the EM
algorithm for speeding up the convergence for the fitting of normal
mixtures.
d-tree approach to further speed
up the EM algorithm.
They also studied the convergence properties of this modified version
and the relative performance with some other variants of the EM
algorithm for speeding up the convergence for the fitting of normal
mixtures.
Neither the scalable EM algorithm nor the ![]() d-tree approach guarantee the
desirable reliable convergence properties of the EM algorithm. Moreover, the
scalable EM algorithm becomes less efficient when the number of components
d-tree approach guarantee the
desirable reliable convergence properties of the EM algorithm. Moreover, the
scalable EM algorithm becomes less efficient when the number of components ![]() is large, and the
is large, and the ![]() d-trees-based algorithms slow down as the dimension
d-trees-based algorithms slow down as the dimension ![]() increases; see for example Ng and McLachlan (2003b) and the references
therein. Further discussion on data mining applications can be found in
Chap. III.13 of this handbook.
increases; see for example Ng and McLachlan (2003b) and the references
therein. Further discussion on data mining applications can be found in
Chap. III.13 of this handbook.