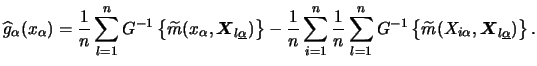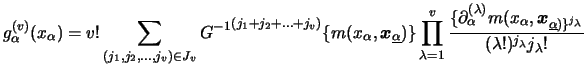It is clear that additive models are just a special case of
APLM or GAM (without a parametric linear part and a trivial link
function ![]() identity). The other way around, what we said about the
advantages and motivations for additive model holds also for APLM and GAM.
In Chapter 5, models with link function have been introduced
and motivated, in particular for latent
variables or binary choice models. Hence, an additive modeling of the
index function is analogous to extending linear regressions models to
additive models.
identity). The other way around, what we said about the
advantages and motivations for additive model holds also for APLM and GAM.
In Chapter 5, models with link function have been introduced
and motivated, in particular for latent
variables or binary choice models. Hence, an additive modeling of the
index function is analogous to extending linear regressions models to
additive models.
Again it was Stone (1986) who showed that GAM has the favorable property of circumventing the curse of dimensionality. Doing the estimation properly, the rate of convergence can reach the same degree that is typical for the univariate case.
As we have discussed for additive models, there are two alternative
approaches estimating the component functions, backfitting and marginal
integration. However, recall that in models with a nontrivial link ![]() ,
the response
,
the response ![]() is not directly related to the index function.
This fact must now be taken into account in the estimation procedure.
For example, consider the partial residual
is not directly related to the index function.
This fact must now be taken into account in the estimation procedure.
For example, consider the partial residual
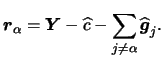
As before, we denote this adjusted dependent variable
with ![]() . After conducting a complete backfitting
with partial residuals based on
. After conducting a complete backfitting
with partial residuals based on ![]() we obtain a set of
estimated functions
we obtain a set of
estimated functions
![]() that explain the variable
that explain the variable ![]() . But how good do these functions
explain the untransformed dependent variable
. But how good do these functions
explain the untransformed dependent variable ![]() ?
The fit of the overall model in this sense is
assessed by the
local scoring
algorithm. The complete
estimation procedure for GAM thus consists of two iterative algorithms:
backfitting and local scoring. Backfitting is the ``inner"
iteration, whereas local scoring can bee seen as the ``outer"
iteration.
?
The fit of the overall model in this sense is
assessed by the
local scoring
algorithm. The complete
estimation procedure for GAM thus consists of two iterative algorithms:
backfitting and local scoring. Backfitting is the ``inner"
iteration, whereas local scoring can bee seen as the ``outer"
iteration.
We summarized the final algorithm as given by Buja et al. (1989) and Hastie & Tibshirani (1990). For the presentation keep in mind that local scoring corresponds to Fisher scoring in the IRLS algorithm for the GLM. Then, backfitting fits the index by additive instead of linear components. The inner backfitting algorithm is thus completely analogous to that in Chapter 8.
![\fbox{\parbox{0.95\textwidth}{
\centerline{{Local Scoring\index{local scoring} A...
...w_i$\\ [3mm]
{\em until\/}& convergence is reached
\end{tabular}\end{center}}}](spmhtmlimg2552.gif)
Next, we present the backfitting routine which is applied
inside local scoring to fit the additive component functions.
This backfitting differs from that in the AM case
in that firstly we use the adjusted dependent
variable ![]() instead of
instead of ![]() and secondly we use a weighted
smoothing. For this purpose we introduce the weighted smoother
matrix
and secondly we use a weighted
smoothing. For this purpose we introduce the weighted smoother
matrix
![]() defined as
defined as
![]() where
where
![]() (
(![]() from the
local scoring) and
from the
local scoring) and
![]() .
.
![\fbox{\parbox{0.95\textwidth}{
\centerline{{Backfitting Algorithm for GAM}}
\hru...
...$\ \\ [3mm]
{\em until\/}
& convergence is reached
\end{tabular}\end{center}}}](spmhtmlimg2558.gif)
The theoretical properties of these iterative procedures are even complicated when the index consists of known (up to some parameters) component functions. For the general case of nonparametric index functions asymptotic results have only been be developed for special cases. The situation is different for the marginal integration approach which we study in the following subsection.
When using the marginal integration approach to estimate a GAM, the local scoring loop is not needed. Here, the extension from the additive model to the to GAM is straight forward. Recall that we consider
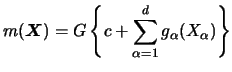
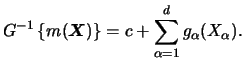
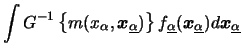
Using a kernel smoother for the pre-estimator
![]() , this estimator has similar asymptotical properties as we found for
the additive model, cf. Subsection 8.2.2.
We remark that using a local polynomial smoother for
, this estimator has similar asymptotical properties as we found for
the additive model, cf. Subsection 8.2.2.
We remark that using a local polynomial smoother for
![]() can yield simultaneously estimates for the derivatives of the
component functions
can yield simultaneously estimates for the derivatives of the
component functions ![]() .
However, due to the existence of a nontrivial link
.
However, due to the existence of a nontrivial link ![]() , all
expressions become more complicated.
Let us note that for models of the form
, all
expressions become more complicated.
Let us note that for models of the form
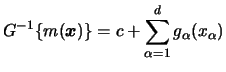
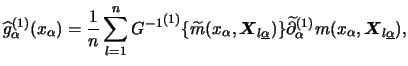
The expression for the second derivative is additionally complicated.
Yang et al. (2003) provide asymptotic theory and simulations for this
procedure. For the sake of simplicity we restrict the following theorem
to the local constant estimation of the pre-estimate
![]() ,
see also Linton & Härdle (1996). As introduced previously,
the integration estimator requires to choose two
bandwidths,
,
see also Linton & Härdle (1996). As introduced previously,
the integration estimator requires to choose two
bandwidths, ![]() for the direction of interest and
for the direction of interest and
![]() for
the nuisance direction.
for
the nuisance direction.
It is obvious that marginal integration leads to estimates of the same rate as for univariate Nadaraya-Watson regression. This is the same rate that we obtained for the additive model without link function. Let us mention that in general the properties of backfitting and marginal integration found in Chapter 8 carry over to the GAM. However, detailed simulation studies do not yet exist for this case and a theoretical comparison is not possible due to the lack of asymptotical results for backfitting in GAM.