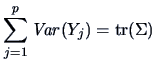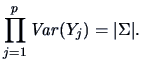The main objective of principal components analysis (PC) is to reduce the
dimension of the observations.
The simplest way of dimension reduction
is to take just one element of the observed vector and to
discard all others.
This is not a very reasonable approach,
as we have seen in the earlier chapters,
since strength may be lost in interpreting the data.
In the bank notes example we have seen that just one variable
(e.g. ![]() = length) had
no discriminatory power in distinguishing counterfeit from genuine bank notes.
An alternative method is to weight all variables equally, i.e.,
to consider the simple average
= length) had
no discriminatory power in distinguishing counterfeit from genuine bank notes.
An alternative method is to weight all variables equally, i.e.,
to consider the simple average
![]() of all the elements in the vector
of all the elements in the vector
![]() .
This again is undesirable, since all of the
elements of
.
This again is undesirable, since all of the
elements of ![]() are considered with equal importance (weight).
are considered with equal importance (weight).
A more flexible approach is to study a weighted average, namely
Figures 9.1 and 9.2 show two such projections (SLCs) of the same data set with zero mean. In Figure 9.1 an arbitrary projection is displayed. The upper window shows the data point cloud and the line onto which the data are projected. The middle window shows the projected values in the selected direction. The lower window shows the variance of the actual projection and the percentage of the total variance that is explained.
Figure 9.2 shows the projection that captures
the majority of the variance in the data.
This direction is of interest and is located along the main direction of
the point cloud.
The same line of thought can be applied to all data orthogonal to
this direction leading to the second eigenvector. The SLC with the
highest variance obtained from maximizing (9.2)
is the first principal component
(PC)
![]() . Orthogonal
to the direction
. Orthogonal
to the direction ![]() we find the SLC with the second highest
variance:
we find the SLC with the second highest
variance:
![]() , the second PC.
, the second PC.
Proceeding in this way and writing in matrix notation, the result
for a random variable ![]() with
with ![]() and
and
![]() is the
PC transformation
which is defined as
is the
PC transformation
which is defined as
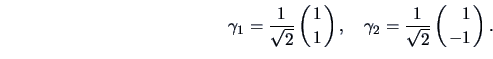
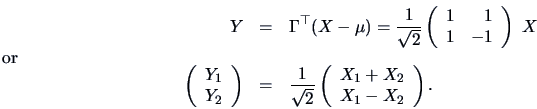


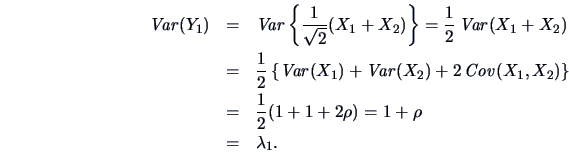
This can be expressed more generally and is given in the next theorem.
The connection between the PC transformation and the search for the best SLC is made in the following theorem, which follows directly from (9.2) and Theorem 2.5.
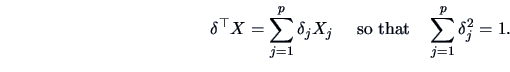
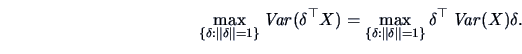
![\includegraphics[width=1\defpicwidth]{sim1.ps}](mvahtmlimg2643.gif)
![\includegraphics[width=1\defpicwidth]{sim2.ps}](mvahtmlimg2644.gif)