Consider the fixed design model of equispaced and fixed ![]() on the
unit interval. Suppose that it is desired to estimate the
on the
unit interval. Suppose that it is desired to estimate the ![]() th derivative
th derivative
![]() of
of ![]() . The kernel smoother for this problem is
. The kernel smoother for this problem is
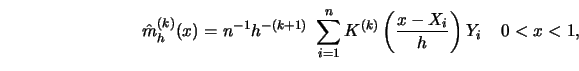
![\begin{eqnarray*}
\hbox{support}(K)&=&[-1,1];\cr
K^{(j)}(1)=K^{(j)}(-1)&=&0 \, \quad j=0,\ldots,(k-1).
\end{eqnarray*}](anrhtmlimg1379.gif)
Higher order kernel functions ![]() satisfy 4.6.32 with a large
value of
satisfy 4.6.32 with a large
value of ![]() (Müller 1984a; Sacks and Ylvisaker 1981). This means that
(Müller 1984a; Sacks and Ylvisaker 1981). This means that
![]() has the first
has the first ![]() moments and then the
moments and then the ![]() th up to the
th up to the
![]() th moment vanishing.
th moment vanishing.
Since higher order kernels take on negative values the resulting estimates inherit this property. For instance, in the related field of density estimation, kernel smoothing with higher order kernels can result in negative density estimates. Also, in the setting of regression smoothing one should proceed cautiously when using higher order kernels. For example, in the expenditure data situation of Figure 2.3 the estimated expenditure Engel curve could take on negative values for a higher order kernel. For this reason, it is highly recommended to use a positive kernel though one has to pay a price in bias increase.
It seems appropriate to remind the reader that ``higher order'' kernels reduce
the bias in an asymptotic sense. Recall that when estimating ![]() , the optimal
rate of convergence (Section 4.1) for kernels with
, the optimal
rate of convergence (Section 4.1) for kernels with ![]() is
is ![]() . If a
kernel with
. If a
kernel with ![]() is used, then the optimal rate is
is used, then the optimal rate is ![]() . So using a
``higher order'' kernel results in a relatively small improvement
. So using a
``higher order'' kernel results in a relatively small improvement ![]() in the order of magnitude of the best achievable squared error distance. For
all except astronomical sample sizes this difference will become visible.
Higher order kernels have other undesirable side effects as can be seen from
the following discussion of the jackknifing approach.
in the order of magnitude of the best achievable squared error distance. For
all except astronomical sample sizes this difference will become visible.
Higher order kernels have other undesirable side effects as can be seen from
the following discussion of the jackknifing approach.
Schucany and Sommers (1977) construct a jackknife kernel density estimator
that yields a bias reducing kernel of higher order. The jackknife technique is
also applicable for bias reduction in regression smoothing. Consider the jackknife estimate (Härdle 1986a)
![\begin{displaymath}G({\hat{m}}_{h_1}, {\hat{m}}_{h_2}) (x)=(1-R)^{-1} [ {\hat{m}}_{h_1} (x)-R {\hat{m}}_{h_2} (x)
],\end{displaymath}](anrhtmlimg1394.gif)

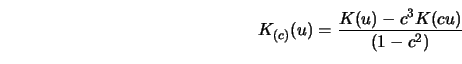

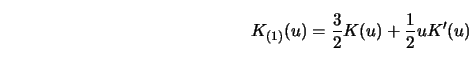
At first sight the use of the jackknife technique seems to be a good strategy.
If at the first step only a small amount of smoothness is ascribed to ![]() then
in a further step the jackknife estimate will indeed reduce the bias, provided
that
then
in a further step the jackknife estimate will indeed reduce the bias, provided
that ![]() is four-times differentiable. However, a sharper analysis of this
strategy reveals that the variance (for fixed
is four-times differentiable. However, a sharper analysis of this
strategy reveals that the variance (for fixed ![]() ) may be inflated.
) may be inflated.
Consider the Epanechnikov kernel
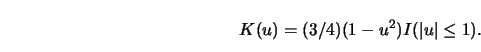
![\begin{eqnarray*}
c_K&=&\int K^2 (u)d u=3/5,\cr
\int K^2_{(c)} (u)d u&=&{{9 \over 10} [ c^3+2 c^2+4/3 c+2/3 ] \over [ c+1
]^2}
\end{eqnarray*}](anrhtmlimg1408.gif)
|
|
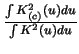 |
|
| 0.10 | 0.610 | 1.017 |
| 0.20 | 0.638 | 1.063 |
| 0.30 | 0.678 | 1.130 |
| 0.40 | 0.727 | 1.212 |
| 0.50 | 0.783 | 1.305 |
| 0.60 | 0.844 | 1.407 |
| 0.70 | 0.900 | 1.517 |
| 0.80 | 0.979 | 1.632 |
| 0.90 | 1.050 | 1.751 |
| 0.91 | 1.058 | 1.764 |
| 0.92 | 1.065 | 1.776 |
| 0.93 | 1.073 | 1.788 |
| 0.94 | 1.080 | 1.800 |
| 0.95 | 1.087 | 1.812 |
| 0.96 | 1.095 | 1.825 |
| 0.97 | 1.102 | 1.837 |
| 0.98 | 1.110 | 1.850 |
| 0.99 | 1.117 | 1.862 |
It is apparent from these figures that some caution must be exercised in
selecting ![]() (and
(and ![]() ), since the variance increases rapidly as
), since the variance increases rapidly as ![]() tends to
one. In order to compare the mean squared error of
tends to
one. In order to compare the mean squared error of ![]() with that of
with that of
![]() one could equalize the variances by setting
one could equalize the variances by setting
![\begin{displaymath}h_1=\left[ \int K^2_{(c)} (u)d u/\int K^2(u)d u \right] h.\end{displaymath}](anrhtmlimg1412.gif)
Since the choice of ![]() (and
(and ![]() ) seems to be delicate in a practical example,
it is interesting to evaluate the jackknifed estimator in a simulated example.
Suppose that
) seems to be delicate in a practical example,
it is interesting to evaluate the jackknifed estimator in a simulated example.
Suppose that
![]() and it is desired to evaluate
the mean squared error at
and it is desired to evaluate
the mean squared error at ![]() . A bandwidth
. A bandwidth ![]() , being roughly equal to
0.3, would minimize the mean squared error of
, being roughly equal to
0.3, would minimize the mean squared error of
![]() (with the
Epanechnikov kernel). Table 4.5 shows the ratio of the mean squared error of
(with the
Epanechnikov kernel). Table 4.5 shows the ratio of the mean squared error of
![]() to that of
to that of ![]() as
as ![]() and
and ![]() are varied.
are varied.
| |
|
|
|||||||
|
|
0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| 0.2 | 1.017 | 0.67 | 0.51 | 1.063 | 0.709 | 0.532 | 1.13 | 0.753 | 0.565 |
| 0.3 | 1.52 | 1.017 | 0.765 | 1.59 | 1.063 | 0.798 | 1.695 | 1.13 | 0.847 |
| 0.4 | 2.035 | 1.357 | 1.020 | 2.127 | 1.418 | 1.064 | 2.26 | 1.507 | 1.13 |
| |
|
|
|||||||
|
|
0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| 0.2 | 1.212 | 0.808 | 0.606 | 1.305 | 0.87 | 0.652 | 1.407 | 0.938 | 0.703 |
| 0.3 | 1.818 | 1.212 | 0.909 | 1.958 | 1.305 | 0.979 | 2.111 | 1.407 | 1.055 |
| 0.4 | 2.424 | 1.616 | 1.212 | 2.611 | 1.74 | 1.305 | 2.815 | 1.877 | 1.407 |
| |
|
|
|||||||
|
|
0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| 0.2 | 1.517 | 1.011 | 0.758 | 1.632 | 1.088 | 0.816 | 1.751 | 1.167 | 0.875 |
| 0.3 | 2.275 | 1.517 | 1.137 | 2.448 | 1.632 | 1.224 | 2.627 | 1.751 | 1.313 |
| 0.4 | 3.034 | 2.022 | 1.517 | 3.264 | 2.176 | 1.632 | 3.503 | 2.335 | 1.751 |
The use of the higher order kernel technique, as is done by the jackknife
technique, may thus result in a mean squared error nearly twice as large as
the corresponding error of the ordinary Epanechnikov kernel smoother, as can
be seen from the entry
![]() in Table
4.5.
in Table
4.5.
Exercises
4.6.1 Why is it impossible to find a positive symmetric kernel of order
![]() ?
?
4.6.2 Compute the ![]() for higher order kernels of order
for higher order kernels of order ![]() as a
function of
as a
function of ![]() . Do you observe an increasing value of
. Do you observe an increasing value of ![]() as
as ![]() increases?
increases?
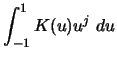
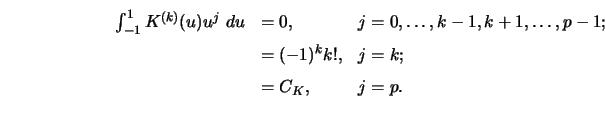
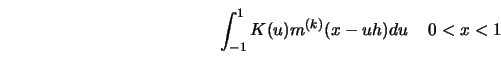
![\begin{displaymath}
{h^{(p-k)}\over p!}\ \left[ \int_{-1}^1 K^{(k)} (u)u^p\ d u \right]
m^{(p)}(x).
\end{displaymath}](anrhtmlimg1388.gif)
![\begin{displaymath}
(1-R)^{-1} \sum^2_{j=1} [ h_1^{2 j}-R h_2^{2 j} ] C_j(K) m^{(2 j)} (x).
\end{displaymath}](anrhtmlimg1399.gif)