There are a number of
different automatic selectors that produce asymptotically
optimal kernel smoothers.
Certainly, any such bandwidth selector is
desirable but there may be data sets where a specific selector may
outperform other candidates. This raises the question of which selector to use
and how far a
specific automatic bandwidth is from its optimum. A further interesting
question is how close the
deviations
![]() , evaluated at the asymptotically optimal
bandwidth, are from the smallest possible deviations.
The answers to these questions are surprising. All presented
selectors are equivalent in an asymptotic sense. The speed at which an
estimated bandwidth tends to the best possible bandwidth is extremely slow.
In addition, theoretical studies show that
the optimally data-driven bandwidth is negatively correlated with the best
possible theoretical bandwidth.
, evaluated at the asymptotically optimal
bandwidth, are from the smallest possible deviations.
The answers to these questions are surprising. All presented
selectors are equivalent in an asymptotic sense. The speed at which an
estimated bandwidth tends to the best possible bandwidth is extremely slow.
In addition, theoretical studies show that
the optimally data-driven bandwidth is negatively correlated with the best
possible theoretical bandwidth.
Unfortunately, the mathematics necessary to investigate this issue
are rather complicated so I prefer to work in
the fixed design model with equispaced design variables on the unit interval,
that is,
![]() . Assume further that the
. Assume further that the ![]() have
common variance,
have
common variance, ![]() , say. The kernel estimator
proposed by Priestley and Chao (1972) is considered,
, say. The kernel estimator
proposed by Priestley and Chao (1972) is considered,
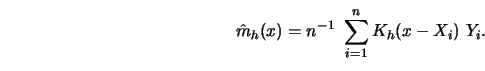
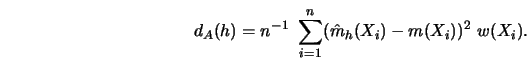
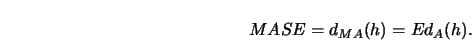
How fast do ![]() and
and ![]() tend to zero?
We have seen that
tend to zero?
We have seen that ![]() and
and
![]() are each roughly equal to
are each roughly equal to

Of course, we can try to estimate ![]() by the plug-in method, but there may
be a difference when using cross-validation or the penalizing function
approach.
In this setting of equidistant
by the plug-in method, but there may
be a difference when using cross-validation or the penalizing function
approach.
In this setting of equidistant ![]() on the unit interval, the penalizing
functions that are presented in Section 5.1 can be written as
on the unit interval, the penalizing
functions that are presented in Section 5.1 can be written as

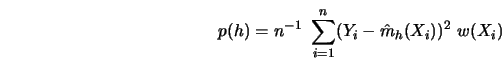
Simple examples are:
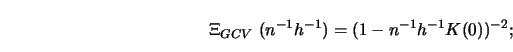
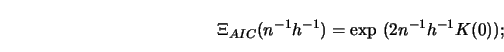
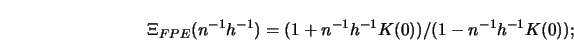
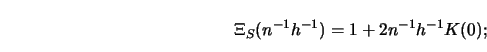
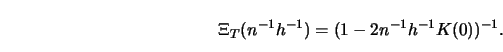
To gain some insight into how these selection functions differ from each other, consider Figure 5.10.
![\includegraphics[scale=0.7]{ANRpenalize.ps}](anrhtmlimg1606.gif)
|
Each of the displayed penalizing functions has the same Taylor expansion,
more precisely, as ![]() ,
,
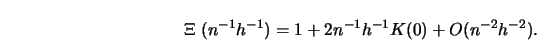
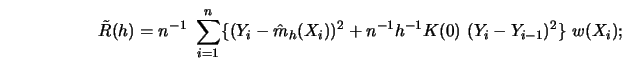
All the above bandwidth selectors are asymptotically optimal, that is, the
ratio of estimated loss to minimum loss tends to one,
30pt
to 30pt(A1) the errors
![]() are independent and
identically distributed with mean zero, variance
are independent and
identically distributed with mean zero, variance ![]() , and all
other moments finite;
, and all
other moments finite;
30pt to 30pt(A2) the kernel K is compactly supported with a Hölder continuous second derivative;
30pt
to 30pt(A3) the regression function ![]() has a uniformly continuous
integrable second derivative.
has a uniformly continuous
integrable second derivative.
Then, as ![]()
Precise formula for ![]() and
and ![]() are given subsequently. A proof of this theorem
may be found in Härdle, Hall and Marron (1988).
are given subsequently. A proof of this theorem
may be found in Härdle, Hall and Marron (1988).
Between ![]() and
and ![]() , the above convergence speeds
5.2.14 are saying that the relative difference
, the above convergence speeds
5.2.14 are saying that the relative difference


The constants
![]() from the above two
Theorems are
from the above two
Theorems are

![\begin{eqnarray*}
\sigma^2_4&=& {8 \over {C^3_0}} \sigma^4 \left[ \int w^2 \righ...
...[ \int w
\right]
+ 3C^2_0 d_K^2 \left[ \int (m'')^2w^2 \right] .\end{eqnarray*}](anrhtmlimg1631.gif)
An important consequence of these two limit theorems describing the
behavior of automatically selected bandwidths is that they imply that
the ``plug-in" method of choosing ![]() (in which
one substitutes estimates of
the unknown parts of
(in which
one substitutes estimates of
the unknown parts of ![]() ), even if one knew the unknowns
), even if one knew the unknowns ![]() and
and
![]() , has an algebraic rate of convergence no better
than that of the
, has an algebraic rate of convergence no better
than that of the ![]() s given in Algorithm 5.1.1. Hence the additional noise
involved in estimating these unknown parts in practice, especially the
second derivative part in the case where
s given in Algorithm 5.1.1. Hence the additional noise
involved in estimating these unknown parts in practice, especially the
second derivative part in the case where ![]() is not very smooth,
casts some doubt on the applicability of the plug-in estimator.
is not very smooth,
casts some doubt on the applicability of the plug-in estimator.
By comparing ![]() and
and ![]() , the asymptotic variances of
the previous two theorems, one sees that
, the asymptotic variances of
the previous two theorems, one sees that
![]() so
so ![]() is closer to
is closer to ![]() than
than ![]() is in terms
of asymptotic variances.
It is important to note that the asymptotic variance
is in terms
of asymptotic variances.
It is important to note that the asymptotic variance ![]() is independent of the particular correction function
is independent of the particular correction function
![]() although simulation studies to be mentioned subsequently
seem to indicate a different performance for different
although simulation studies to be mentioned subsequently
seem to indicate a different performance for different ![]() s.
In the related field of density estimation Hall and Marron (1987) showed
that the relative rate of convergence of
s.
In the related field of density estimation Hall and Marron (1987) showed
that the relative rate of convergence of

Several extensions of the above limit theorems are possible.
For instance,
the assumption that the errors are identically distributed can be
relaxed to assuming that ![]() has variance
has variance ![]() ,
where
the variance function
,
where
the variance function ![]() is a smooth function. Also the design
points need not be univariate. In the multivariate case with the
is a smooth function. Also the design
points need not be univariate. In the multivariate case with the
![]() having dimension
having dimension ![]() , the exponents of the first parts of
5.2.14
and 5.2.15 change from
, the exponents of the first parts of
5.2.14
and 5.2.15 change from ![]() to
to
![]() .
.
The kernel
![]() can also be allowed to take on negative values to exploit possible
higher rates of convergence (Section 4.1). In particular, if
can also be allowed to take on negative values to exploit possible
higher rates of convergence (Section 4.1). In particular, if ![]() is of order
is of order ![]() (see Section 4.5) and if
(see Section 4.5) and if ![]() has a uniformly
continuous
has a uniformly
continuous ![]() th derivative, then the exponents of convergence change
from
th derivative, then the exponents of convergence change
from ![]() to
to ![]() .
This says that the relative speed of convergence for
estimated bandwidths is slower for functions
.
This says that the relative speed of convergence for
estimated bandwidths is slower for functions ![]() with higher derivatives
than it is for functions with lower derivatives.
One should look not only
at the bandwidth limit theorems but also at the limit result for
with higher derivatives
than it is for functions with lower derivatives.
One should look not only
at the bandwidth limit theorems but also at the limit result for
![]() . In the case in which
. In the case in which ![]() has higher derivatives,
has higher derivatives, ![]() converges
faster to zero, specifically, at the rate
converges
faster to zero, specifically, at the rate
![]() .
However, this issue seems to be counter-intuitive. Why is the relative speed
for
.
However, this issue seems to be counter-intuitive. Why is the relative speed
for ![]() for higher order kernels slower than that for lower order kernels?
To get some insight into this consider the following figure showing
for higher order kernels slower than that for lower order kernels?
To get some insight into this consider the following figure showing
![]() for higher and lower order kernels.
for higher and lower order kernels.
One can see that ![]() for the higher order kernel has a flatter
minimum than that the lower order kernel. Therefore, it is harder to approximate
the true bandwidth. But since the minimum value
for the higher order kernel has a flatter
minimum than that the lower order kernel. Therefore, it is harder to approximate
the true bandwidth. But since the minimum value ![]() is smaller than
the minimum value
is smaller than
the minimum value ![]() for the lower order kernel it does not matter so
much to miss the minimum
for the lower order kernel it does not matter so
much to miss the minimum ![]() !
!
Rice (1984a) and Härdle, Hall and
Marron (1988) performed a simulation study in order
to shed some light on the finite sample performance
of the different selectors. One hundred
samples of ![]() pseudo-random normal variables,
pseudo-random normal variables, ![]() , with
mean zero and standard deviation
, with
mean zero and standard deviation
![]() were generated.
These were added to
the curve
were generated.
These were added to
the curve
![]() which allows ``wrap-around-estimation" to
eliminate boundary effects. The kernel function was taken to be a rescaled
quartic kernel
which allows ``wrap-around-estimation" to
eliminate boundary effects. The kernel function was taken to be a rescaled
quartic kernel
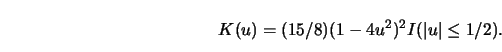


The ordering of performance that was observed in both studies can be qualitatively described through the number of poles that a selector had at the ``no smoothing" point. The more poles the penalizing function had the better it was in these studies.
Figure 5.12
gives an indication of what the limit theorems actually
mean in terms of the actual curves, for one of the actual curves and
for one
of the 100 data sets (with ![]() and
and ![]() ). The solid curve
in each plot is
). The solid curve
in each plot is ![]() . The dashed curves are the
estimates
. The dashed curves are the
estimates ![]() .
.
![\includegraphics[scale=0.7]{ANR75regobsa.ps}](anrhtmlimg1665.gif)
|
![\includegraphics[scale=0.7]{ANR75regobsb.ps}](anrhtmlimg1667.gif)
|
![\includegraphics[scale=0.7]{ANR75regobsc.ps}](anrhtmlimg1669.gif)
|
In Figure 5.12 the dashed curve is computed
with ![]() the minimizer of
the minimizer of ![]() for that data set. In Figure
5.13,
for that data set. In Figure
5.13,
![]() is computed with
is computed with ![]() , the minimizer of ASE. Finally in Figure
5.14 the curve suggested by all the other selectors
, the minimizer of ASE. Finally in Figure
5.14 the curve suggested by all the other selectors ![]() is shown. This example of how different the selectors can be for a
specific data set was chosen to demonstrate again the slow rate of
convergence in the above limit theorems.
More details about this study, for example, the question of how close to
normality
the distribution of
is shown. This example of how different the selectors can be for a
specific data set was chosen to demonstrate again the slow rate of
convergence in the above limit theorems.
More details about this study, for example, the question of how close to
normality
the distribution of
![]() is, for this small sample
size, can be found in Härdle, Hall and Marron (1988).
is, for this small sample
size, can be found in Härdle, Hall and Marron (1988).
Table 5.1 shows the sample mean and standard deviation of the bandwidth
minimizing the quantity listed at the left. It is interesting that the
selector whose mean matches best with ![]() is the rather poorly
performing
is the rather poorly
performing ![]() , which is not surprising given the comments on the poles
above. The selector
, which is not surprising given the comments on the poles
above. The selector ![]() biases slightly toward
biases slightly toward
![]() , while
, while ![]() biases more downwards.
The last two columns show the sample correlation
coefficients for the selected bandwidth with
biases more downwards.
The last two columns show the sample correlation
coefficients for the selected bandwidth with ![]() and
and
![]() , the minimizer of
, the minimizer of ![]() , respectively.
, respectively.
|
|
|
|
|
|
| ASE | .51000 | .10507 | 1.00000 | -.46002 |
| T | .56035 | .13845 | -.50654 | .85076 |
| CV | .57287 | .15411 | -.47494 | .87105 |
| GCV | .52929 | .16510 | -.46602 | 1.00000 |
| R | .52482 | .17852 | -.40540 | .83565 |
| FPE | .49790 | .17846 | -.45879 | .76829 |
| AIC | .49379 | .18169 | -.46472 | .76597 |
| S | .39435 | .21350 | -.21965 | .52915 |
| ASE | .36010 | .07198 | 1.00000 | -.31463 |
| T | .32740 | .08558 | -.32243 | .99869 |
| GCV | .32580 | .08864 | -.31463 | 1.00000 |
| AIC | .32200 | .08865 | -.30113 | .97373 |
| S | .31840 | .08886 | -.29687 | .97308 |
The simulations shown in Table 5.1. indicated that, despite the equivalence
of all selectors, Rice's ![]() had a slightly better performance.
This stemmed, as explained,
from the fact that the selector
had a slightly better performance.
This stemmed, as explained,
from the fact that the selector ![]() has a slight
bias towards oversmoothing (pole of
has a slight
bias towards oversmoothing (pole of ![]() at twice the
``no smoothing" point). The performance of
at twice the
``no smoothing" point). The performance of ![]() should get worse if the
simulation setting is changed in such a way that ``reduction
of bias is more important than reduction of variance". With other words
the right branch of the
should get worse if the
simulation setting is changed in such a way that ``reduction
of bias is more important than reduction of variance". With other words
the right branch of the ![]() curve becomes steeper than the left.
curve becomes steeper than the left.
A simulation study in this direction was carried out by Härdle (1986e).
The sample was constructed from ![]() observations with normal errors,
observations with normal errors,
![]() , and a sinusoidal regression curve
, and a sinusoidal regression curve
![]() . The quartic kernel was chosen.
The number of exceedances (formulated as above) for
. The quartic kernel was chosen.
The number of exceedances (formulated as above) for
![]() was
studied.
was
studied.
As expected,
the performance of ![]() got worse as
got worse as ![]() increased, which supports the
hypothesis that the relatively good performance of
increased, which supports the
hypothesis that the relatively good performance of ![]() was due to the specific
simulation setting. The best overall performance, though, showed
GCV (generalized cross-validation).
was due to the specific
simulation setting. The best overall performance, though, showed
GCV (generalized cross-validation).
Exercises
5.2.1Prove that in the setting of this section the cross-validation function
approach is also based on a penalizing idea, that is, prove formula (5.2.2)
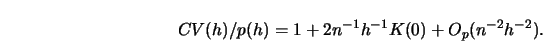
5.2.2Show that ![]() , the unbiased risk estimation selection function,
satisfies
, the unbiased risk estimation selection function,
satisfies
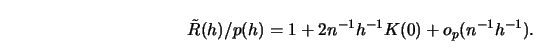
5.2.3Interpret the penalizing term for a uniform kernel using the fact that ![]() points fall into a kernel neighborhood. What does ``penalizing" now mean
in terms of
points fall into a kernel neighborhood. What does ``penalizing" now mean
in terms of ![]() ?
?
5.2.4Prove that from the relative convergence 5.2.12


5.2.5Recall the variances of Theorem 5.2.1 and 5.2.2. Show that

5.2.6Can you construct a confidence interval for the bandwidths ![]() ?
?
5.2.7Can you construct a confidence interval for the distance
![]() ?
?
5.2.8How would you extend Theorem 5.2.1 and 5.2.2 to the random design setting.
[Hint : Look at Härdle, Hall and Marron (1990) and use the linearization of the kernel smoother as in Section 4.2]
I have mentioned that in the related field of density estimation there is a
lower-bound result by Hall and Marron (1987) which shows that



This theorem suggests that

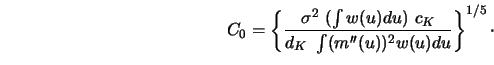

![\includegraphics[scale=0.15]{ANR5,11.ps}](anrhtmlimg1646.gif)