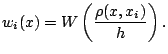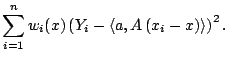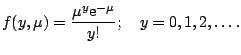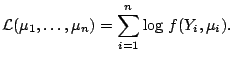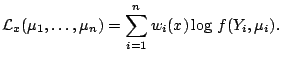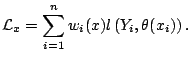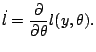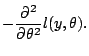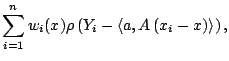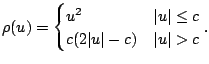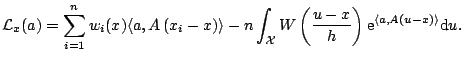



Next: References
Up: 5. Smoothing: Local Regression
Previous: 5.4 Statistics for Linear
Subsections
5.5 Multivariate Smoothers
When there are multiple predictor variables, the smoothing problem
becomes multivariate: 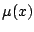 is now a surface. The definition of
kernel and local regression smoothers can be extended to estimate
a regression surface with any number of predictor variables, although
the methods become less useful for more than 2 or 3 variables. There
are several reasons for this:
is now a surface. The definition of
kernel and local regression smoothers can be extended to estimate
a regression surface with any number of predictor variables, although
the methods become less useful for more than 2 or 3 variables. There
are several reasons for this:
- Data sparsity - the curse of dimensionality.
- Visualization issues - how does one view and interpret
a high dimensional smooth regression surface?
- Computation is often much more expensive in high dimensions.
For these reasons, use of local polynomials and other smoothers to
model high dimensional surfaces is rarely recommended, and the
presentation here is restricted to the two-dimensional case. In
higher dimensions, smoothers can be used in conjunction with dimension
reduction procedures
(Chap. III.6), which attempt to
model the high-dimensional surface through low-dimensional
components. Examples of this type of procedure include Projection
Pursuit ([9]),
Additive Models ([14]),
Semiparametric Models ([26] and
Chap. III.10)
and recursive partitioning (Chap. III.14).
Suppose the dataset consists of 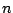 vectors
vectors
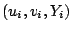 , where
, where
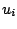 and
and 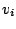 are considered predictor variables, and
are considered predictor variables, and 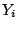 is the
response. For simplicity, we'll use
is the
response. For simplicity, we'll use
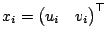 to denote a vector of the predictor
variables. The data are modeled as
to denote a vector of the predictor
variables. The data are modeled as
Bivariate smoothers attempt to estimate the surface
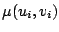 .
Kernel and local regression methods can be extended to the bivariate
case, simply by defining smoothing weights on a plane rather than on
a line. Formally, a bivariate local regression estimate at a point
.
Kernel and local regression methods can be extended to the bivariate
case, simply by defining smoothing weights on a plane rather than on
a line. Formally, a bivariate local regression estimate at a point
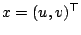 can be constructed as follows:
can be constructed as follows:
- Define a distance measure
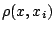 between the
data points and fitting point. A common choice is Euclidean distance,
between the
data points and fitting point. A common choice is Euclidean distance,
- Define the smoothing weights using a kernel function and bandwidth:
- Define a local polynomial approximation, such as a local linear
approximation
when 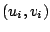 is close to
is close to 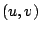 . More generally, a local
polynomial approximation can be written
. More generally, a local
polynomial approximation can be written
where 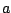 is a vector of coefficients, and
is a vector of coefficients, and 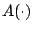 is a vector of
basis polynomials.
is a vector of
basis polynomials.
- Estimate the coefficient vector by local least squares. That is, choose
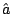 to minimize
to minimize
- The local polynomial estimate is then
5.5.2 Likelihood Smoothing
A likelihood smoother replaces the model (5.1) with
a distributional assumption
where 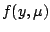 is a specified family of densities, parameterized so
that
is a specified family of densities, parameterized so
that
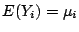 . The family may be chosen depending on the
response variable. If is a count, then the Poisson family is
a natural choice:
. The family may be chosen depending on the
response variable. If is a count, then the Poisson family is
a natural choice:
If is a 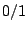 (or no/yes) response, then the Bernoulli family
is appropriate:
(or no/yes) response, then the Bernoulli family
is appropriate:
Given the data, the log-likelihood is
The goal is to estimate the mean function,
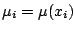 for an
observed set of covariates
for an
observed set of covariates 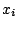 . A generalized linear model
(Chap. III.7) uses a parametric
model for the mean function. Likelihood smoothers assume only that
the mean is a smooth function of the covariates.
. A generalized linear model
(Chap. III.7) uses a parametric
model for the mean function. Likelihood smoothers assume only that
the mean is a smooth function of the covariates.
The earliest work on likelihood smoothing is [16], who used
a penalized binomial likelihood
to estimate mortality rates. The local likelihood method described
below can be viewed as an extension of local polynomial regression,
and was introduced by [30].
Local likelihood estimation is based on a locally weighted version of
the log-likelihood:
A local polynomial
approximation is then used for a transformation of the mean
function. For example, a local quadratic approximation is
The function 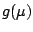 is the link function.
Its primary goal is to remove constraints on the mean by mapping the
parameter space to
is the link function.
Its primary goal is to remove constraints on the mean by mapping the
parameter space to
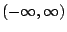 . For example, in the Poisson
case, the parameter space is
. For example, in the Poisson
case, the parameter space is
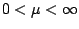 . If the log
transformation
. If the log
transformation
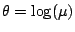 is used, then the parameter space
becomes
is used, then the parameter space
becomes
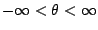 .
.
Let
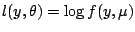 where
where
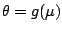 , so that the
locally weighted log-likelihood becomes
, so that the
locally weighted log-likelihood becomes
The maximizer satisfies the likelihood equations,
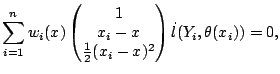 |
(5.20) |
where
In matrix notation, this system of equations can be written in a form
similar to (5.7):
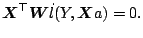 |
(5.21) |
This system of equations is solved to find parameter estimates
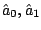 and
and 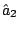 . The local likelihood estimate
is defined as
. The local likelihood estimate
is defined as
The local likelihood equations (5.20) are usually non-linear,
and so the solution must be obtained through iterative methods. The
Newton-Raphson
updating formula is
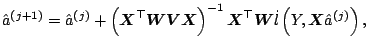 |
(5.22) |
where
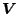 is a diagonal matrix with entries
is a diagonal matrix with entries
For many common likelihoods
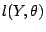 is concave. Under mild
conditions on the design points, this implies that the local
likelihood is also concave, and has a unique global maximizer. If the
Newton-Raphson algorithm converges, it must converge to this global
maximizer.
is concave. Under mild
conditions on the design points, this implies that the local
likelihood is also concave, and has a unique global maximizer. If the
Newton-Raphson algorithm converges, it must converge to this global
maximizer.
The Newton-Raphson algorithm (5.22) cannot be guaranteed to
converge from arbitrary starting values. But for concave likelihoods,
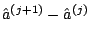 is guaranteed to be an ascent
direction, and convergence can be ensured by controlling the step
size.
is guaranteed to be an ascent
direction, and convergence can be ensured by controlling the step
size.
Since the local likelihood estimate does not have an explicit
representation, statistical properties cannot be derived as easily as
in the local regression case. But a Taylor series expansion of the
local likelihood gives an approximate linearization of the estimate,
leading to theory parallel to that developed in Sects. 5.3
and 5.4 for local regression. See Chap. 4 of
[21].
The local likelihood method has been formulated for regression models.
But variants of the method have been derived for numerous other
settings, including robust regression,
survival models,
censored data,
proportional hazards models, and density estimation.
References include [30], [17],
Loader ([19], [21]).
Robust smoothing combines the ideas of robust estimation
(Chap. III.9) with smoothing. One
method is local M-estimation:
choose to minimize
and estimate
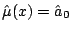 . If
. If
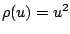 , this
corresponds to local least squares estimation. If
, this
corresponds to local least squares estimation. If 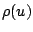 is
a symmetric function that increases more slowly than
is
a symmetric function that increases more slowly than 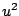 , then the
resulting estimate is more robust to outliers in the data. One
popular choice of is the Huber function:
, then the
resulting estimate is more robust to outliers in the data. One
popular choice of is the Huber function:
References include [11] and [21]. Another variant
of M-estimation for local regression is the iterative procedure of
[4].
Suppose
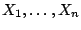 are an independent sample from
a density
are an independent sample from
a density 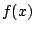 . The goal is to estimate . The local likelihood
for this problem is
. The goal is to estimate . The local likelihood
for this problem is
Letting be the maximizer of the local log-likelihood, the
local likelihood estimate is
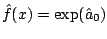 . See
[17] and [19].
. See
[17] and [19].
The density estimation problem is discussed in detail, together with
graphical techniques for visualizing densities, in
Chap. III.4.
Acknowledgements.
This work was supported by National Science Foundation Grant
DMS 0306202.
Next: References
Up: 5. Smoothing: Local Regression
Previous: 5.4 Statistics for Linear