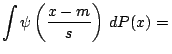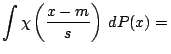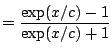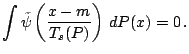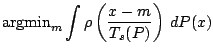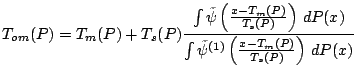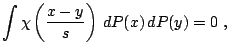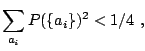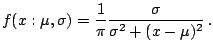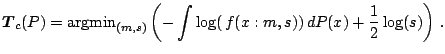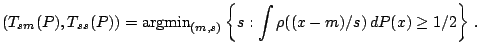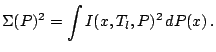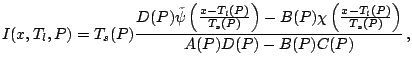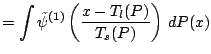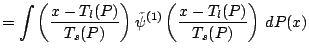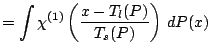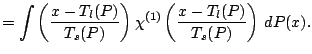Changes in measurement units and baseline correspond to affine
transformations on
![]() . We write
. We write
The fact that the mean ![]() of (9.7) cannot be defined for
all distributions is an indication of its lack of
robustness. More precisely the functional
of (9.7) cannot be defined for
all distributions is an indication of its lack of
robustness. More precisely the functional ![]() is not locally
bounded (9.11) in the metric
is not locally
bounded (9.11) in the metric ![]() at any distribution
at any distribution ![]() .
The median MED
.
The median MED![]() can be defined at any distribution
can be defined at any distribution
![]() as the mid-point of the interval of
as the mid-point of the interval of ![]() -values for which
-values for which
An important family of statistical functionals is the family of
M-functionals introduced by [56] Let ![]() and
and ![]() be
functions defined on
be
functions defined on
![]() with values in the interval
with values in the interval
![]() . For a given probability distribution
. For a given probability distribution ![]() we consider the
following two equations for
we consider the
following two equations for ![]() and
and ![]()
In order to guarantee existence and uniqueness conditions have to be
placed on the functions ![]() and
and ![]() as well as on the
probability measure
as well as on the
probability measure ![]() . The ones we use are due to
[99] (see also [58])
and are as follows:
. The ones we use are due to
[99] (see also [58])
and are as follows:
| (
|
|
| (
|
|
| (
|
|
| (
|
|
| (
|
|
| (
|
|
| (
|
|
| (
|
|
| (
|
|
| (
|
|
If these conditions hold and ![]() satisfies
satisfies
The main disadvantage of M-functionals defined by
(9.21) and (9.22) is (
![]() ) which
links the location and scale parts in a manner which may not be
desirable. In particular there is a conflict between the
breakdown behaviour and the
efficiency of the M-functional (see below). There are several ways of
overcoming this. One is to take the scale function
) which
links the location and scale parts in a manner which may not be
desirable. In particular there is a conflict between the
breakdown behaviour and the
efficiency of the M-functional (see below). There are several ways of
overcoming this. One is to take the scale function ![]() and then to
calculate a second location functional by solving
and then to
calculate a second location functional by solving
In some situations there is an interest in downweighting
outlying observations completely rather than in
just bounding their effect. A downweighting to zero is not
possible for a ![]() -function which satisfies (
-function which satisfies (
![]() ) but
can be achieved by using so called redescending
) but
can be achieved by using so called redescending ![]() -functions such as
Tukey's biweight
-functions such as
Tukey's biweight
So far all scale functionals have been defined in terms of
a deviation from a location functional. This link can be broken as follows.
Consider the functional ![]() defined to be the solution
defined to be the solution ![]() of
of
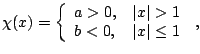 |
Although we have defined ![]() -functionals as a solution of
(9.21) and (9.22) there are sometimes advantages in
defining them as a solution of a minimization problem. Consider
the Cauchy distribution with density
-functionals as a solution of
(9.21) and (9.22) there are sometimes advantages in
defining them as a solution of a minimization problem. Consider
the Cauchy distribution with density
Another class of functionals defined by a minimization problem is
the class of ![]() -functionals. Given
a function
-functionals. Given
a function
![]() which is symmetric,
continuous on the right and non-increasing on
which is symmetric,
continuous on the right and non-increasing on
![]() with
with
![]() and
and
![]() . We define
. We define
![]() by
by
Given a location functional ![]() the bias is defined by
the bias is defined by
The breakdown point
![]() of
of ![]() at
at ![]() with respect to
with respect to
![]() is defined by
is defined by
For location and scale functionals there exist upper bounds for
the breakdown points. For location functionals ![]() we have
we have
We refer to [58]. It may be shown that all breakdown points of the mean are zero whereas the median
attains the highest
possible breakdown point in each case.The corresponding result for
scale functionals is more complicated. Whereas we
know of no reasonable metric in (9.42) of Theorem
1 which leads to a different upper bound this is not the
case for scale
functionals. [58] shows that for the Kolmogoroff metric ![]() the corresponding upper
bound is
the corresponding upper
bound is ![]() but is
but is ![]() for the gross error neighbourhood. If we replace the Kolmogoroff metric
for the gross error neighbourhood. If we replace the Kolmogoroff metric ![]() by
the standard Kuiper metric
by
the standard Kuiper metric ![]() defined by
defined by
Similarly all breakdown points of the standard deviation are zero but, in contrast to the median, the MAD does not attain the upper bounds of (9.44). We have
The M-functional defined by (9.21) and
(9.22) has a breakdown point
![]() which satisfies
which satisfies
The breakdown point is a simple but often effective measure of the
robustness of a statistical functional. It does not
however take into account the size of the bias. This can be done
by trying to quantify the minimum bias over some neighbourhood of the
distribution ![]() and if possible to identify a functional which attains it. We
formulate this for
and if possible to identify a functional which attains it. We
formulate this for ![]() and consider the
Kolmogoroff ball of radius
and consider the
Kolmogoroff ball of radius ![]() . We have ([58])
. We have ([58])
In other words the median minimizes the bias over any Kolmogoroff
neighbourhood of the normal distribution. This theorem can be
extended to other symmetric distributions and to other situations
(Riedel, 1989a, 1989b). It is more difficult to obtain such
a theorem for scale functionals because
of the lack of a property equivalent to symmetry for location.
Nevertheless some results in this direction have been obtained and
indicate that the length of
the shortest half ![]() of (9.8) has very good bias
properties ([74]).
of (9.8) has very good bias
properties ([74]).
Given a sample
![]() with empirical measure
with empirical measure ![]() we can
calculate a location functional
we can
calculate a location functional ![]() which in some sense describes the location of the sample. Such a point
value is rarely sufficient and in general should be supplemented by
a confidence interval, that is a range of values consistent with the
data. If
which in some sense describes the location of the sample. Such a point
value is rarely sufficient and in general should be supplemented by
a confidence interval, that is a range of values consistent with the
data. If ![]() is differentiable (9.12) and the data are
i.i.d. random variables with distribution
is differentiable (9.12) and the data are
i.i.d. random variables with distribution ![]() then it follows from
(9.3) (see Sect. 9.1.3) that an
asymptotic
then it follows from
(9.3) (see Sect. 9.1.3) that an
asymptotic
![]() -confidence interval for
-confidence interval for ![]() is given by
is given by
The precision of the functional ![]() at the distribution
at the distribution ![]() can be
quantified by the length
can be
quantified by the length
![]() of the
asymptotic confidence interval (9.51). As the only
quantity which depends on
of the
asymptotic confidence interval (9.51). As the only
quantity which depends on ![]() is
is ![]() we see that an increase
in precision is equivalent to reducing the size of
we see that an increase
in precision is equivalent to reducing the size of ![]() . The
question which naturally arises is then that of determining how small
. The
question which naturally arises is then that of determining how small
![]() can be made. A statistical functional which attains this
lower bound is asymptotically optimal and if we denote this lower
bound by
can be made. A statistical functional which attains this
lower bound is asymptotically optimal and if we denote this lower
bound by
![]() , the efficiency of the
functional
, the efficiency of the
functional ![]() can be defined as
can be defined as
![]() . The
efficiency depends on
. The
efficiency depends on ![]() and we must now decide which
and we must now decide which ![]() or indeed
or indeed
![]() s to choose. The arguments given in Sect. 9.1.2 suggest
choosing a
s to choose. The arguments given in Sect. 9.1.2 suggest
choosing a ![]() which maximizes
which maximizes
![]() over a class of
models. This holds for the normal distribution which maximizes
over a class of
models. This holds for the normal distribution which maximizes
![]() over the class of all distributions with a given
variance. For this reason and for simplicity and familiarity we shall
take the normal distribution as the
reference distribution. If a reference distribution is required which
also produces outliers then the
slash distribution is to be preferred
to the Cauchy distribution. We refer
to [19] and the discussion given there.
over the class of all distributions with a given
variance. For this reason and for simplicity and familiarity we shall
take the normal distribution as the
reference distribution. If a reference distribution is required which
also produces outliers then the
slash distribution is to be preferred
to the Cauchy distribution. We refer
to [19] and the discussion given there.
If we consider the M-functionals defined by
(9.24) and (9.25) the efficiency at the normal
distribution is an increasing function of the tuning parameter ![]() . As
the breakdown point is a decreasing function
of
. As
the breakdown point is a decreasing function
of ![]() this would seem to indicate that there is a conflict between
efficiency and breakdown point. This is the case for the
M-functional defined by (9.24) and
(9.25) and is due to the linking of the location and scale
parts of the functional. If this is severed by, for example,
recalculating a location functional as in (9.26) then there is
no longer a conflict between efficiency and breakdown. As however the
efficiency of the location functional increases the more it behaves
like the mean with a corresponding increase in the bias function of
(9.35) and (9.37). The conflict between efficiency and
bias is a real one and gives rise to an optimality
criterion, namely that of minimizing the bias subject to a lower bound
on the efficiency. We refer to [73].
this would seem to indicate that there is a conflict between
efficiency and breakdown point. This is the case for the
M-functional defined by (9.24) and
(9.25) and is due to the linking of the location and scale
parts of the functional. If this is severed by, for example,
recalculating a location functional as in (9.26) then there is
no longer a conflict between efficiency and breakdown. As however the
efficiency of the location functional increases the more it behaves
like the mean with a corresponding increase in the bias function of
(9.35) and (9.37). The conflict between efficiency and
bias is a real one and gives rise to an optimality
criterion, namely that of minimizing the bias subject to a lower bound
on the efficiency. We refer to [73].
One of the main uses of robust
functionals is the labelling of so called outliers
(see [5], [55], [3], [40],
[42], and Simonoff (1984, 1987)). In the data of Table
9.1 the laboratories 1 and 3 are clearly outliers which should be
flagged. The discussion in Sect. 9.1.1 already indicates
that the mean and
standard deviation are not appropriate tools for
the identification of outliers as they themselves are so strongly influenced
by the very outliers they are intended to identify. We now demonstrate this
more precisely. One simple rule is to classify all observations more than
three standard deviations from the mean as outliers. A simple calculation
shows that this rule will fail to identify ![]() arbitrarily large
outliers with the same sign. More generally if all observations more than
arbitrarily large
outliers with the same sign. More generally if all observations more than
![]() standard deviations from the mean are classified as outliers then
this rule will fail to identify a proportion of
standard deviations from the mean are classified as outliers then
this rule will fail to identify a proportion of
![]() outliers
with the same
sign. This is known as the masking effect ([79]) where the outliers mask their presence by distorting the mean
and, more importantly, the standard deviation to such an extent as to
render them useless for the detection of the outliers. One possibility
is to choose a small value of
outliers
with the same
sign. This is known as the masking effect ([79]) where the outliers mask their presence by distorting the mean
and, more importantly, the standard deviation to such an extent as to
render them useless for the detection of the outliers. One possibility
is to choose a small value of ![]() but clearly if
but clearly if ![]() is too
small then some non-outliers will be declared as outliers. In many
cases the main body of the data can be well approximated by a normal
distribution so we now investigate the choice of
is too
small then some non-outliers will be declared as outliers. In many
cases the main body of the data can be well approximated by a normal
distribution so we now investigate the choice of ![]() for samples
of i.i.d. normal random variables. One possibility is to choose
for samples
of i.i.d. normal random variables. One possibility is to choose
![]() dependent on the sample size
dependent on the sample size ![]() so that with probability
say 0.95 no observation will be flagged as an outlier. This leads to
a value of
so that with probability
say 0.95 no observation will be flagged as an outlier. This leads to
a value of ![]() of about
of about
![]() ([29]) and the largest proportion of one-sided outliers
which can be detected is approximately
([29]) and the largest proportion of one-sided outliers
which can be detected is approximately
![]() which
tends to zero with
which
tends to zero with ![]() . It follows that there is no choice of
. It follows that there is no choice of
![]() which can detect say
which can detect say ![]() outliers and at the same time
not falsely flag non-outliers. In order to achieve this the mean
and standard deviation must be replaced by functionals which are
less effected by the outliers. In particular these functionals
should be locally bounded (9.11). Considerations of
asymptotic normality or efficiency are of little relevance here.
Two obvious candidates are the median and
MAD and if we use them
instead of the mean and standard deviation
we are led to the identification rule ([53]) of the form
outliers and at the same time
not falsely flag non-outliers. In order to achieve this the mean
and standard deviation must be replaced by functionals which are
less effected by the outliers. In particular these functionals
should be locally bounded (9.11). Considerations of
asymptotic normality or efficiency are of little relevance here.
Two obvious candidates are the median and
MAD and if we use them
instead of the mean and standard deviation
we are led to the identification rule ([53]) of the form
| (9.61) |
We can now formulate the task of outlier identification for the normal
distribution as follows: For a given sample
![]() which contains at least
which contains at least
![]() i.i.d. observations
distributed according to
i.i.d. observations
distributed according to
![]() , we have to find all those
, we have to find all those ![]() that are located in
that are located in
![]() . The level
. The level ![]() can be
chosen to be dependent on the sample size. If for some
can be
chosen to be dependent on the sample size. If for some
![]() we set
we set
| (9.63) |
To describe the worst case behaviour of an outlier identifier we can
look at the largest
nonidentifiable outlier, which it allows.
From [29] we report some values of this quantity for the Hampel identifier (HAMP) and contrast them with
the corresponding values of a sophisticated high breakdown point outwards testing
identifier (ROS), based on the non-robust mean and standard deviation
([87]; [107]). Both identifiers are standardized by
(9.65) with
![]() . Outliers are then
observations with absolute values greater than
. Outliers are then
observations with absolute values greater than
![]() ,
,
![]() and
and
![]() . For
. For ![]() outliers and
outliers and ![]() the average
sizes of the largest non-detected outlier are 6.68 (HAMP) and 8.77
(ROS), for
the average
sizes of the largest non-detected outlier are 6.68 (HAMP) and 8.77
(ROS), for ![]() outliers and
outliers and ![]() the corresponding values are 4.64
(HAMP) and 5.91 (ROS) and finally for
the corresponding values are 4.64
(HAMP) and 5.91 (ROS) and finally for ![]() outliers and
outliers and ![]() the values
are 5.07 (HAMP) and 9.29 (ROS).
the values
are 5.07 (HAMP) and 9.29 (ROS).