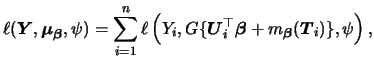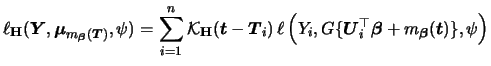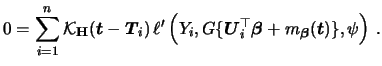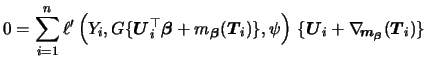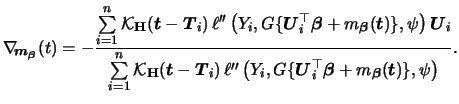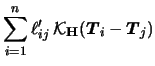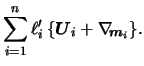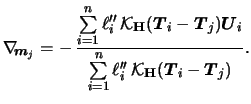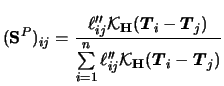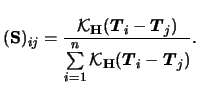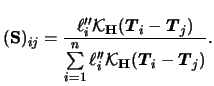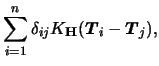In order to estimate the GPLM we consider the same
distributional assumptions for ![]() as in the GLM.
Thus we have
two cases: (a) the distribution of
as in the GLM.
Thus we have
two cases: (a) the distribution of ![]() belongs to the exponential family
(5.13), or
(b) the first two (conditional) moments of
belongs to the exponential family
(5.13), or
(b) the first two (conditional) moments of ![]() are specified in order
to use the quasi-likelihood function (5.18).
are specified in order
to use the quasi-likelihood function (5.18).
To summarize, the estimation of the GPLM will be based
on
The estimation procedures for
![]() and
and ![]() can be classified
into two categories.
can be classified
into two categories.
The profile likelihood method (considered in
Severini & Wong (1992) for this type of problems)
is based on the fact, that the conditional distribution
of ![]() given
given
![]() and
and
![]() is parametric.
This method starts from keeping
is parametric.
This method starts from keeping
![]() fixed and to estimate a least favorable (in other words a
``worst case'') nonparametric function
fixed and to estimate a least favorable (in other words a
``worst case'') nonparametric function
![]() in dependence of the
fixed
in dependence of the
fixed
![]() .
The resulting estimate for
.
The resulting estimate for
![]() is then used
to construct the profile likelihood
for
is then used
to construct the profile likelihood
for
![]() .
As a consequence the resulting
.
As a consequence the resulting
![]() is estimated at
is estimated at ![]() -rate, has
an asymptotic normal distribution and is asymptotically
efficient (i.e. has asymptotically minimum variance). The
nonparametric function
-rate, has
an asymptotic normal distribution and is asymptotically
efficient (i.e. has asymptotically minimum variance). The
nonparametric function ![]() can be estimated consistently by
can be estimated consistently by
![]() .
.
The profile likelihood algorithm can be derived as follows. As explained above
we first fix
![]() and construct the least favorable curve
and construct the least favorable curve
![]() .
The parametric (profile) likelihood function is given by
.
The parametric (profile) likelihood function is given by
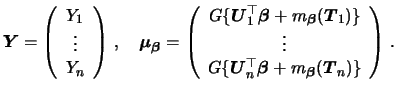
Denote by ![]() ,
, ![]() the first and second derivatives of
the
the first and second derivatives of
the
![]() w.r.t. its second argument.
The maximization of the local likelihood (7.8)
at all observations
w.r.t. its second argument.
The maximization of the local likelihood (7.8)
at all observations
![]() requires hence to solve
requires hence to solve
In general, equations (7.9) and (7.10) can only be solved iteratively. Severini & Staniswalis (1994) present a Newton-Raphson type algorithm for this problem. To write the estimation algorithm in a compact form, abbreviate
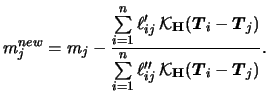
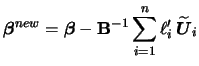
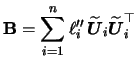
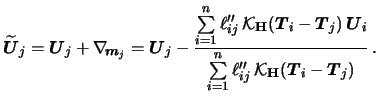
The resulting estimation algorithm consists of iterating the
following update steps for
![]() and
and ![]() up to convergence.
The updating step for
up to convergence.
The updating step for ![]() (the nonparametric part)
is in general of quite complex structure and cannot be simplified.
(Only in some models, in particular for identity and exponential
link functions
(the nonparametric part)
is in general of quite complex structure and cannot be simplified.
(Only in some models, in particular for identity and exponential
link functions ![]() , equation (7.12) can be solved explicitly for
, equation (7.12) can be solved explicitly for
![]() ). It is possible however, to rewrite the updating step for
). It is possible however, to rewrite the updating step for
![]() in a closed matrix form.
Define
in a closed matrix form.
Define
![]() a smoother matrix with elements
a smoother matrix with elements

The profile likelihood estimator is particularly easy to derive
in the case of a PLM, i.e. in particular for the identity link ![]() and normally distributed
and normally distributed ![]() . Here we have
. Here we have
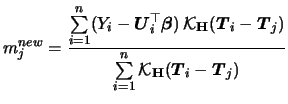

Now consider the GPLM. We are going to combine the Speckman estimators with the IRLS technique for the GLM (cf. (5.23)). Recall that each iteration step of a GLM was obtained by weighted least squares regression on the adjusted dependent variable. In the same spirit, we estimate the GPLM by replacing the IRLS with a weighted partial linear fit on the adjusted dependent variable. This variable is here given as
As for (7.15) we have to introduce weights
for the GPLM smoother matrix. The basic simplification
in comparison to (7.15) is that we use the
matrix
![]() with elements
with elements
Using the notation
![]() and
and
![]() (define
(define
![]() and
and
![]() as before), an expression for each iteration
step in matrix notation is possible
here, too:
as before), an expression for each iteration
step in matrix notation is possible
here, too:

There is an important property that this algorithm shares
with the backfitting procedure we consider in the next
subsection. The updating step for
![]() implies
implies
The backfitting method was originally suggested as an iterative algorithm for fitting an additive model (Buja et al., 1989; Hastie & Tibshirani, 1990). Its key idea is to regress the additive components separately on partial residuals.
Again, let us first consider the PLM

We will now extend this technique to the GPLM.
The motivation for the backfitting iteration coincides with that
for the Speckman iteration.
Again we
recognize the only difference to Speckman in the
updating step for the parametric part. The matrices
![]() and
and
![]() as well as the vector
as well as the vector
![]() are defined in exactly the same way as
for the Speckman iteration.
are defined in exactly the same way as
for the Speckman iteration.

It is easy to see that the backfitting algorithm implies a linear estimation matrix for updating the index, too. We have
An important caveat of the so defined backfitting procedure is that it may fail with correlated explanatory variables. Hastie & Tibshirani (1990, p. 124ff.) therefore propose a modification of the algorithm (``modified backfitting'', which first searches for a (parametric) solution and only fits the remaining parts nonparametrically. We will introduce this modification later on in Chapter 8.
Whereas the PLM estimators are directly applicable, all presented algorithms for GPLM are iterative and therefore require an initialization step. Different strategies to initialize the iterative algorithm are possible:
The essential difference between the profile likelihood and
the Speckman algorithm lies in the fact that the former uses
![]() and
and ![]() instead of
instead of
![]() and
and
![]() .
Thus, both algorithms
produce very similar results, when the bandwidth
.
Thus, both algorithms
produce very similar results, when the bandwidth
![]() is small or when
is small or when
![]() is relatively constant or small
with respect to the parametric part. Müller (2001) points out
that both estimators very often resemble each other.
The comparison of the estimation algorithms can be summarized as follows:
is relatively constant or small
with respect to the parametric part. Müller (2001) points out
that both estimators very often resemble each other.
The comparison of the estimation algorithms can be summarized as follows:
| Yes | No | (in %) | |||
| MIGRATION INTENTION | 39.9 | 60.1 | |||
| FAMILY/FRIENDS IN WEST | 88.8 | 11.2 | |||
| UNEMPLOYED/JOB LOSS CERTAIN | 21.1 | 78.9 | |||
| CITY SIZE 10,000-100,000 | 35.8 | 64.2 | |||
| FEMALE | 50.2 | 49.8 | |||
| Min | Max | Mean | S.D. | ||
| AGE (in years) | 18 | 65 | 39.93 | 12.89 | |
| HOUSEHOLD INCOME (in DM) | 400 | 4000 | 2262.22 | 769.82 |
For illustration purposes we restrict ourselves to considering
only one continuous variable (household income) for the
nonparametric part. Table 7.2 shows on
the left the coefficients of the parametric logit fit.
The estimated coefficients
for the parametric part of the GPLM are given on the right side of
Table 7.2.
For easier assessment of the coefficients, both continuous variables
(age, household income) have been linearly transformed to ![]() .
We see that the migration intention is definitely
determined by age (
.
We see that the migration intention is definitely
determined by age (![]() ). However, the coefficients
of unemployment (
). However, the coefficients
of unemployment (![]() ), city size (
), city size (![]() ) and
household income (
) and
household income (![]() ) variables are also highly significant.
) variables are also highly significant.
| Modified | |||||
| Logit ( |
Profile | Speckman | Backfitting | Backfitting | |
| const. | -0.358 (-0.68) | -- | -- | -- | -- |
| 0.589 ( 1.54) | 0.600 ( 1.56) | 0.599 ( 1.56) | 0.395 | 0.595 | |
| 0.780 ( 2.81) | 0.800 ( 2.87) | 0.794 ( 2.85) | 0.765 | 0.779 | |
| 0.822 ( 3.39) | 0.842 ( 3.47) | 0.836 ( 3.45) | 0.784 | 0.815 | |
| -0.388 (-1.68) | -0.402 (-1.73) | -0.400 (-1.72) | -0.438 | -0.394 | |
| -3.364 (-6.92) | -3.329 (-6.86) | -3.313 (-6.84) | -3.468 | -3.334 | |
| 1.084 ( 1.90) | -- | -- | -- | -- | |
| Linear (GLM) | Part. Linear (GPLM) | ||||
![\includegraphics[width=1.2\defpicwidth]{SPMmigmv.ps}](spmhtmlimg2121.gif)
|
The nonparametric estimate
![]() in this example
seems to be an obvious nonlinear function, see Figure 7.1.
As already observed in the simulations, both profile likelihood methods
give very similar results. Also the nonparametric
curves from backfitting and modified backfitting
do not differ much from those of the profile likelihood approaches.
The reason is the very similar smoothing step in all four methods. We show
therefore only a plot of the curves obtained from the generalized Speckman
algorithm.
in this example
seems to be an obvious nonlinear function, see Figure 7.1.
As already observed in the simulations, both profile likelihood methods
give very similar results. Also the nonparametric
curves from backfitting and modified backfitting
do not differ much from those of the profile likelihood approaches.
The reason is the very similar smoothing step in all four methods. We show
therefore only a plot of the curves obtained from the generalized Speckman
algorithm.
Table 7.2 shows on the right hand side the parameter estimates
for all semiparametric estimates. For the generalized Speckman method, the
matrix
![]() with
with
![]() and
and
![]() from the
last iteration can be used as an estimate for the covariance matrix of
from the
last iteration can be used as an estimate for the covariance matrix of
![]() .
We present the calculated
.
We present the calculated
![]() -values from this matrix. Note that
-values from this matrix. Note that ![]() for binary
for binary
![]() , so we omit this factor here.
An analogous approach is possible for the profile likelihood method,
see Severini & Staniswalis (1994). Here
we can estimate the covariance of
, so we omit this factor here.
An analogous approach is possible for the profile likelihood method,
see Severini & Staniswalis (1994). Here
we can estimate the covariance of
![]() by
by
![]() ,
now using the appropriate
smoother matrix
,
now using the appropriate
smoother matrix
![]() instead of
instead of
![]() .
.
The obvious difference between backfitting and the other procedures
in the estimated effect of ![]() is an interesting observation. It is most likely due to the multivariate
dependence structure within the explanatory variables, an effect
which is not easily reflected in simulations. The profile likelihood
methods have by construction a similar correction ability
for concurvity as the modified backfitting has.
is an interesting observation. It is most likely due to the multivariate
dependence structure within the explanatory variables, an effect
which is not easily reflected in simulations. The profile likelihood
methods have by construction a similar correction ability
for concurvity as the modified backfitting has. ![]()